
JVM 调优一个月,性能提升了 400 倍!
通过这一个多月的努力,将 FullGC 从 40 次/天优化到近 10 天才触发一次,而且 YoungGC 的时间也减少了一半以上,这么大的优化,有必要记录一下中间的调优过程。
对于JVM垃圾回收,之前一直都是处于理论阶段,就知道新生代,老年代的晋升关系,这些知识仅够应付面试使用的。前一段时间,线上服务器的FullGC非常频繁,平均一天40多次,而且隔几天就有服务器自动重启了,这表明的服务器的状态已经非常不正常了,得到这么好的机会,当然要主动请求进行调优了。未调优前的服务器GC数据,FullGC非常频繁。
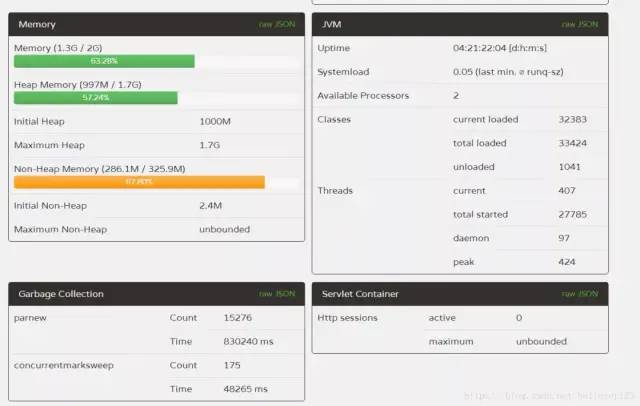
首先服务器的配置非常一般(2核4G),总共4台服务器集群。每台服务器的FullGC次数和时间基本差不多。其中JVM几个核心的启动参数为:
-Xms1000M -Xmx1800M -Xmn350M -Xss300K -XX:+DisableExplicitGC -XX:SurvivorRatio=4 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128M -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC
-Xmx1800M:设置JVM最大可用内存为1800M。-Xms1000m:设置JVM初始化内存为1000m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。-Xmn350M:设置年轻代大小为350M。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。
此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。-Xss300K:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
第一次优化
