
刷爆HACS挑战赛时序动作检测榜单!TCANet:最强时序动作提名修正网络 CVPR 2021

极市导读
本文介绍了商汤科技城市计算研发组发表在CVPR2021上的工作,提出了一种基于时序上下文聚合的动作提名修正网络(TCANet)。实验结果表明,TCANet在HACS,ActivityNet-1.3和THUMOS14等三个主流公开数据集上都获得了非常显著的性能提升。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文主要介绍我们团队(商汤科技城市计算研发组)发表在CVPR2021上的工作,提出了一种基于时序上下文聚合的动作提名修正网络(TCANet)。现有方法普遍缺乏一种精细且高效的时序依赖建模方式,并且没有对提名的边界信息进行充分的利用,导致生成的边界概率序列具有局部/全局的噪声,从而使得提名的边界质量不佳。实验结果表明,TCANet在HACS,ActivityNet-1.3和THUMOS14等三个主流公开数据集上都获得了非常显著的性能提升。基于该方法,我们在CVPR2020-HACS挑战赛中的时序动作检测任务榜单上排名第一。
论文名称:

任务背景
时序动作提名生成旨在从一段未修剪的长视频当中生成包含可能存在人类动作的视频片段,其结合具体的动作类别标签即构成时序动作检测任务。目前的方法大多致力于生成灵活准确的时序边界与可靠的提名置信度,但是仍然受限于匮乏的视频时序依赖和动作边界建模,导致了充满噪声的候选提名边界和质量欠佳的置信度分数。
目前主流的时序动作提名生成方法主要分为两步,首先对输入的视频特征序列进行简单的时序信息融合,然后使用基于边界预测的方法或者是基于预定义锚点框回归的方法生成可能包含人体动作的大量候选时序提名。
方法介绍
本文提出了一个用于时序动作提名修正的端到端框架。该方法主要针对现有主流时序动作提名生成方法中的两步骤分别进行改进:
1. 在第一步中,现有方法大多使用堆叠的1D时序卷积进行简单的时序信息融合,然而,1D卷积在计算不同时序点之间的位置关系时,受限于卷积核的形状和尺寸,虽然可以较好地建模短期的时序依赖,但是对于灵活多变的上下文关系则望尘莫及。部分办法选择了全局融合的方式实现了对全局特征的捕获,但是直接使用全局池化之后的特征拼接到整个视频特征序列上的每一个时刻位置,导致每一个时刻获得的全局信息都是相同的,由此捕获的时序依赖关系相对固定,缺乏多样性和区分度,无法充分建模多样的长时序依赖关系。
2. 在第二步中,基于预定义锚点框回归的方法可以提供基于提名全局特征的可靠置信度分数,然而直接使用提名的全局特征对于其局部边界的准确位置不够敏感,况且预定义尺度和比例的提名时序长度往往非常受限,不够灵活,无法生成任意长度的候选提名。基于边界预测的方法利用边界的局部特征判断一个时间点是否属于动作边界,对动作的起止边缘比较敏感,并且使用边界匹配机制来生成大量灵活的动作提名,获得较高的召回率。由于缺乏客观的提名特征,其置信度不够可靠,导致其准确率较低。
该方法主要针对现有技术的缺陷进行了相应的改进:
1. 针对时序建模不够充分的问题,对各个时序点的特征采用通道分组策略进行高效建模,以多头自注意力的方式同时对时序上的每一个点分别求取局部和全局的多样化时序依赖关系。
2. 为了提高边界特征的利用效率,利用基于边界预测的方法和基于预定义锚点框回归的方法二者之间的互补特性,提出使用提名的起始和结束边界上下文特征来预测待优化提名的起始点和结束点偏移,同时使用提名的全局特征来预测待优化提名的中心位置和时序长度偏移。对这两种方式得到的回归后的提名进行平均融合,得到更加准确的提名边界。
3. 为了端到端的进行两种回归方式的联合优化从而逐步地提高提名的边界质量,采用级联的方式对输入的候选提名进行多阶段的修正,通过由粗到细的正负样本划分方式,将输入的待优化提名依次通过三个级联的提名优化模块,实验表明每一个提名优化模块都可以逐步地提高提名的边界质量。
本技术方案的目的在于设计一个能够同时捕获局部和全局上下文信息的时序动作提名优化模型。整个框架主要解决了两个主要的子任务:基于局部全局的鲁棒且多样化的时序依赖建模和对候选提名由粗到细的多阶段修正。整体框架流程如下图所示。

