
震撼升级!这款开源项目打通了 AI 应用的最后一公里
在工业级深度学习实践领域中,我们经常能听到一种说法——模型部署是打通 AI 应用的最后一公里!想要走通这一公里,就好比打赢得一场焦灼篮球赛,困难重重,相信广大开发者们对此一定深有体会。
部署环境复杂多样,比如硬件适配状态、操作系统兼容性、对编程语言的支持等诸多挑战,都宛如一个个勇猛的对手横亘在面前。想要赢得比赛,咱们自己也要多拿分才行。确保环境适配仅是第一步,如何在部署后展示出犀利的性能,实现工业级的高性能推理,同样是胜利的关键因素!开发者们只有“能攻善守”,化身为曾经夺得“得分王”和“最佳防守球员”的乔丹大神,才能顺利部署、尽展性能!如果再有菲尔·杰克逊般全方位、高质量的技术指导,想来“球员们”赢得这场深度学习实践的“比赛”,就不用再吟“蜀道难”了!

别着急,Paddle Inference 前来保驾!近期,Paddle Inference 随着飞桨框架震撼升级到了 2.0 版本!!!此次,全团队秃头 改版升级,让 Paddle Inference 全方位适配各种应用场景,并且在性能方面更上一层楼,同时还配套了详尽的指导文档,助力各位“球员”一举成为部署领域的“乔丹”!
改版升级,让 Paddle Inference 全方位适配各种应用场景,并且在性能方面更上一层楼,同时还配套了详尽的指导文档,助力各位“球员”一举成为部署领域的“乔丹”!
快速变身传送门:
https://paddle-inference.readthedocs.io/en/latest/user_guides/download_lib.html#windows
https://paddle-inference.readthedocs.io/en/latest/user_guides/download_lib.html#
在这边很多小伙伴会问: 什么是 Paddle Inference 原生高性能推理库? 跟主框架的 API 如 model.predict() 等接口又是什么关系呢?哪个更原生些? 在这边给大家快速地科普一下:主框架的前向 API 接口 model.predict() 是基于主框架的前向算子进行封装,且直接调用训练好的模型之前向参数,能够快速测试训练完成的模型效果,并将计算后的预测结果返回呈现,通常是用在验证训练成果及做实验时使用。
而一般的企业级部署通常会追求更极致的部署性能,且希望能够在生产环境安装一个不包含后向算子,比主框架更轻量的预测库,Paddle Inference 应运而生。Paddle Inference 提取了主框架的前向算子,可以无缝支持所有主框架训练好的模型,且通过内存复用、算子融合等大量优化手段,并整合了主流的硬件加速库如 Intel 的 oneDNN、NVIDIA 的 TensorRT 等, 提供用户最极致的部署性能。此外还封装 C/C++ 的预测接口,使生产环境更便利多样。

超强防守!
全方位适配各种应用场景
打篮球时 ,想要有好的防守效果,需要球员压低身形,这样即使抢不到球也可以随时回防,眼睛也一定要紧盯对方手中的球。从中我们可以发现,哪怕是一个简单的防守动作,也需要调动全身的力量。深度学习亦然,从获取预训练模型,到使用特定语言的 API 加载模型、编写推理逻辑,最后在特定的硬件与操作系统上执行推理,这一全套流程需要推理引擎提供从上游到下游的全方位适配与服务。
,想要有好的防守效果,需要球员压低身形,这样即使抢不到球也可以随时回防,眼睛也一定要紧盯对方手中的球。从中我们可以发现,哪怕是一个简单的防守动作,也需要调动全身的力量。深度学习亦然,从获取预训练模型,到使用特定语言的 API 加载模型、编写推理逻辑,最后在特定的硬件与操作系统上执行推理,这一全套流程需要推理引擎提供从上游到下游的全方位适配与服务。
为此 Paddle Inference 依托飞桨框架 2.0 进行了全面升级:
适配多种硬件:深度适配 X86 CPU、NVIDIA GPU(包括 NVIDIA Jetson系列),内置 Intel、NVIDIA 共同打造的高性能 Kernel,保证了推理的高性能执行。此外,飞桨对国产硬件适配一直处于业内领先地位,飞桨人也一直致力于推动自主可控AI软硬件整体解决方案建设。目前,我们已在申威、飞腾、鲲鹏、兆芯、龙芯、海光等国产硬件下测试了 ResNet50、MobileNetV1、ERNIE、ELmo 等经典模型。
兼容多种操作系统:在这一方面,我们还是一如既往的优秀,不仅兼容 Linux、Mac 和 Windows系统,还与 UOS、麒麟等国产操作系统打通。支持所有飞桨训练产出的模型,完全做到即训即用。
支持多种编程语言:支持 C++、Python、C、Go 和 R 语言 API,并全面升级了 C++ API,对规范命名、简化使用方法等进行了优化。同时,我们为以上语言提供了配套的教程、API 文档或示例,降低学习成本,提升易用性。对于其它语言,我们提供了 ABI 稳定的 C API,方便用户扩展。
Paddle Inference 的适配大法虽好,却不要忽略它的高性能哦!我们脱发不脱单,只为让在座的各位满意和惊喜~
最佳进攻!
高性能的推理引擎

