
概述:机器学习和大数据技术在信贷风控场景中的应用

来源:知乎 本文约5400字,建议阅读10分钟
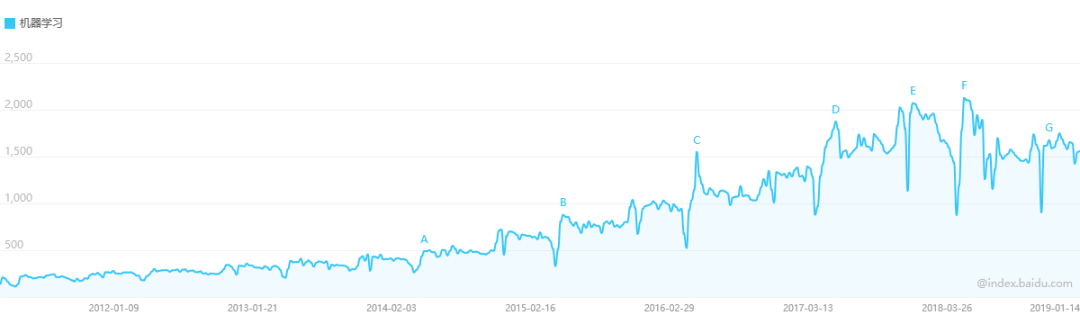
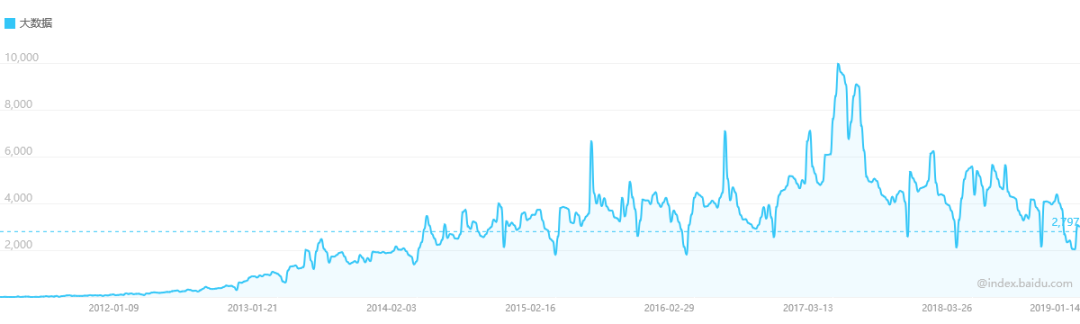
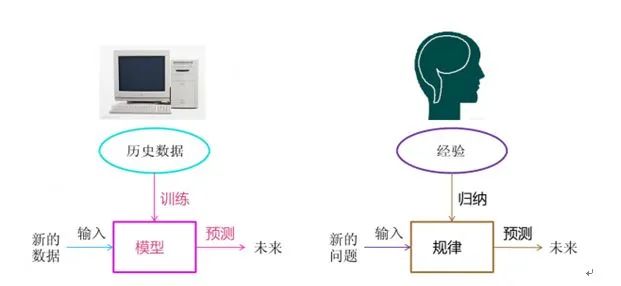
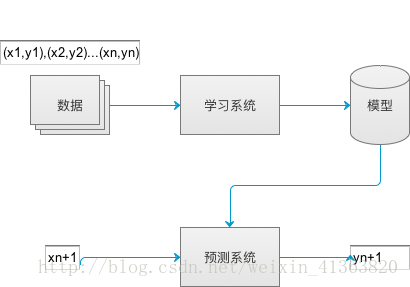
本文简要概述在当前大数据和机器学习技术如何在信贷风控场景下的常见应用。

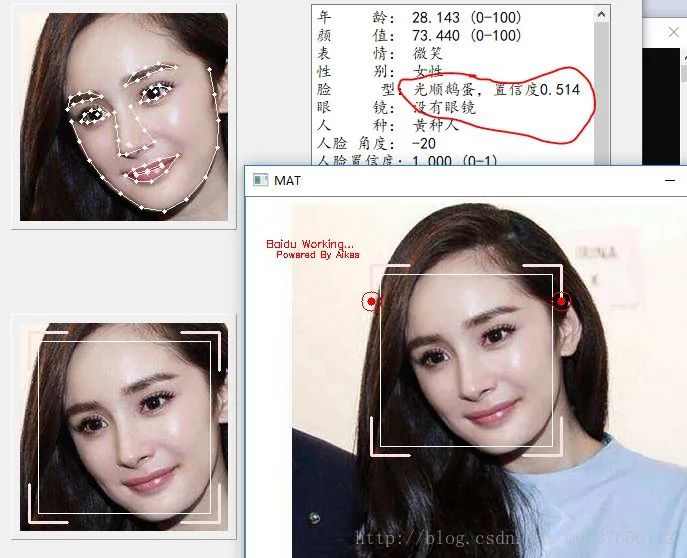
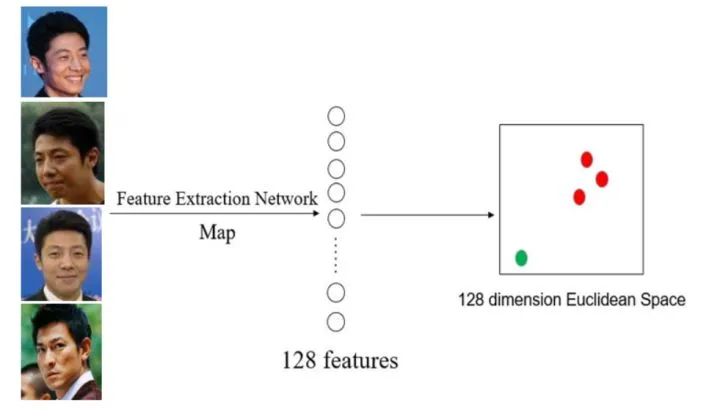
非本人申请:人脸识别技术




央行征信报告:一般持牌金融机构有央行征信介入权限,包括个人的执业资格记录、行政奖励和处罚记录、法院诉讼和强制执行记录、欠税记录等。 司法信息:最高法以及省市各级法院的最新公布名单,包括执行法院、立案时间、执行案号、执行标的、案件状态、执行依据、执行机构、生效法律文书确定的义务、被执行人的履行情况、失信被执行人的行为等信息。 公安信息:覆盖公安系统涉案、在逃和有案底人员信息,包括案发时间、案件详情如诈骗案/生产、销售假药案等信息。 信用卡信息:银行储蓄卡/信用卡支出、收入、逾期等信息。 航旅信息:包含过去一年中,每个季度的飞行城市、飞行次数、座位层次等数据。 社交信息:包含社交账号匹配类型、社交账号性别、社交账号粉丝数等。 运营商信息:核查运营商账户在网时长、在网状态、消费档次、通话习惯等信息。 网贷黑名单:根据个人姓名和身份证号码验证是否有网贷逾期、黑名单信息。 驾驶证状态,租车黑名单,电商消费记录等也是可以考量的因素

编辑:王菁
评论