本方案主要包含以下2个模块:
1、局部-全局时序特征编码器 (LGTE)
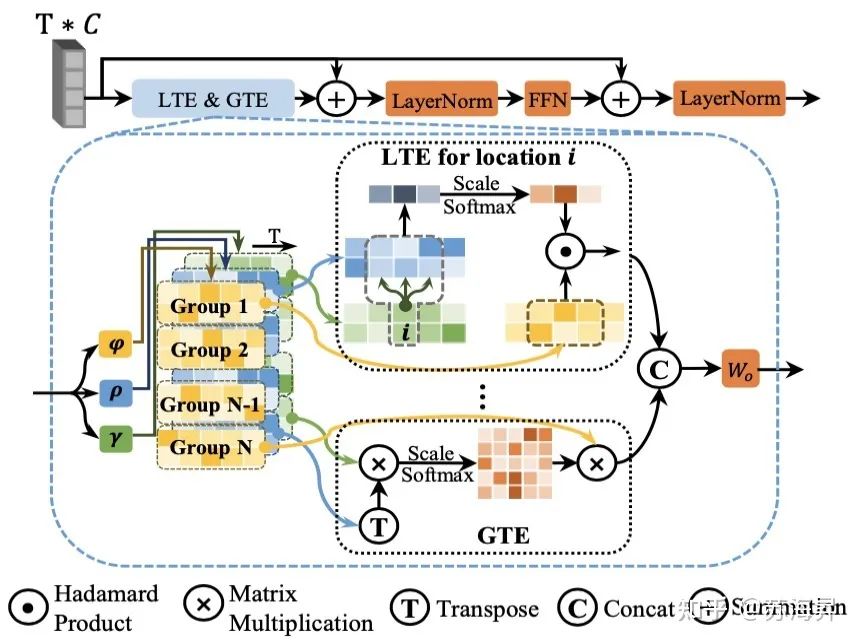
该模块主要用于对输入的时序特征同时进行局部和全局的时序依赖关系捕获。该模块的核心思想是,首先对输入的时序特征对通道维度分别进行三次不同的线性变换之后,沿通道方向分成8个组,其中4组特征用来对每一时刻位置进行全局的时序自注意力建模(GTE),相当于是对全局时序特征分别进行一次动态的关系编码,然后剩下的四组特征则用来对每一时刻位置进行局部的时序自注意力编码(LTE),目的是建模每个时刻的周围特征关系,捕获局部细微的时序变化。
通过上述方法,局部-全局特征编码器实现了对局部和全局特征依赖关系的并行计算,经过训练优化之后可以生成鲁棒而多样化的时序特征表达用于后续的提名生成和优化网络。
2、互补时序边界回归器(TBR)
该模块的主要目的是为了结合基于预定义框回归和基于局部信息的起止边界点预测等两种提名生成方案的优缺点,得到既能准确定位边界,又能生成可靠置信度得分的提名边界回归器。
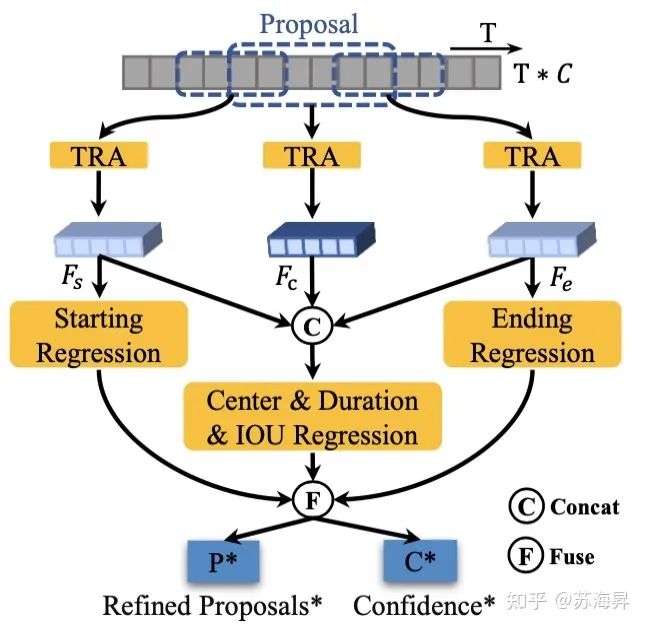
具体来说,如模块图所示,在将提名从经过局部-全局时序编码后的原长特征序列上进行采样之后,进一步将一个提名的时序特征分成三个部分,分别为起始点的局部特征Fs,提名的中心特征Fc以及结束点的局部特征Fe。