
面试官留步!听我跟你侃会儿Docker原理
1 Docker 简介
1.1 Docker 由来
Docker 是基于 Go 语言开发的一个容器引擎,Docker是应用程序与系统之间的隔离层。通常应用程序对安装的系统环境会有各种严格要求,当服务器很多时部署时系统环境的配置工作是非常繁琐的。Docker让应用程序不必再关心主机环境,各个应用安装在Docker镜像里,Docker引擎负责运行包裹了应用程序的docker镜像。
Docker的理念是让开发人员可以简单地把应用程序及依赖装载到容器中,然后轻松地部署到任何地方,Docker具有如下特性。
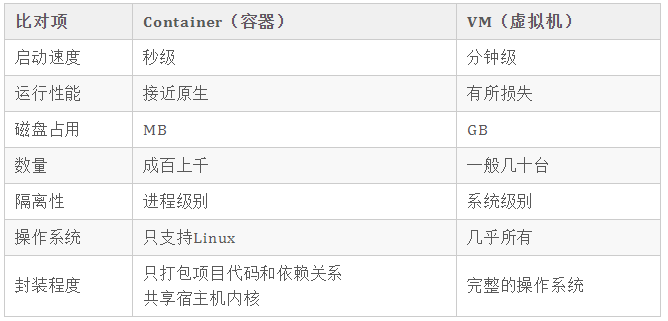
Docker容器是轻量级的虚拟技术,占用更少系统资源。
使用 Docker容器,不同团队(如开发、测试,运维)之间更容易合作。
可以在任何地方部署 Docker 容器,比如在任何物理和虚拟机上,甚至在云上。
由于Docker容器非常轻量级,因此可扩展性很强。
1.2 Docker 基本组成
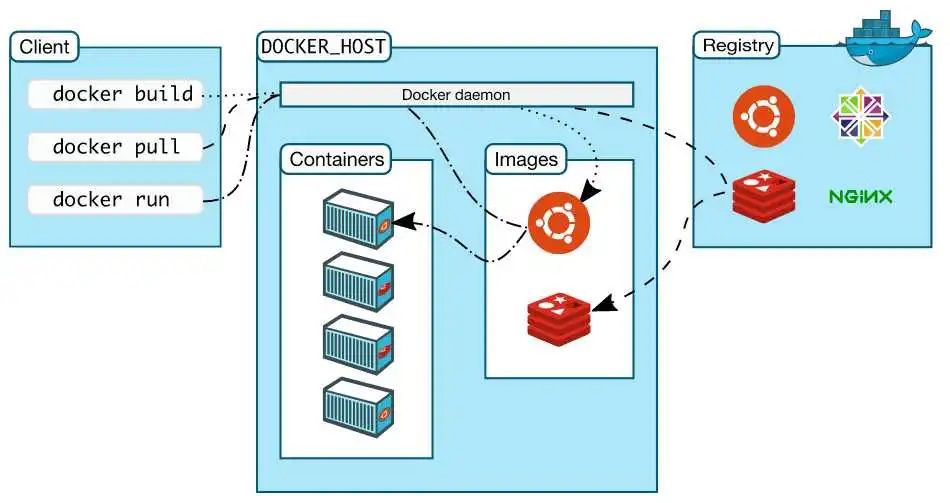
镜像(image):
Docker 镜像就好比是一个目标,可以通过这个目标来创建容器服务,可以简单的理解为编程语言中的类。
容器(container):
Docker 利用容器技术,独立运行一个或者一组应用,容器是通过镜像来创建的,在容器中可执行启动、停止、删除等基本命令,最终服务运行或者项目运行就是在容器中的,可理解为是类的实例。
仓库(repository):
仓库就是存放镜像的地方!仓库分为公有仓库和私有仓库,类似Git。一般我们用的时候都是用国内docker镜像来加速。
1.3 VM 跟 Docker
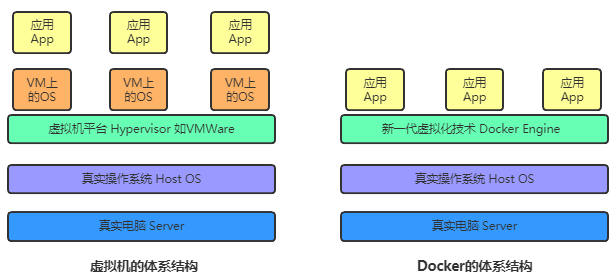
虚拟机:
传统的虚拟机需要模拟整台机器包括硬件,每台虚拟机都需要有自己的操作系统,虚拟机一旦被开启,预分配给他的资源将全部被占用。每一个虚拟机包括应用,必要的二进制和库,以及一个完整的用户操作系统。
Docker:
容器技术是和我们的宿主机共享硬件资源及操作系统可以实现资源的动态分配。容器包含应用和其所有的依赖包,但是与其他容器共享内核。容器在宿主机操作系统中,在用户空间以分离的进程运行。
1.4 Docker 跟 DevOps
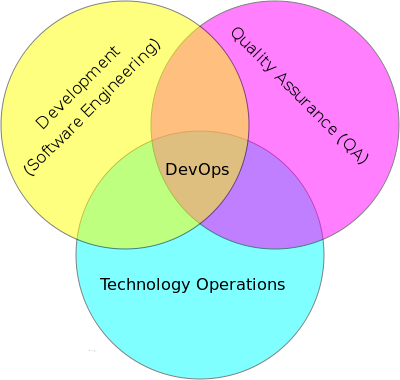
DevOps 是一组过程、方法与系统的统称,用于促进开发(应用程序/软件工程)、技术运营和质量保障(QA)部门之间的沟通、协作与整合。
DevOps 是两个传统角色 Dev(Development) 和 Ops(Operations) 的结合,Dev 负责开发,Ops 负责部署上线,但 Ops 对 Dev 开发的应用缺少足够的了解,而 Dev 来负责上线,很多服务软件不知如何部署运行,二者中间有一道明显的鸿沟,DevOps 就是为了弥补这道鸿沟。DevOps 要做的事,是偏 Ops 的;但是做这个事的人,是偏 Dev 的, 说白了就是要有一个了解 Dev 的人能把 Ops 的事干了。而Docker 是适合 DevOps 的。
1.5 Docker 跟 k8s
k8s 的全称是 kubernetes,它是基于容器的集群管理平台,是管理应用的全生命周期的一个工具,从创建应用、应用的部署、应用提供服务、扩容缩容应用、应用更新、都非常的方便,而且可以做到故障自愈,例如一个服务器挂了,可以自动将这个服务器上的服务调度到另外一个主机上进行运行,无需进行人工干涉。k8s 依托于Google自家的强大实践应用,目前市场占有率已经超过Docker自带的Swarm了。
如果你有很多 Docker 容器要启动、维护、监控,那就上k8s吧!
