
美团图神经网络训练框架的实践和探索

1. 前言
1.1 问题和挑战
1.2 美团的解决方案
2. 系统概览
3. 模型框架
3.1 同质图
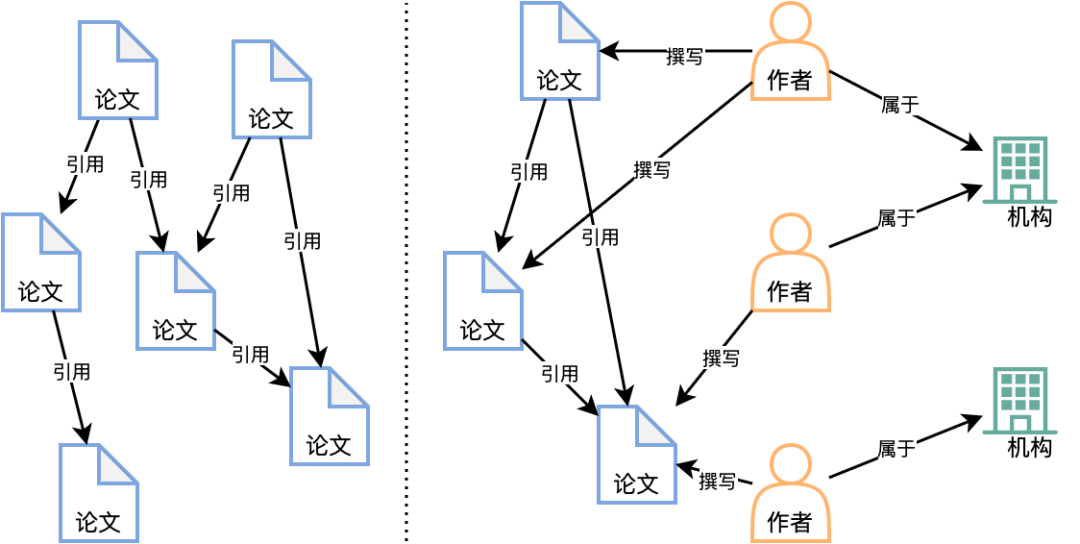
3.2 异质图
3.3 动态图
4. 训练流程框架
5. 性能优化
5.1 图数据结构优化
5.2 子图采样优化
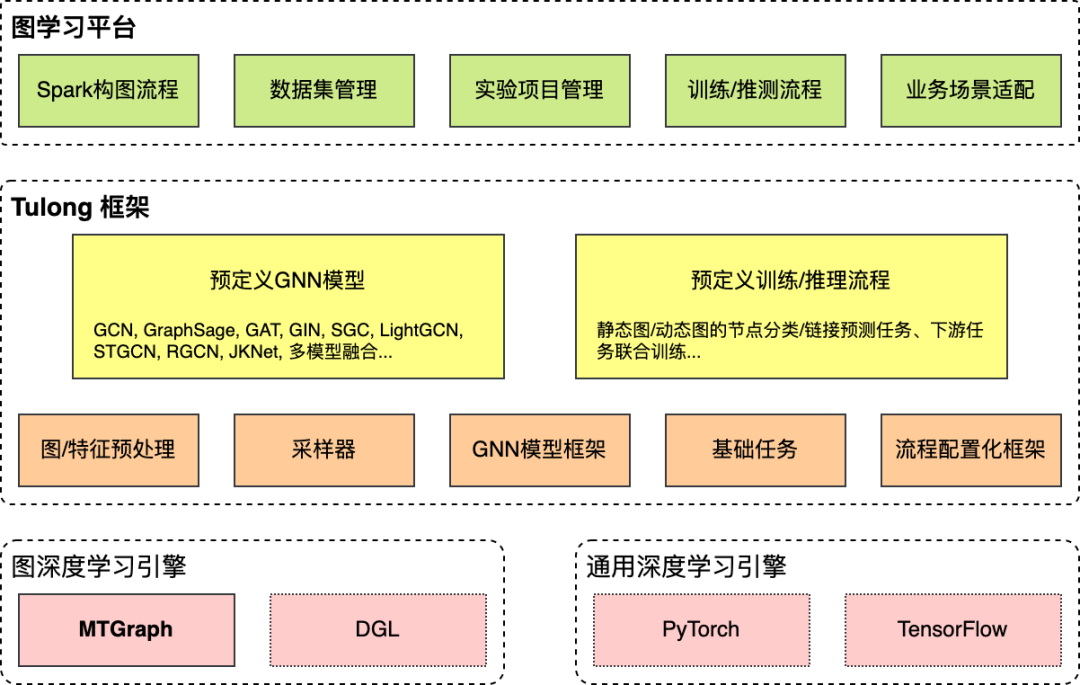
6. 图学习平台
7. 总结
8. 作者简介
9. 参考文献
1. 前言
1.1 问题和挑战
1.2 美团的解决方案
首先,我们对当前流行的图神经网络模型进行了细粒度的剖析,归纳总结出了一系列子操作,实现了一套通用的模型框架。简单修改配置即可实现许多现有的图神经网络模型。 针对基于子图采样的训练方式,我们开发了图计算库“MTGraph”,大幅优化了图数据的内存占用和子图采样速度。单机环境下,相较于DGL训练速度提升约4倍,内存占用降低约60%。单机即可实现十亿节点百亿边规模的训练。 围绕图神经网络框架Tulong,我们构建了一站式的图学习平台,为研发人员提供包括业务数据接入、图数据构建和管理、模型的训练和评测、模型导出上线等全流程的图形化工具。 