推理延时太高,吞吐量太低,内存显存占用太高,都宛如是一个个难缠的对手,让我们难以提升“投篮命中率”,达不到应用需求,“怎么办”三个字显现在光亮的脑门儿上。没关系!Paddle Inference 采用了高性能的底层实现,针对推理场景进行了专门的优化:
内存/显存复用提升服务吞吐量:在推理初始化阶段进行依赖分析,将两两互不依赖的 Tensor 在内存/显存空间上进行复用,增大计算并行量,并提升了服务吞吐量。
细粒度OP横向纵向融合减少计算量:在推理初始化阶段,将模型中的多个OP进行融合,减少计算量与 Kernel Launch 的次数,提升推理性能。
集成高性能推理加速引擎:Paddle Inference 集成了 TenorRT GPU 推理加速引擎和 oneDNN(原MKLDNN)CPU 推理加速引擎。在 2.0 版本中,Paddle Inference对TensorRT与oneDNN的集成进行了优化升级,使 ERNIE、GRU、BERT、GoogleNet 等模型在 TensorRT/oneDNN 上的性能有所提升。
支持加载 PaddleSlim 量化压缩后的模型:Paddle Inference 2.0 增强了对 PaddleSlim 量化模型的支持,涵盖检测、分类、分割等多个任务。
话不多说,数据说话!下图展示了飞桨与其它主流深度学习框架在基准模型上的测试对比数据,共 9 组对比测试。Paddle Inference 在 6 项测试中,性能表现最优。
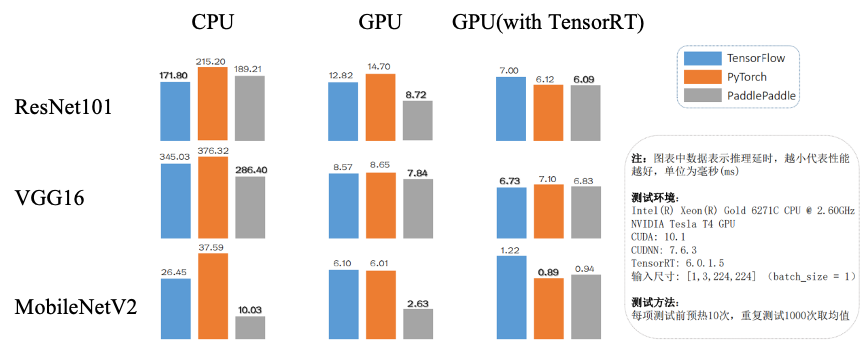
然而,性能很好,在开发实践中不好用该怎么办呢?就比如,很多开发者在使用 TensorRT 加速模型推理的过程中,都有可能遇到过一些困扰。使用 Paddle Inference 之前,各位“球员”可能需要将手头的模型进行格式转换,才可以用 TensorRT 加载。或者,模型中可能存在不支持转换的 OP,无法运行。
又或许,想使用 TensorRT 框架集成版的推理引擎,却苦于操作复杂,资料不全,无从下手。现在,使用 Paddle Inference,无需进行额外的模型转换等操作,只需添加一行代码即可开启 TensorRT 优化加速功能,关键代码如下:

是不是想给我们鼓个掌 ,甚至还想让我们叉会儿腰?像我们这种人狠话不多、头发不几根的团队,只想让各位“球员”获得更好的产品体验,因此,我们还提供了超全、超详细的技术支持,让我们接着往下看吧~
,甚至还想让我们叉会儿腰?像我们这种人狠话不多、头发不几根的团队,只想让各位“球员”获得更好的产品体验,因此,我们还提供了超全、超详细的技术支持,让我们接着往下看吧~

最贴心的教练服务!
细致全面的技术支持
虽然我们已经进入了万物互联的新时代,自学并不像以往那么艰难,但是没有资源、没有教程、没有手把手地辅导,都可能让大家随时“从入门到放弃”。相信大家在学习部署时,都有如下心路历程:
想要下载符合需求的预编译库 → 找不到官方资源 → 放弃...
想要使用C++/Go API部署模型 → 找不到全面的API文档 → 放弃...
想要在NV Jetson/Windows上部署模型 → 找不到针对各种硬件/操作系统的指导 → 放弃...
想要开启TensorRT功能/部署INT8量化模型 → 找不到针对性的教程 → 放弃...
想要通过示例代码在实践中学习 → 找不到丰富的Demo资源 → 放弃...

