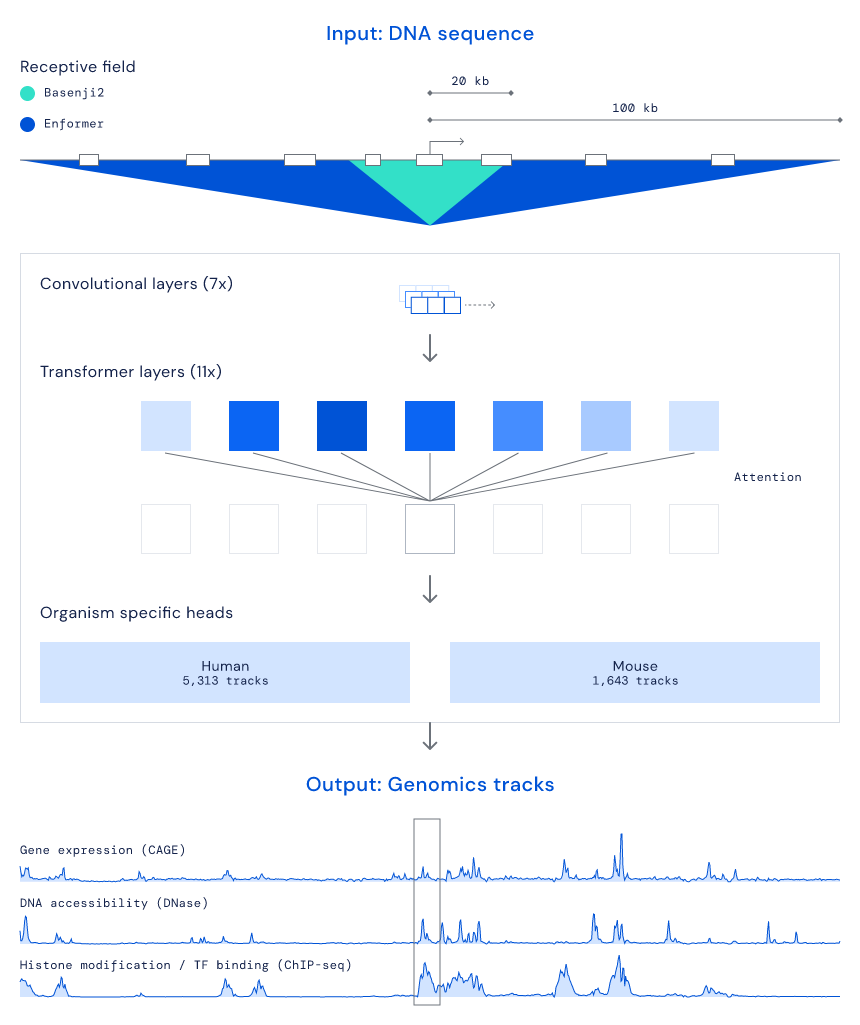
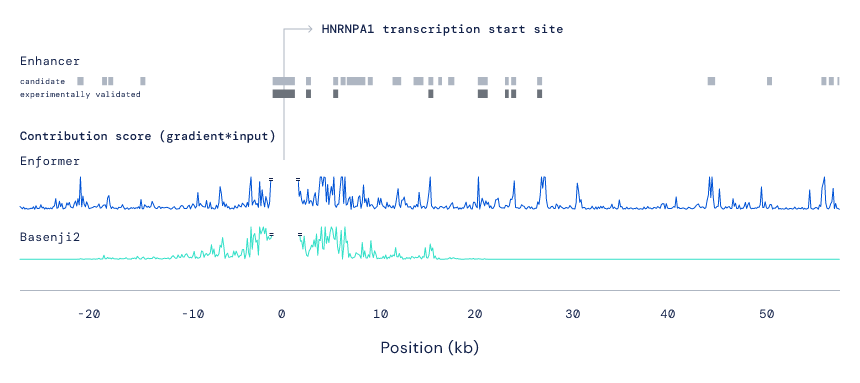
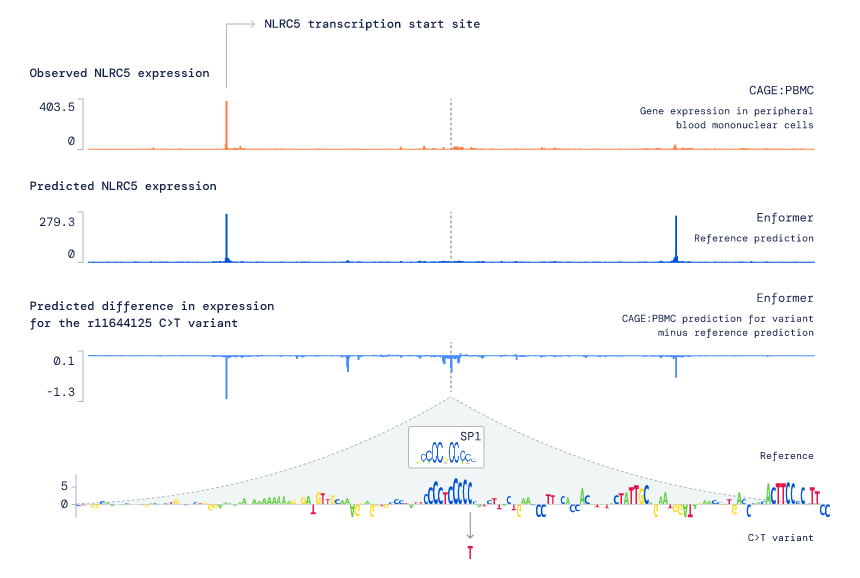
DNA 预测进入新时代!DeepMind 发布新模型Enformer,一次可编码20万个碱基对新智元关注共 2837字,需浏览 6分钟 ·2021-10-12 20:51 新智元报道 来源:deepmind编辑:LRS【新智元导读】DNA 存在大量的片段,破译信息是一个费时费力的工作,能否用AI 的力量来解决这个问题?DeepMind最近发布了一个新模型Enformer,能够一次编码超过20万个碱基对来进行预测,超过以往方法的5倍,准确率大大提升。DNA 一直是生物中最神秘的存在,为了测量DNA 序列,1988年美国国家科学院的一个特别委员提出人类基因组计划(Human Genome Projec, HGP),它是一项规模高,跨国跨学科的科学探索巨型工程。 其宗旨在于测定组成人类染色体(指单倍体)中所包含的六十亿对组成的核苷酸序列,从而绘制人类基因组图谱,并且辨识其载有的基因及其序列,达到破译人类遗传信息的最终目的。 截至2005年,人类基因组计划的测序工作已经基本完成(92%)。2020年突破性技术进展就包括,针对不同人的基因研发的个性化药物、根据基因研发的抗衰老药物等,可以说生物技术的发展离不开基因测序。 国际研究界也对更好地了解影响人类健康和发展的遗传指令的机会感到兴奋。DNA 携带决定一切的遗传信息,从眼睛颜色到对某些疾病的易感性。人体中大约 20,000 个称为基因的 DNA 部分包含有关蛋白质氨基酸序列的说明,这些蛋白质在我们的细胞中执行许多基本功能。 然而,这些基因只占基因组的不到 2%。剩余的碱基对占基因组 30 亿个“字母”中的 98%,被称为非编码(non-coding),包含关于基因应该在人体中何时何地产生或表达的不太容易理解的说明。 DeepMind 始终相信人工智能可以更深入地了解此类复杂领域,可以加速科学进步并为人类健康带来潜在益处,最近他们发表了一篇论文,引入一种称为 Enformer 的神经网络架构,该架构大大提高了从 DNA 序列预测基因表达的准确性。 为了进一步研究疾病中的基因调控和因果因素,DeepMind 还公开提供了模型及其对常见遗传变异的初步预测。 以前关于基因表达的工作通常使用卷积神经网络作为基本构建块,但它们在模拟远端增强子对基因表达的影响方面的局限性阻碍了它们的准确性和应用。 