如今,社会生产资料正以指数增长的速度从白纸印刷向万物互联的网络中迁徙,人们面临着更高的数据处理需求:语音、图片、视频,语言文字、行为……数据本身是没有生命力的,唯有发现与用才赋予它们生机。在 AI 的赋能下,这些形态各异的非结构化数据得以通过向量化的形式被直接检索,向量检索技术成为愈加重要的一环。

3月20日,阿里云开发者社区联合阿里云计算平台事业部、达摩院共同举办的 BIGDATA + AI Meetup · 北京站向量检索专场即将重磅开启!来自阿里云、淘宝、爱奇艺、Zilliz、云从科技、搜狐、Jina.AI 的九位重量级讲师将在现场分享关最前沿的向量检索技术思考与实践,解读向量检索与人脸识别、推荐系统、图片搜索、视频指纹、自然语音处理、文件搜索等各类应用场景交织融合的技术逻辑;更有阿里云达摩院自主研发,并广泛应用于阿里集团各个业务场景的 Proxima 向量检索引擎的对外首次揭秘!无论你是热衷于钻研开源技术的开发者,还是“大数据+AI”的资深爱好者,都能这些前沿的案例从中获得全新的灵感。本次 Meetup 将采取线上线下双线联动的方式,除线下参与外,还将进行同步直播,您可实时观看活动精彩分享。此外,现场还准备了精美社区礼物以及免费茶歇甜点。到场名额有限,不容错过!快快报名吧!
- 阿里云达摩院自主研发的向量检索引擎 Proxima 首次对外揭秘——赋能阿里集团拍立淘、搜索个性化、优酷视频指纹、猜你喜欢、图搜云等多业务场;集成在 Ads、Hologres、Elasticsearch 等云上业务……阿里云达摩院 Proxima 技术负责人将现场带来硬核详解。
- 阿里巴巴高级算法专家为你展示淘系推荐团队 MIND 召回算法的系统架构设计及应用;阿里云团队基于 PAI 可以帮助客户快速搭建个性化推荐解决方案。
- 国内开源向量搜索引擎——Milvus 所属公司 Zilliz 合伙人现身解析应用于各大企业的经典案例。
- “AI四小龙”之一——云从科技数据研究院技术总监分享十年沉淀开发经验,带你领略云从科技大规模人脸比对技术,共话向量计算的未来。
- 还有开源神经搜索公司 Jina AI 创始人兼 CTO 亲自展示 Jina 的设计理念及使用其搭建搭建神经搜索系统的原理;爱奇艺在广告、搜索、视频推荐等业务的向量检索技术最佳实践;搜狐应用 Mlivus 基于语义向量的内容召回和短文本分类的文本标注实战……
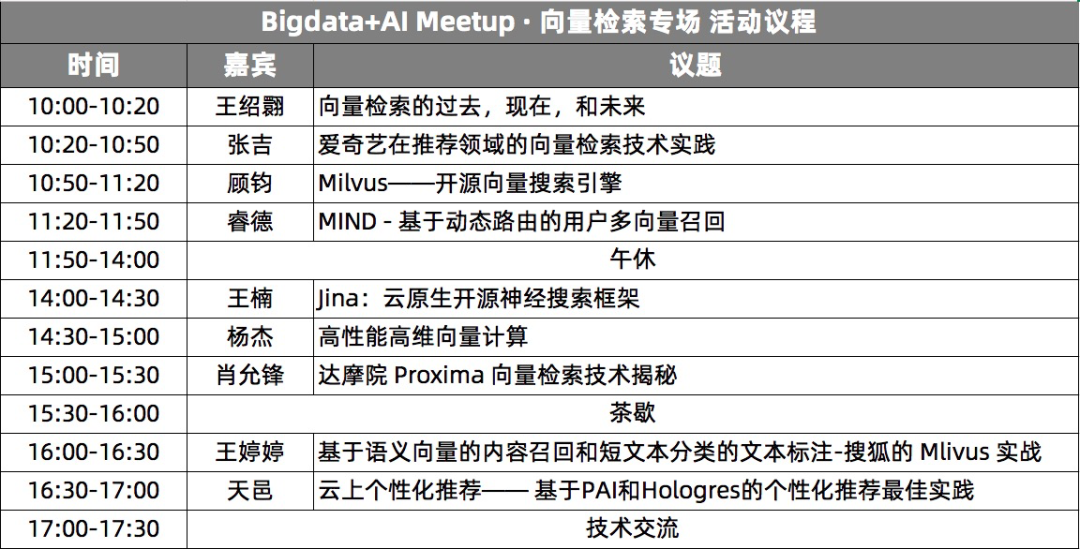
浅谈向量检索的技术背景和应用,揭秘向量检索的核心挑战和未来发展趋势。王绍翾(大沙),达摩院机器智能实验室,资深技术专家。毕业于北京大学,在加州大学获得计算机工程博士学位。毕业后曾在 Facebook 开发分布式图关系数据库 TAO。2015 年加入阿里巴巴集团,先后就职于搜索事业部,计算平台事业部,目前是达摩院机器智能系统AI实验室的负责人,主要负责达摩院的 AI Engineering 的体系建设,包括高性能训练,推理,向量检索等等核心引擎的研发,以及视觉,NLP,决策等算法能力的开放平台建设和商业化落地。在搜索和计算平台事业部,王绍翾主要负责阿里新一代实时计算平台 Blink/Flink 的研发工作,他是国内最早期的 Apache Flink 的 committer 和 PMC。