没关系!Paddle Inference 2.0对教程文档和示例代码进行了全面的升级,还对各种硬件设备、操作系统、功能特性、多语言API进行了全方位的保姆式技术支持,贴心的“教练服务”让您不再挠头,方便快捷地实现高性能部署!

您可以在我们的官方教程页面了解以上内容。说出您想使用的硬件设备、语言接口和功能,即可享受从环境搭建、使用流程、功能特性实战到示例代码实践的全套技术支持服务。除此以外,飞桨还实现了即拿即用的模型服务,例如 PaddleHub 预训练模型工具、PaddleDetection 和 PaddleOCR 等开发套件、PaddleCV 和 PaddleNLP 等模型库,为您提供了覆盖各个应用场景的模型服务,可以让您放肆地做一次“伸手党”!等等,如果您手头只有其它框架的模型怎么办?没关系,X2Paddle 模型转换工具帮您实现无缝切换,欲知详情,请参考如下链接:
https://github.com/PaddlePaddle/X2Paddle
说了这么多,各位“球员”是不是跃跃欲试,想体验 Paddle Inference 2.0 高效流畅的模型部署,在深度学习的“赛场”上尽显风姿了呢?体贴入微的我们,还为大家提供了端到端的部署流程,即刻成为耀眼“球星”:
准备模型
Paddle Inference 原生支持由 飞桨深度学习框架训练产出的推理模型。飞桨新版本中用于推理的模型分别通过 paddle.jit.save (动态图)与 paddle.static.save_inference_model(静态图)或 paddle.Model().save (高层API)保存下来。
如果您手中的模型是由诸如 Caffe、Tensorflow、PyTorch 等框架产出,那么您可以使用 X2Paddle 工具将模型转换为 PadddlePaddle 格式。
准备环境
1)Python 环境
请参照 官方主页-快速安装 页面进行自行安装或编译,当前支持 pip/conda 安装,docker镜像以及源码编译等多种方式来准备Paddle Inference开发环境。
2)C++ 环境
Paddle Inference提供了Ubuntu/Windows/MacOS平台的官方Release预测库下载,如果您使用的是以上平台,我们优先推荐您通过以下链接直接下载,或者您也可以参照文档:
https://paddleinference.paddlepaddle.org.cn/user_guides/source_compile.html
进行源码编译。
下载安装Windows预测库:
https://paddle-inference.readthedocs.io/en/latest/user_guides/download_lib.html#windows
下载安装Linux预测库:
https://paddle-inference.readthedocs.io/en/latest/user_guides/download_lib.html#
开发预测程序
开发预测程序只需要简单的5个步骤 (这里以C++ API为例):
1)配置推理选项 paddle_infer::Config,包括设置模型路径、运行设备、开启/关闭计算图优化、使用MKLDNN/TensorRT进行部署的加速等。
2)创建推理引擎 paddle_infer::Predictor,通过调用 CreatePaddlePredictor(Config) 接口,一行代码即可完成引擎初始化,其中 Config 为第1步中生成的配置推理选项。
3)准备输入数据,需要以下几个步骤:
先通过auto input_names = predictor->GetInputNames() 获取模型所有输入Tensor的名称;
再通过 auto tensor = predictor->GetInputTensor(input_names[i]) 获取输入Tensor的指针;
最后通过 tensor->copy_from_cpu(data),将 data 中的数据拷贝到Tensor中。
4)执行预测,只需要运行predictor->Run()一行代码,即可完成预测执行。
5)获得预测结果,需要以下几个步骤:
先通过 auto out_names = predictor->GetOutputNames() 获取模型所有输出Tensor的名称;
再通过 auto tensor = predictor->GetOutputTensor(out_names[i]) 获取输出Tensor的 指针;
最后通过 tensor->copy_to_cpu(data),将Tensor中的数据copy到data指针上。

如果您有疑问或者建议,欢迎扫描下方二维码,添加成功后回复【部署】加入技术交流群 :)
Paddle Inference完整文档:
https://paddle-inference.readthedocs.io/en/latest/index.html
Paddle Inference Demo:
https://github.com/PaddlePaddle/Paddle-Inference-Demo