最初的基因探索依赖于 Basenji2,它可以从 40,000 个碱基对的相对较长的 DNA 序列中预测调节活性。受这项工作的启发,以及调控 DNA 元件可以影响更远距离表达的知识,可以改变基本的模型架构改变来捕获长序列。 DeepMind 开发了一种基于 Transformers 的新模型,Transformer在自然语言处理中很常见,可以利用可以整合更多 DNA 上下文的自我注意机制。 由于 Transformers 是查看长文本段落的理想选择,因此DeepMind 对它们进行了改造,以读取大量扩展的 DNA 序列。 通过有效地处理序列,新模型能够比先前方法编码长度超过 5 倍(即 200,000 个碱基对)的距离的相互作用,并且模型架构可以模拟称为增强子(enhancer)的重要调控元件对 DNA 序列中更远距离的基因表达的影响。 Enformer 被训练来预测功能基因组数据,包括来自输入 DNA 的 200,000 个碱基对的基因表达。上面的示例包含 5,000 多个可能的基因组轨迹中的三个。通过使用使用注意力收集整个序列的信息的Transformer 模块,与以前的模型相比,能够更有效地考虑更长的输入序列。 为了更好地理解 Enformer 如何解释 DNA 序列以得出更准确的预测,研究人员使用贡献分数来突出输入序列的哪些部分对预测影响最大。与生物学直觉相匹配,可以观察到,即使位于距离基因超过 50,000 个碱基对的位置,该模型也会关注增强子。 预测哪些增强子调节哪些基因仍然是基因组学中尚未解决的主要问题,因此目前来看 Enformer 的贡献分数只能与专门为此任务开发的现有方法(使用实验数据作为输入)相当。 Enformer 还学习到了绝缘体元件(insulator elements),它将 DNA 的两个独立调节区域分开。 虽然现在可以完整地研究生物体的 DNA,但需要复杂的实验来了解基因组。尽管进行了巨大的实验努力,但绝大多数 DNA 对基因表达的控制仍然是个谜。 借助人工智能,研究人员可以探索在基因组中寻找模式的新可能性,并提供有关序列变化的机械假设。与拼写检查器类似,Enformer 部分理解 DNA 序列的词汇,因此可以突出显示可能导致基因表达改变的编辑。 这种新模型的主要应用是预测 DNA 字母的哪些变化(也称为遗传变异)会改变基因的表达。 与之前的模型相比,Enformer 在预测变异对基因表达的影响方面要准确得多,无论是在自然遗传变异的情况下,还是在改变重要调控序列的合成变异的情况下。 此属性可用于解释通过全基因组关联研究获得的越来越多的疾病相关变异。