Tulong实现了高度可配置化的训练和评测,从参数初始化到学习率,从模型结构到损失函数类型,都可以通过一套配置文件来控制。针对业务应用的常见场景,我们总结了若干训练模版,研发人员通过修改配置即可适配多数业务场景。例如,许多业务存在午晚高峰的周期性波动,我们为此设计了周期性动态图的训练模板,可以为一天中不同时段产生不同的GNN表示。在美团配送业务的应用中,需要为每个区域产生不同时段下的GNN表示,作为下游预测任务的输入特征。开发过程中,从开始修改配置到产出初版模型仅花费三天;而在此之前,自行实现类似模型方案花费约两周时间。
2. 系统概览
3. 模型框架
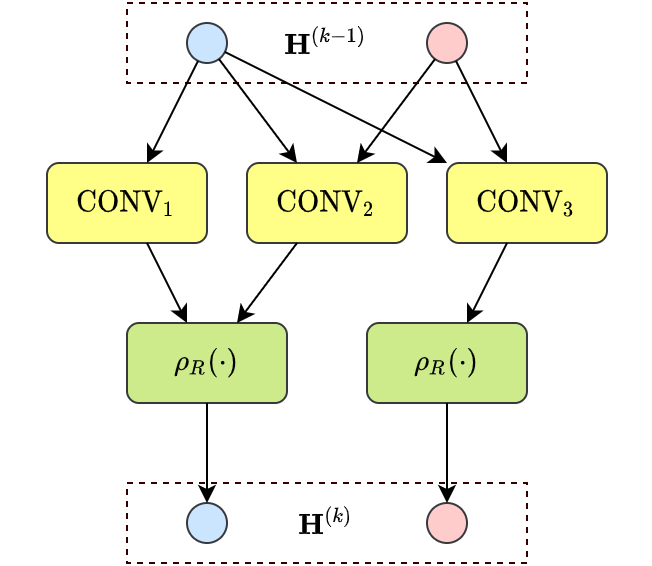
3.1 同质图
我们扩展了聚合函数的种类,提出一种更加通用的计算范式:
上述计算范式仍然分为生成消息、聚合消息、更新当前节点三个步骤,具体包括:
层次维度的聚合函数:用于聚合同一节点在模型不同层次的表示。例如,多数GNN模型中,层次维度的聚合函数为上一层的节点表示;而在JKNet[10]中,层次维度的聚合函数可以设定为LSTM[11]。 消息函数:结合起始节点和目标节点,以及边的特征,生成用于消息传递的消息向量。 