议题简介:
手淘首页的推荐面临着两个极具挑战性的问题. 一是业务数据量巨大, 包括十亿级的用户和商品; 二是首页开屏即现, 对算法的响应时间有严格要求. 在实际实践中, 我们将推荐系统拆分为召回与排序两个子系统. 其中, 召回系统从海量的候选商品中挑选出与用户兴趣相关的商品集合, 排序系统对该商品集合中的每一个商品依据业务目标进行打分, 打分较高的商品作为推荐结果展示给用户. 推荐算法的效果同时受到两个子系统的影响, 召回作为算法的前置环节, 更是决定了整个系统的效果上限. 本次分享中, 我们将分享 MIND 召回算法及其系统架构设计
睿德, 淘系技术部, 高级算法专家。从事推荐技术召回, 排序算法的开发。淘宝搜索推荐、视频搜索支付背后的检索技术,达摩院向量检索引擎 Proxima 揭秘。Proxima 是阿里巴巴达摩院系统 AI 实验室自研的向量检索内核,广泛应用于阿里巴巴和蚂蚁集团内,为淘宝搜索和推荐、蚂蚁人脸支付、优酷视频搜索、阿里妈妈广告检索等核心业务提供核心检索能力。并深度集成在阿里云 Hologres、搜索引擎 Elastic Search 和 ZSearch、离线引擎 MaxCompute (ODPS) 等大数据和数据库产品中。肖允锋(鹤冲),达摩院资深技术专家。毕业于中山大学物理系。曾就职于电信研究院和腾讯科技,从事大数据搜索技术相关研究和应用十余载,是阿里巴巴达摩院 Proxima AI 检索引擎的总设计者和技术带头人。目前,Proxima 相关技术广泛应用于阿里巴巴和蚂蚁金服各大业务,算法和工程在业内具有一定的领先性。
议题简介:
在推荐算法领域,召回-粗排-精排是成熟稳定的系统方案。而传统过滤/模式匹配的召回算法在个性化、实时、智能推荐的需求上力不从心,对快速增加的各种非数值类特性和海量数据的处理无能为力,同时在线的推理过程对性能又提出了严苛的要求。我们结合 Youtube DNN 等多种向量召回模型与重排序的需求,探索了数种向量检索的服务的技术与产品,结合这些技术 和 Tensorflow Serving,完成广告、搜索、视频推荐等业务在爱奇艺的召回基础服务。
议题简介:
随着信息规模的爆炸式增长和数据类型的日益丰富,基于符号的传统搜索逐渐无法满足用户的需求。得益于深度学习技术的发展,神经搜索系统应运而生。但是,在搭建和维护神经搜索系统的过程中,工程团队不仅需要具备分布式架构的经验,更需要熟悉多个软件框架和理解不同 AI 算法。针对这个痛点,Jina 提供覆盖搜索全链路的一站式云原生开源解决方案。在本次报告中,我们将分享 Jina 的设计思想和主要特点,并展示如何使用 Jina 搭建神经搜索系统。王楠,博士,Jina AI 联合创始人兼 CTO。专注于机器学习和深度学习算法在 NLP 和搜索领域的实际应用。作为开源神经搜索框架 jina 的核心贡献者,热衷于开源软件和云原生技术。
议题简介:
在深度学习流行的当下,向量计算已经成为 AI 工程的基石,无论是人脸比对、图像搜索、推荐、智能问答都涉及到海量高维向量的计算。检索和聚类是其中两个典型的计算场景,面向海量向量的检索通常采用 ANN 一簇算法解决,无监督聚类算法也正在蓬勃发展;除开算法,工程架构上的挑战也是巨大的,比如怎样适配端侧设备、国产芯片等异构计算环境。本次演讲,我们会分享云从在大规模人脸比对领域上的实践心得,探讨向量计算未来的发展方向。 杨杰,云从科技数据研究院技术总监。在云从主要负责 KaaS 平台(向量计算、知识图谱、搜索等技术方向)研发,在 AI 工程化方面有深厚的积累。互联网行业历练技术十余年,有丰富的搜索、推荐系统研发经验。随着深度学习技术的成熟,人们尝试利用 AI 技术挖掘非结构化数据(图片,视频,自然语言文本等)中潜藏的价值。由此,人们对特征向量数据的分析处理需求大幅增长。然而通过现有的数据库组件和大数据技术来支撑这样的新型应用场景,却面临开发困难、运行成本高昂的挑战。为了帮助克服现有技术的局限性,我们发起了 Milvus 开源向量数据库项目。作为一个开源AI基础组件,Milvus 加快了企业开发 AI 应用的速度、大幅降了 AI 应用的部署成本。顾钧,Zilliz 高级架构师&合伙人。北大毕业 16 年以来始终专注于数据库、大数据技术,尤其对 OLTP 平台与场景有着丰富的经验。顾钧现后任职于工商银行,IBM,摩根士丹利,华为等企业。加入 Zilliz 以后,顾钧的工作重心在于开源社区的构建与推广。同时,顾钧代表 Zilliz 出席 LF AI & Data 基金会中的技术咨询委员会。《云上个性化推荐——
基于 PAI 和 Hologres 的个性化推荐最佳实践》
常见的个性化推荐系统包括日志收集,数据加工,召回,排序,离在线效果评估等诸多环节,对于中小客户存在技术门槛高,搭建周期长等问题。计算平台基于 PAI,Hologres,MaxCompute,DataWorks 平台产品,可以帮助客户快速搭建个性化推荐解决方案。本次分享,主要从计算平台的推荐系统整体解决方案出发,重点介绍基于 PAI 的向量召回算法和 Hologres 向量检索的整体架构,以及该架构在米连科技的落地案例和效果分享。天邑,阿里云计算平台高级算法工程师。主要从事基于 PAI 平台的召回和排序算法研发,及基于云产品的推荐系统解决方案研发,赋能客户个性化推荐解决方案落地。 《基于语义向量的内容召回和短文本分类的
文本标注——搜狐的 Mlivus 实战》
议题简介:
得益于 Mlivus 向量搜索工具的高效部署,在处理海量数据时准确快速,本次演讲中,我们将分享利用 Milvus 向量搜索工具解决语义向量召回时的向量搜索问题和短新闻文本分类时文本的标注问题。
王婷婷,搜狐自然语言处理工程师。在搜狐主要从事基于内容的语义向量召回,文本分类,文本摘要,新闻聚类,新闻关键词提取等相关工作。
如何参加?
点击文末「阅读原文」马上报名,了解更多向量搜索前沿技术,与大佬零距离交流,3 月 20 日,我们在北京等你!
▼ 合作伙伴 ▼

⏬戳我,立即报名!