与复杂遗传疾病相关的变异主要位于基因组的非编码区域,可能通过改变基因表达导致疾病。 但由于变异之间的内在相关性,许多这些与疾病相关的变异只是假相关而不是因果关系。计算工具现在可以帮助区分真正的关联和误报。 上图显示了位于免疫反应基因 NLRC5 中的变体 rs11644125 与较低水平的单核细胞和淋巴细胞白细胞有关。 通过系统地突变围绕变体的每个位置并预测 NLRC5 基因表达的结果变化(显示为字母高度),可以观察到该变体导致 NLRC5 的整体表达降低并调节称为 SP1 的转录因子的已知结合基序。 因此,Enformer 的预测表明,由于 SP1 结合受到干扰,该变体对白细胞计数的影响背后的生物学机制是降低 NLRC5 基因表达。 当然这项工作远未解决人类基因组中存在的无法解释的难题,但 Enformer 是在理解基因组序列复杂性方面向前迈出的一步。 如果读者有兴趣使用 AI 来探索基本细胞过程的工作原理、它们如何在 DNA 序列中编码,以及如何构建新系统来推进基因组学和对疾病的理解,DeepMind 正在招聘。 参考资料:https://deepmind.com/blog/article/enformer 浏览 44点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 Transformer新作收录Nature子刊!DeepMind提出Enformer:从DNA序列有效预测基因表达病高发区域Python高校0DeepMind 解决蛋白质结构预测难题Python中文社区0长时间预测模型DLinear、NLinear模型机器学习AI算法工程0Kaggle网站流量预测模型Kaggle 是一个网站流量预测项目,项目采用Python语言开发,可以给大家的流量预测建模提供一些实战案例|销量预测模型俊红的数据分析之路0MIT设计深度学习框架登Nature封面,预测非编码区DNA突变数据派THU0Kaggle网站流量预测模型Kaggle是一个网站流量预测项目,项目采用Python语言开发,可以给大家的流量预测建模提供一些思路。数据模型Kaggle的训练数据集由大约14.5万套时间序列组成,每一套时间序列代表的是每天不同维新冠疫情预测模型--逻辑斯蒂回归拟合、SEIR模型机器学习AI算法工程0起飞!DeepMind新模型借助Transformer自动生成CAD草图七月在线实验室0用Tableau做销量预测模型接地气学堂0点赞 评论 收藏 分享 手机扫一扫分享分享 举报




 下载APP
下载APP