节点维度的聚合函数:汇集了来自邻居节点的所有消息向量。值得注意的是,也可以有不同的实现。例如,在GCN中为所有邻居节点,而在GraphSage[9]中为邻居节点的子集。 更新函数:用于聚合节点自身在上一层和当前层的表示。
3.2 异质图
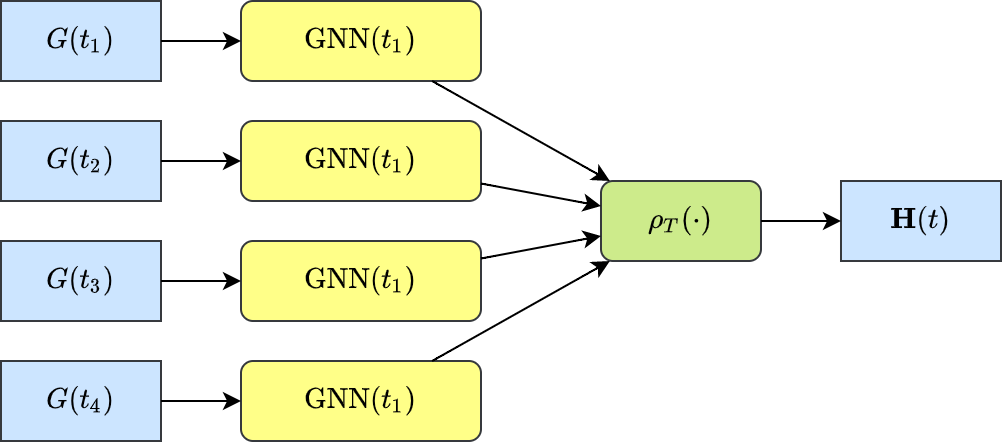
3.3 动态图
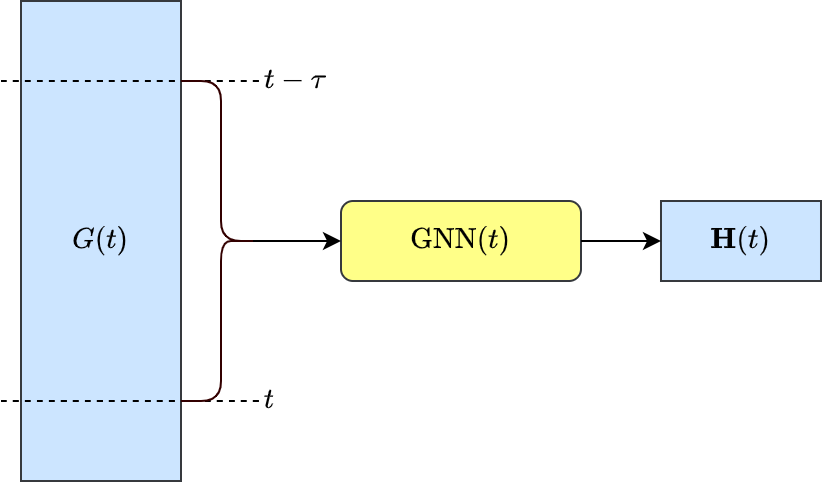
4. 训练流程框架
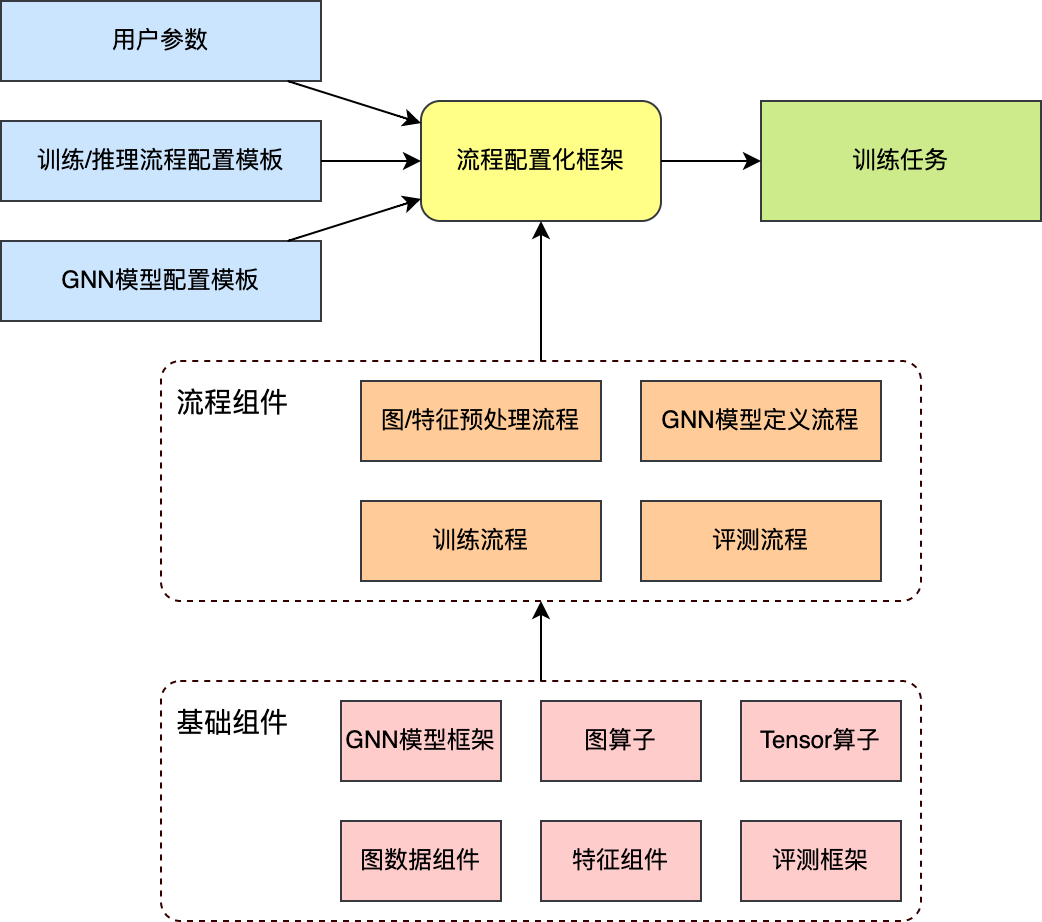
5. 性能优化
5.1 图数据结构优化
图数据预处理和压缩:首先分析图的统计特征,以轻量级的方式对节点进行聚类和重新编号,以期让编号接近的节点在领域结构上也更为相似。随后调整边的顺序,对边数据进行分块和编码,产生“节点-分块索引-邻接边”层次的图数据文件(如下图7所示)。最后,如果数据包含节点特征或边特征,还需要将特征与压缩后的图对齐。

图的随机查询:查询操作分为两步:首先定位所需的边数据块,然后在内存中解压数据块,读取所查询的数据。例如在查询节点和是否相连时,首先根据两个节点的编号计算边数据块的地址,解压数据块后获得少量候选邻接边(通常不多于16条),然后查找是否包含边。

