
Transformer新作收录Nature子刊!DeepMind提出Enformer:从DNA序列有效预测基因表达病高发区域
更多内容、请置顶或星标
作者:Žiga Avsec | 转载自:机器之心
继蛋白质结构预测之后,一路领跑的 DeepMind 又将 AI 的触角伸向了 DNA。

论文链接:https://www.nature.com/articles/s41592-021-01252-x.pdf
项目链接:https://github.com/deepmind/deepmind-research/tree/master/enformer
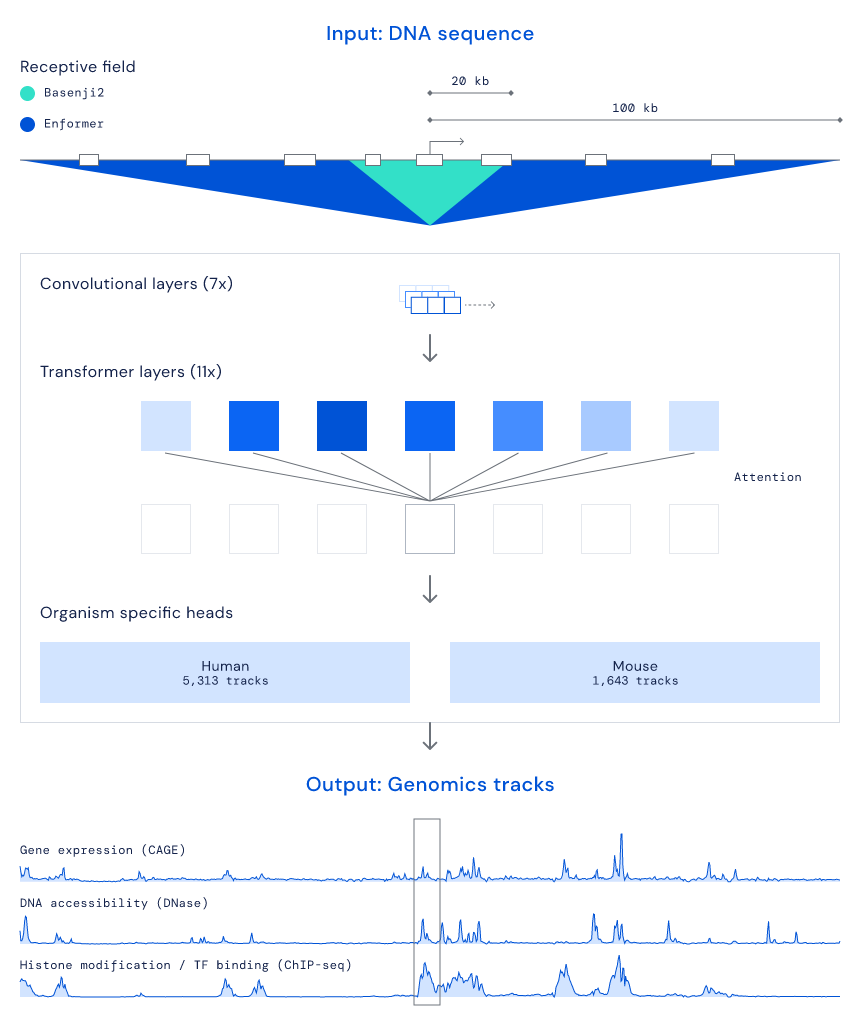
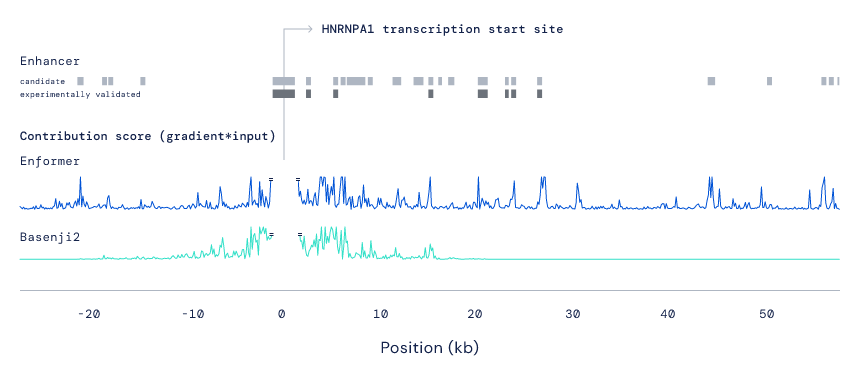
— END —
想要了解更多资讯
点这里👇关注我,记得标星呀~
请点击上方卡片,专注计算机人工智能方向的研究
评论