Fs和Fe被用来回归待优化提名的起始点和结束点的偏移量,Fs,Fc 和Fe则用于联合回归提名的中心点和提名长度的偏移量。使用上述两种方案都可以得到一个新的提名边界,最后将新的提名边界进行融合,即可得到最终的提名结果和置信度分数。
由于TCANet不需要大量时序提名即可实现高效的训练,因此在训练过程中对特征的采样可以直接在输入的原始视频特征上进行,这种采样方式相比于在统一的尺度上进行采样,可以带来更少的量化特征损失,从而有效提高特征的质量。
模型训练
1、用于训练的待优化提名选择
在本方法的训练阶段,不使用其他方法(例如BMN等)输出的全部候选提名用于训练,为了提高训练效率,首先使用Soft-NMS去除大量冗余的时序提名,最后选择置信度分数在Top-100的提名用于优化器训练。
2、训练标签分配
在训练TBR的过程中,只有和真值的IoU大于一定阈值的提名被定义为正样本,与真值的IoU小于一定阈值的提名则被定义为负样本,而位于两个阈值之间的提名被定义为不完全样本。在训练的过程中,通过在线的随机采样保证这三种样本之间的数量比例为1:1:1,实现训练过程中正负样本的平衡。由于在多阶段训练过程中,为了实现由粗到细的边界优化,提升模型收敛的效率,采用了不同的正负样本划分阈值。
3、损失函数
本方案需要对提名的置信度预测和边界回归的偏移量同时进行监督,将这两部分的损失函数分别定义为Liou和Lreg,分别为:

其中:
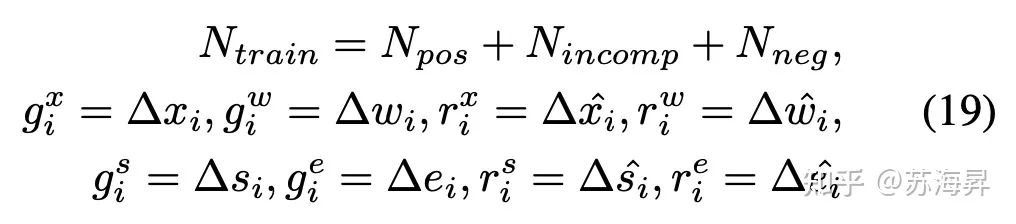
最后,总的损失函数为:
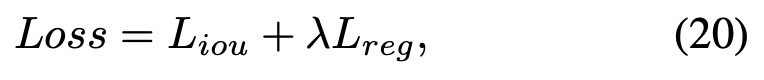
实验结果
在HACS数据集上,我们以复现的BMN方法作为基准,实验结果表明,TCANet可以比BMN提高至少4个点的平均mAP,仅靠单模型就可以超越CVPR2020-HACS榜单的第二名方案。
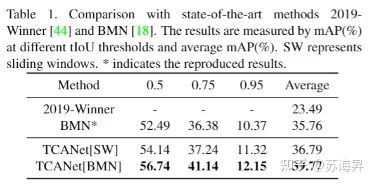
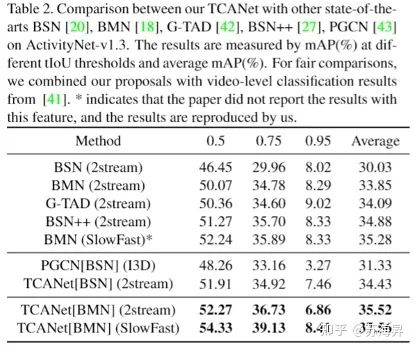
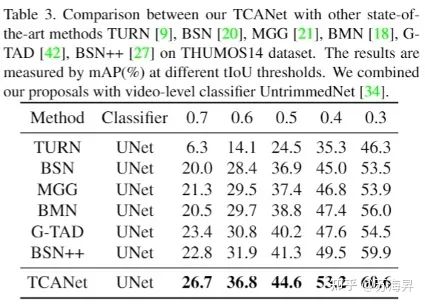
在ActivityNet-v1.3和THUMOS14数据集上也都有明显的效果提升,取得了现阶段最佳的时序动作检测效果:
根据观察发现,在时序行为检测任务中,贡献最终检测性能mAP主要取决于打分靠前的若干提名,因此不仅注重提名的多样性,更注重提名的准确性。TCANet在对候选提名的进行优化后,主要提高了AR@1和AR@10的效果,因此对于时序行为检测性能的提升非常明显,排名靠前的提名质量也更高,对于该任务的业务应用落地有非常重要的意义。
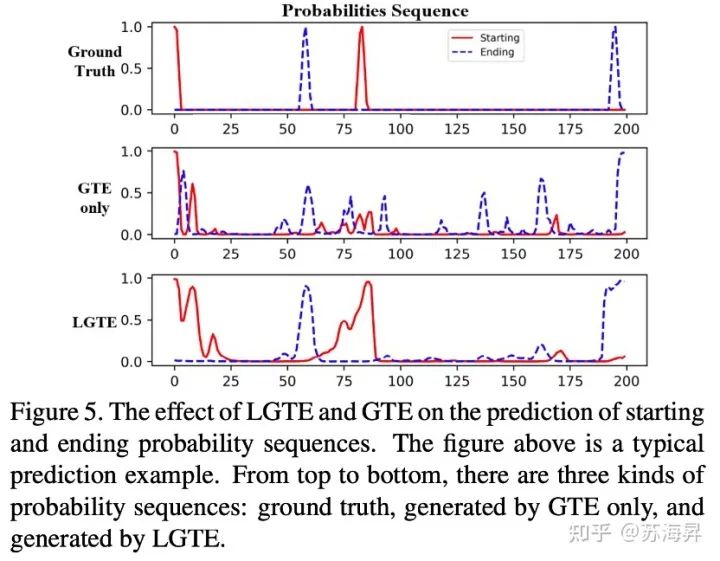
局部-全局时序编码模块在边界概率预测的结果可视化如下所示,可见在仅是有全局时序编码时,容易产生较多的全局噪声,且对于动作边界的响应较低。P.S. 在我们之前的工作:AAAI2021|BSN++:时序动作提名生成网络文章解读(https://zhuanlan.zhihu.com/p/344065976)中曾指出,仅使用堆叠的1D卷积进行边界预测时也会产生较多的边界噪声,导致精度较低。
我们接着对TCANet的各个模块进行了效率分析,如下表所示:

关于多阶段时序边界回归模块的优化效果如下图所示:

此外,TCANet不仅可以用来提升已有方法生成提名的总体质量,也可以在随机输入(例如,一系列的滑动窗口)时生成高质量的提名,且实验表明在这种情况下也可取得SOTA的效果。关于TCANet方法的模块消融实验和不同方法提名输入时的鲁棒性测试以及效率测试,欢迎关注后续论文链接!
结语
本文首先提出了用于同时聚合局部-全局信息的时序特征编码模块,在主流大型视频数据集上均取得了显著的效果提升,证实了长时序建模对于视频理解任务的重要性。同时,基于边界特征和提名特征的互补边界回归进一步提高了定位的准确性。在方法的实现细节部分涉及了较多的insight,为该任务的后续发展提供了参考的方向。
论文地址:
https://arxiv.org/abs/2103.13141.pdf
推荐阅读
2021-03-23

2021-03-21

2021-03-16


# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
