
数据湖在大数据典型场景下应用调研个人笔记

华为生产场景数据湖平台建设实践
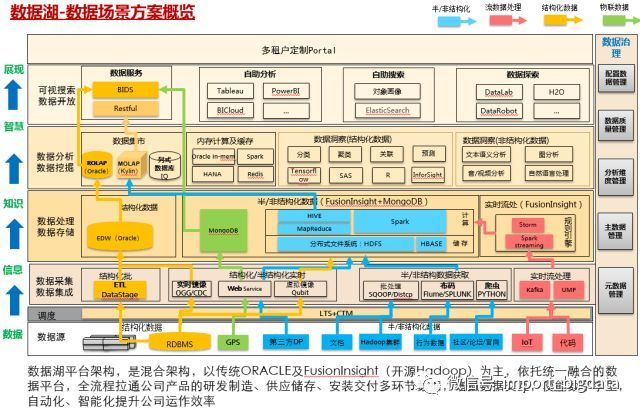

(绿色)结构化数据通过批处理、虚拟镜像到Hive数据,再通过Kylin预处理将数据储存在Cube中,封装成RESTAPI服务,提供高并发亚秒级查询服务,监测物料质量情况;
(红色)IoT数据,通过sensor采集上报到MQS,走storm实时分拣到HBase,通过算法模型加工后进行ICT物料预警监测;
(黄色)条码数据通过ETLloader到IQ列式数据湖,经过清洗加工后,提供千亿规模条码扫描操作。
统一索引描述非结构数据,方便数据检索分析。
增加维护及更新时间作为对象描述字段(图片类型、像素大小、尺寸规格)。非对象方式及数字化属性编目(全文文本、图像、声音、影视、超媒体等信息),自定义元数据。
不同类型的数据可以形成了关联并处理非结构化数据。
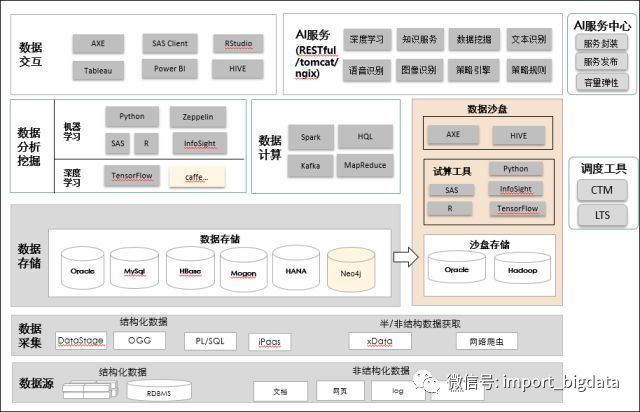
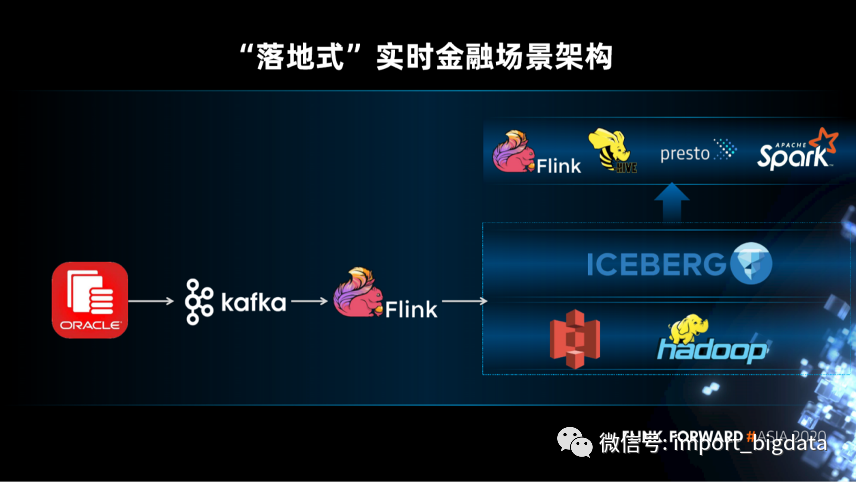
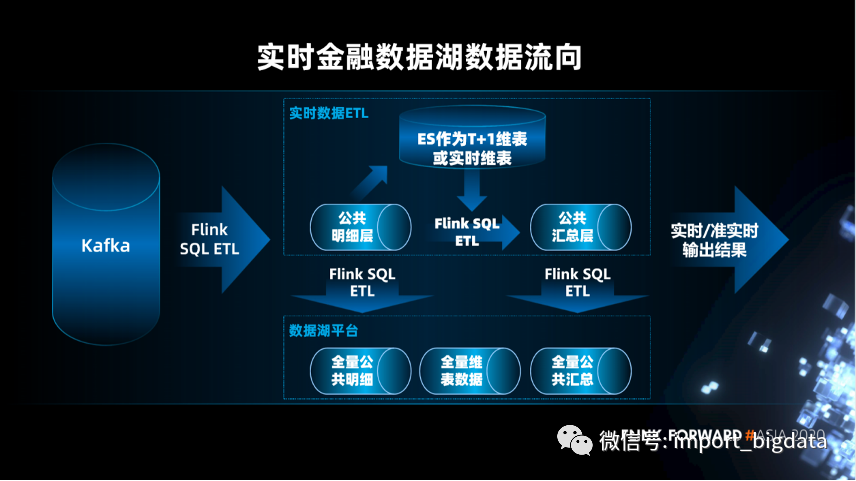
实时金融数据湖的应用
第一,数据源。不仅仅支持结构化数据,也支持半结构化数据和非结构化数据。
第二,统一数据接入。数据通过统一数据接入平台,按数据的不同类型进行智能的数据接入。
第三,数据存储。包括数据仓库和数据湖,实现冷热温智能数据分布。
第四,数据开发。包括任务开发,任务调度,监控运维,可视化编程。
第五,数据服务。包括交互式查询,数据 API,SQL 质量评估,元数据管理,血缘管理。
第六,数据应用。包括数字化营销,数字化风控,数据化运营,客户画像。

