
Hive文件存储格式和Hive数据压缩小总结
一、存储格式行存储和列存储
行存储可以理解为一条记录存储一行,通过条件能够查询一整行数据。
列存储,以字段聚集存储,可以理解为相同的字段存储在一起。
二、Hive文件存储格式
TEXTFILE
Hive数据表的默认格式,存储方式:行存储。
可以使用Gzip压缩算法,但压缩后的文件不支持split。
在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
SEQUENCEFILE
压缩数据文件可以节省磁盘空间,但Hadoop中有些原生压缩文件的缺点之一就是不支持分割。支持分割的文件可以并行的有多个mapper程序处理大数据文件,大多数文件不支持可分割是因为这些文件只能从头开始读。Sequence File是可分割的文件格式,支持Hadoop的block级压缩。
Hadoop API提供的一种二进制文件,以key-value的形式序列化到文件中。存储方式:行存储。
sequencefile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,RECORD是默认选项,通常BLOCK会带来较RECORD更好的压缩性能。
优势是文件和hadoop api中的MapFile是相互兼容的
RCFILE
存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点:
RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低
像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取
数据追加:RCFile不支持任意方式的数据写操作,仅提供一种追加接口,这是因为底层的 HDFS当前仅仅支持数据追加写文件尾部。
行组大小:行组变大有助于提高数据压缩的效率,但是可能会损害数据的读取性能,因为这样增加了 Lazy 解压性能的消耗。而且行组变大会占用更多的内存,这会影响并发执行的其他MR作业。考虑到存储空间和查询效率两个方面,Facebook 选择 4MB 作为默认的行组大小,当然也允许用户自行选择参数进行配置。
ORCFILE
存储方式:数据按行分块,每块按照列存储。
压缩快,快速列存取。效率比rcfile高,是rcfile的改良版本。
三、创建语句和压缩
3.1 压缩工具的对比:
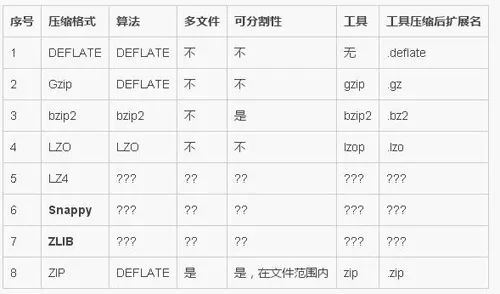
Hadoop编码/解码器方式,如下表所示

3.2、压缩设置
HiveQL语句最终都将转换成为hadoop中的MapReduce job,而MapReduce job可以有对处理的数据进行压缩。
Hive中间数据压缩
hive.exec.compress.intermediate:默认为false,设置true为激活中间数据压缩功能,就是MapReduce的shuffle阶段对mapper产生中间压缩,在这个阶段,优先选择一个低CPU开销:
set hive.exec.compress.intermediate=true
set mapred.map.output.compression.codec= org.apache.hadoop.io.compress.SnappyCodec
set mapred.map.output.compression.codec=com.hadoop.compression.lzo.LzoCodec最终输出结果压缩
hive.exec.compress.output:用户可以对最终生成的Hive表的数据通常也需要压缩。该参数控制这一功能的激活与禁用,设置为true来声明将结果文件进行压缩。
mapred.output.compression.codec:将hive.exec.compress.output参数设置成true后,然后选择一个合适的编解码器,如选择SnappyCodec。设置如下(两种压缩的编写方式是一样的):
set hive.exec.compress.output=true
set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec
或者
或者
set mapred.output.compress=true
set mapred.output.compression.codec=org.apache.hadoop.io.compress.LzopCodec3.3、 四种格式的存储和压缩设置(客户端设置压缩格式)
TEXTFILE
create table if not exists textfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '\t'
stored as textfile;
插入数据操作:
set hive.exec.compress.output=true; //输出结果压缩开启
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec; //压缩和解压缩编码类列表,用逗号分隔,将所用到解压和压缩码设置其中
insert overwrite table textfile_table select * from testfile_table;SEQUENCEFILE
create table if not exists seqfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '\t'
stored as sequencefile;
插入数据操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
SET mapred.output.compression.type=BLOCK;
insert overwrite table seqfile_table select * from testfile_table;RCFILE
create table if not exists rcfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '\t'
stored as rcfile;
插入数据操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table rcfile_table select * from testfile_table;ORCFILE
create table if not exists orcfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '\t'
stored as orc;
插入数据操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table orcfile_table select * from testfile_table;总结:
TextFile默认格式,加载速度最快,可以采用Gzip进行压缩,压缩后的文件无法split,无法并行处理了。
SequenceFile压缩率最低,查询速度一般,将数据存放到sequenceFile格式的hive表中,这时数据就会压缩存储。三种压缩格式NONE,RECORD,BLOCK。是可分割的文件格式.
RCfile压缩率最高,查询速度最快,数据加载最慢。
相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
在hive中使用压缩需要灵活的方式,如果是数据源的话,采用RCFile+bz或RCFile+gz的方式,这样可以很大程度上节省磁盘空间;而在计算的过程中,为了不影响执行的速度,可以浪费一点磁盘空间,建议采用RCFile+snappy的方式,这样可以整体提升hive的执行速度。至于lzo的方式,也可以在计算过程中使用,只不过综合考虑(速度和压缩比)还是考虑snappy适宜。