5.2 子图采样优化
随机数发生器:相比于通信加密等应用,图上的采样对于随机数发生器的“随机性”并没有苛刻的要求。我们适当放松了对随机性的要求,设计实现了更快速的随机数发生器,可以直接应用在有放回和无放回的采样操作中。 概率量化:有权重的采样中,在可接受的精度损失下,将浮点数表示的概率值量化为更为紧凑的整型。不仅降低了采样器的内存消耗,也可以将部分浮点数操作转化为整型操作。 时间戳索引:动态图的子图采样操作要求限定边的时间范围。采样器首先对边上的时间戳构建索引,采样时先根据索引确定可采样边的范围,然后再执行实际的采样操作。

6. 图学习平台
数据集管理:从业务数据构造图是模型开发的第一步,图学习平台提供基于Spark的构图功能,可以将Hive中存储的业务数据转化为Tulong自定义的图数据格式。业务数据经常以事件日志的方式存储,如何从中抽象出图,有大量的选择。例如,在推荐场景中,业务日志包含用户对商家的点击和下单记录,除了把"用户-点击-商家"的事件刻画为图以外,还可以考虑刻画短时间内共同点击商家的关系。除此之外,还可以引入额外的数据,比如商家的地理位置、商家在售的菜品等。究竟使用何种构图方案,需要经过实验才能确定。对此,图学习平台提供了图形化的构图工具(如下图10所示),帮助用户梳理构图方案;同时还提供图数据集的版本管理,方便比较不同构图方案的效果。