在存储层,有 MPP 数据仓库和基于 OSS/HDFS 的数据湖,可以实现智能存储管理。
在计算层,实现统一的元数据服务。
在服务层,有联邦数据计算和数据服务 API 两种方式。其中,联邦数据计算服务是一个联邦查询引擎,可以实现数据跨库查询,它依赖的就是统一元数据服务,查询的是数据仓库和数据湖中的数据。
在产品层,提供智能服务:包 RPA、证照识别、语言分析、客户画像、智能推荐。商业分析服务:包括自助分析、客户洞察、可视化。数据开发服务:包括数据开发平台,自动化治理。
Soul的Delta Lake数据湖应用实践
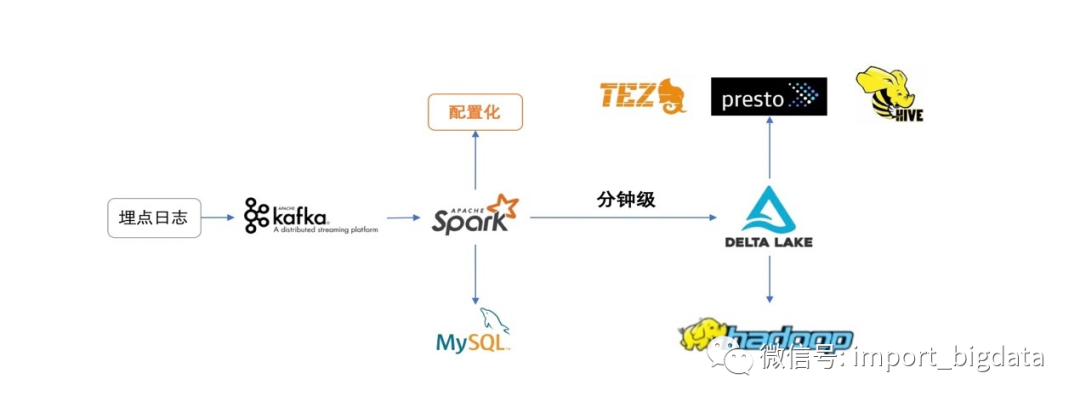
实现了类似Iceberg的hidden partition功能,用户可选择某些列做适当变化形成一个新的列,此列可作为分区列,也可作为新增列,使用SparkSql操作。如:有日期列date,那么可以通过 'substr(date,1,4) as year' 生成新列,并可以作为分区。
为避免脏数据导致分区出错,实现了对动态分区的正则检测功能,比如:Hive中不支持中文分区,用户可以对动态分区加上'\w+'的正则检测,分区字段不符合的脏数据则会被过滤。
实现自定义事件时间字段功能,用户可选数据中的任意时间字段作为事件时间落入对应分区,避免数据漂移问题。
嵌套Json自定义层数解析,我们的日志数据大都为Json格式,其中难免有很多嵌套Json,此功能支持用户选择对嵌套Json的解析层数,嵌套字段也会被以单列的形式落入表中。
实现SQL化自定义配置动态分区的功能,解决埋点数据倾斜导致的实时任务性能问题,优化资源使用,此场景后面会详细介绍。