一看参数,马上觉得新生代为什么这么小,这么小的话怎么提高吞吐量,而且会导致YoungGC的频繁触发,如上如的新生代收集就耗时830s。初始化堆内存没有和最大堆内存一致,查阅了各种资料都是推荐这两个值设置一样的,可以防止在每次GC后进行内存重新分配。基于前面的知识,于是进行了第一次的线上调优:提升新生代大小,将初始化堆内存设置为最大内存
-Xmn350M -> -Xmn800M -XX:SurvivorRatio=4 -> -XX:SurvivorRatio=8 -Xms1000m ->-Xms1800m
将SurvivorRatio修改为8的本意是想让垃圾在新生代时尽可能的多被回收掉。就这样将配置部署到线上两台服务器(prod,prod2另外两台不变方便对比)上后,运行了5天后,观察GC结果,YoungGC减少了一半以上的次数,时间减少了400s,但是FullGC的平均次数增加了41次。YoungGC基本符合预期设想,但是这个FullGC就完全不行了。
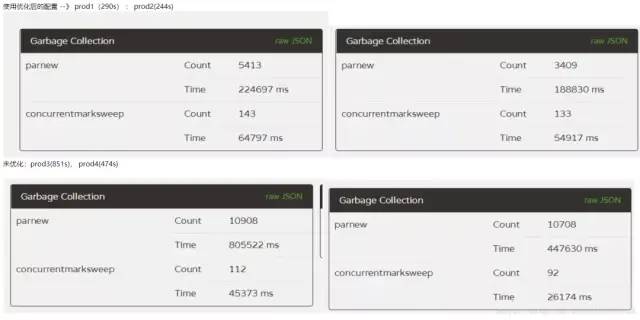
就这样第一次优化宣告失败。
第二次优化
在优化的过程中,我们的主管发现了有个对象T在内存中有一万多个实例,而且这些实例占据了将近20M的内存。于是根据这个bean对象的使用,在项目中找到了原因:匿名内部类引用导致的,伪代码如下:
public void doSmthing(T t){
redis.addListener(new Listener(){
public void onTimeout(){
if(t.success()){
//执行操作
}
}
});
}
内存泄漏调查
经过了第一次的调优后发现内存泄漏的问题,于是大家都开始将进行内存泄漏的调查,首先排查代码,不过这种效率是蛮低的,基本没发现问题。于是在线上不是很繁忙的时候继续进行dump内存,终于抓到了一个大对象。
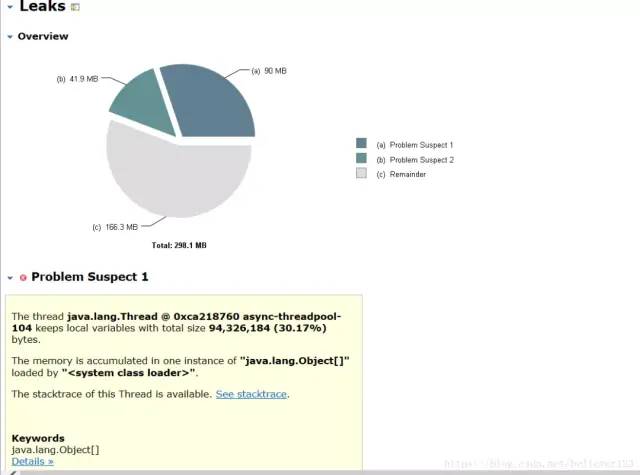
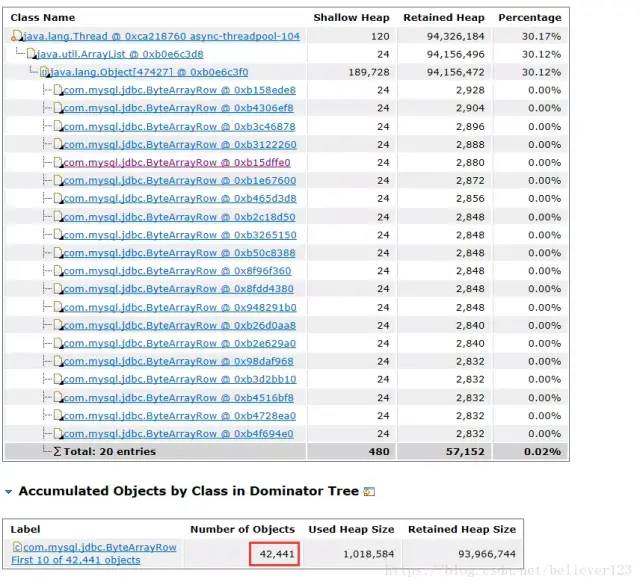
经过一番确认,目前完全没有这么大的业务量,而且也不存在文件上传的功能。咨询了云服务器客服也说明完全是正常的流量,可以排除攻击的可能。
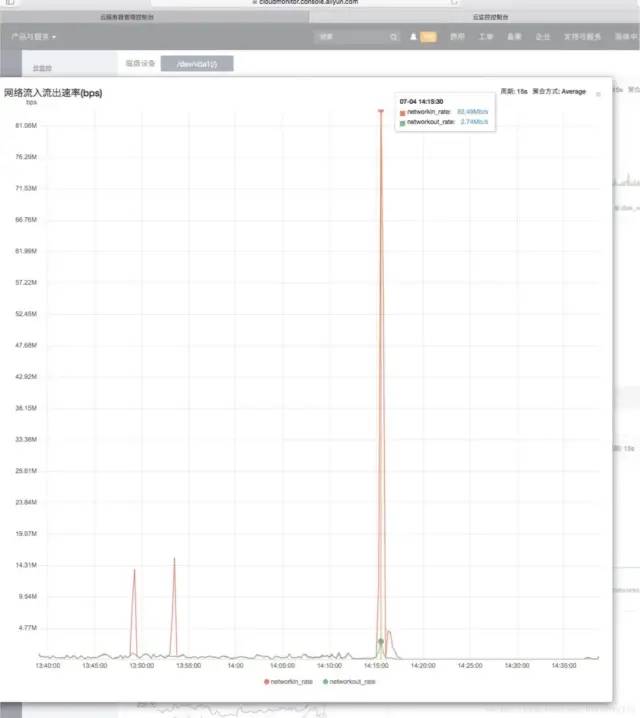