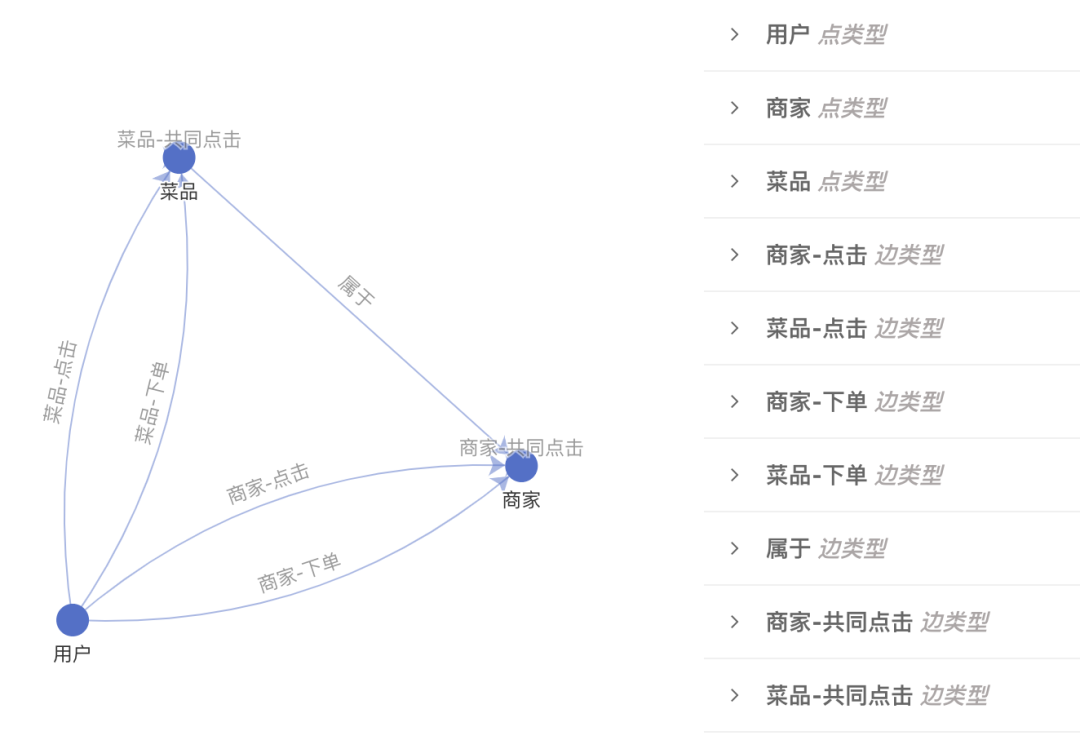
实验管理:确定图数据之后,建模方案和训练策略是影响最终效果的关键。例如,应该用何种GNN模型?损失函数如何选取?模型超参和训练超参如何确定?这些问题也需要经过大量实验才能回答。基于Tulong框架,建模方案和训练策略可以通过一组配置来控制。图学习平台提供配置的可视化编辑器和版本管理功能,方便比较不同的方案的优劣。
流程管理:有了图数据集和建模/训练方案后,还需要让整个流程自动化。这是模型上线的必要条件,同时也有利于团队成员复现彼此的方案。图学习平台针对常见的“构图、训练、评测、导出”流程提供了自动化的调度,在适当的时候可以复用前一阶段的结果,以提升效率。例如,如果数据集的定义没有变化,可以跳过Spark构图阶段直接使用已有的图数据。此外,针对模型上线的需求,平台提供构图和建模方案整合和定时调度等功能。
7. 总结
8. 作者简介
9. 参考文献
推荐阅读:
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)
评论