就在我还在调查入口流量的问题时,另外一个同事找到了根本的原因,原来是在某个条件下,会查询表中所有未处理的指定数据,但是由于查询的时候where条件中少加了模块这个条件,导致查询出的数量达40多万条,而且通过log查看当时的请求和数据,可以判断这个逻辑确实是已经执行了的,dump出的内存中只有4W多个对象,这个是因为dump时候刚好查询出了这么多个,剩下的还在传输中导致的。而且这也能非常好的解释了为什么服务器会自动重启的原因
解决了这个问题后,线上服务器运行完全正常了,使用未调优前的参数,运行了3天左右FullGC只有5次:
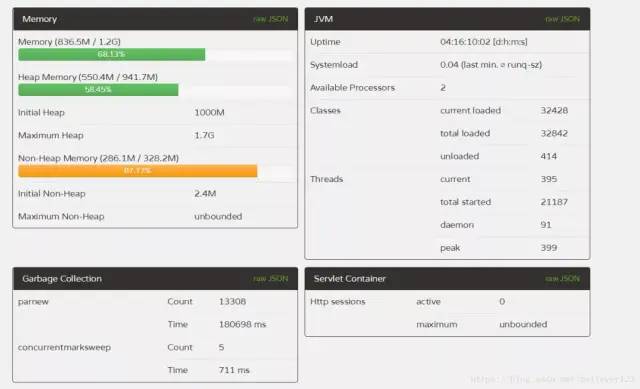
第三次调优
内存泄漏的问题已经解决了,剩下的就可以继续调优了,经过查看GC log,发现前三次GullGC时,老年代占据的内存还不足30%,却发生了FullGC。另外,微信搜索互联网架构师,在后台发送:2T,可以获取一份完整的 JVM 调优指南。
于是进行各种资料的调查,在:https://blog.csdn.net/zjwstz/article/details/77478054 博客中非常清晰明了的说明metaspace导致FullGC的情况,服务器默认的metaspace是21M,在GC log中看到了最大的时候metaspace占据了200M左右,于是进行如下调优,以下分别为prod1和prod2的修改参数,prod3,prod4保持不变。
-Xmn350M -> -Xmn800M -Xms1000M ->1800M -XX:MetaspaceSize=200M -XX:CMSInitiatingOccupancyFraction=75
和
-Xmn350M -> -Xmn600M -Xms1000M ->1800M -XX:MetaspaceSize=200M -XX:CMSInitiatingOccupancyFraction=75
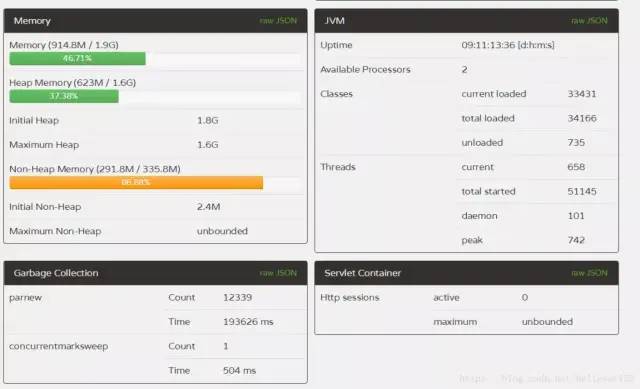
prod1和2只是新生代大小不一样而已,其他的都一致。到线上运行了10天左右,进行对比:prod1:
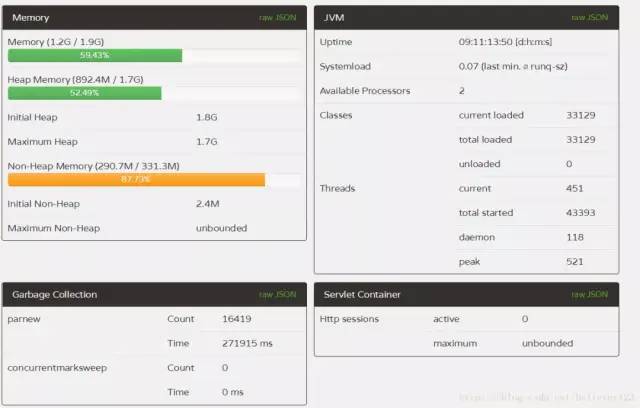
prod2:
prod3:
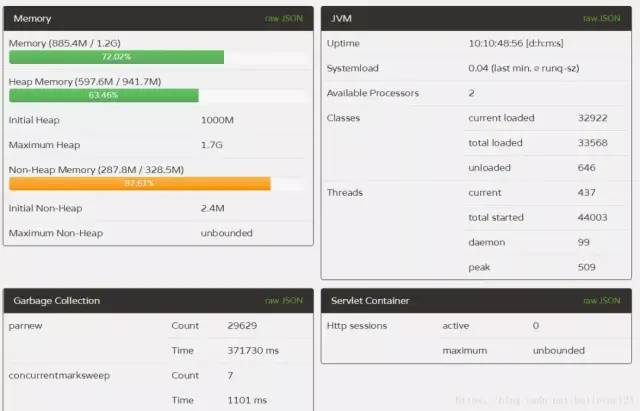
prod4:
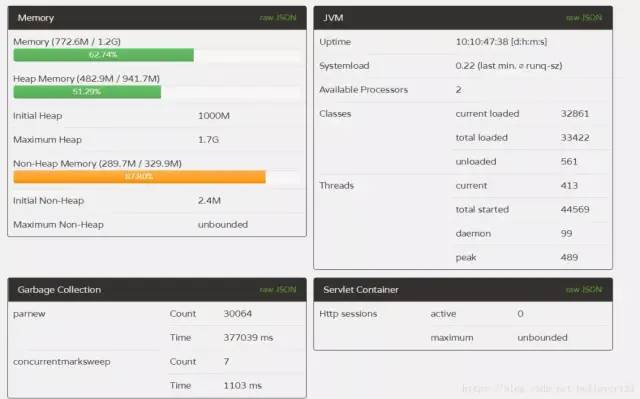
对比来说,1,2两台服务器FullGC远远低于3,4两台,而且1,2两台服务器的YounGC对比3,4也减少了一半左右,而且第一台服务器效率更为明显,除了YoungGC次数减少,而且吞吐量比多运行了一天的3,4两台的都要多(通过线程启动数量),说明prod1的吞吐量提升尤为明显。通过GC的次数和GC的时间,本次优化宣告成功,且prod1的配置更优,极大提升了服务器的吞吐量和降低了GC一半以上的时间。
prod1中的唯一一次FullGC:
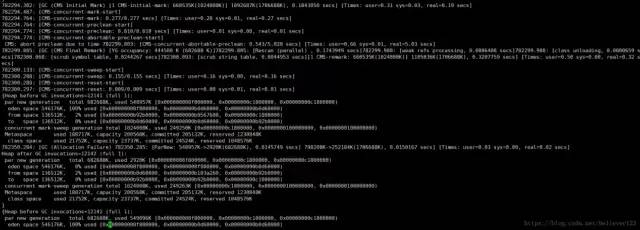
通过GC log上也没看出原因,老年代在cms remark的时候只占据了660M左右,这个应该还不到触发FullGC的条件,而且通过前几次的YoungGC调查,也排除了晋升了大内存对象的可能,通过metaspace的大小,也没有达到GC的条件。这个还需要继续调查,有知道的欢迎指出下,这里先行谢过了。
总结
通过这一个多月的调优总结出以下几点:
FullGC一天超过一次肯定就不正常了 发现FullGC频繁的时候优先调查内存泄漏问题 内存泄漏解决后,jvm可以调优的空间就比较少了,作为学习还可以,否则不要投入太多的时间 如果发现CPU持续偏高,排除代码问题后可以找运维咨询下云服务器客服,这次调查过程中就发现CPU 100%是由于服务器问题导致的,进行服务器迁移后就正常了。 数据查询的时候也是算作服务器的入口流量的,如果访问业务没有这么大量,而且没有攻击的问题的话可以往数据库方面调查 有必要时常关注服务器的GC,可以及早发现问题
以上是最近一个多月JVM调优的过程与总结,如有错误之处欢迎指正。
原文链接:https://blog.csdn.net/cml_blog/article/details/81057966
正文结束
1.不认命,从10年流水线工人,到谷歌上班的程序媛,一位湖南妹子的励志故事
5.37岁程序员被裁,120天没找到工作,无奈去小公司,结果懵了...
一个人学习、工作很迷茫?
点击「阅读原文」加入我们的小圈子!