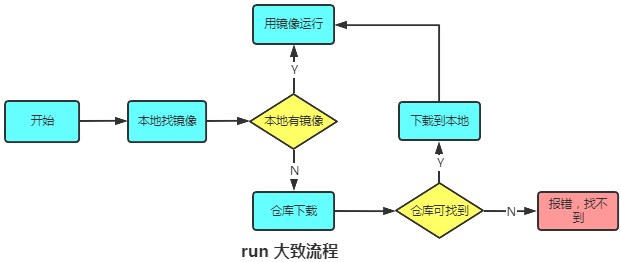
1.6 hello world
docker run hello-world 的大致流程图如下:
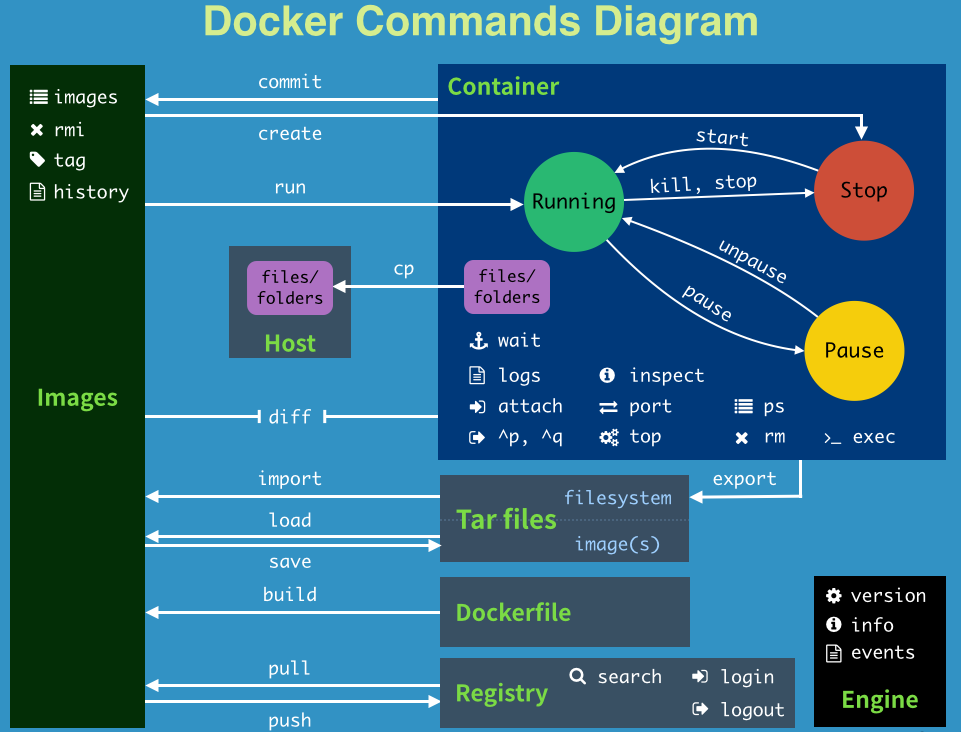
2 Docker 常见指令
官方文档:
https://docs.docker.com/engine/reference/commandline/build/
3 Docker 运行原理
Docker 只提供一个运行环境,他跟 VM 不一样,是不需要运行一个独立的 OS,容器中的系统内核跟宿主机的内核是公用的。docker容器本质上是宿主机的进程。对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程做如下操作:
启用 Linux Namespace 配置。
设置指定的 Cgroups 参数。
切换进程的根目录(Change Root),优先使用 pivot_root 系统调用,如果系统不支持,才会使用 chroot。
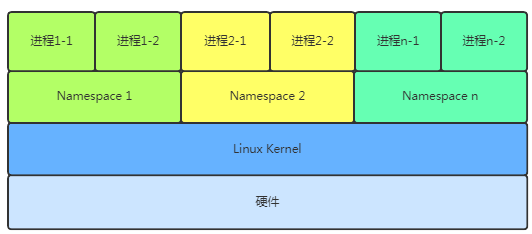
3.1 namespace 进程隔离
Linux Namespaces 机制提供一种进程资源隔离方案。PID、IPC、Network 等系统资源不再是全局性的,而是属于某个特定的Namespace。每个namespace下的资源对于其他 namespace 下的资源都是透明,不可见的。系统中可以同时存在两个进程号为0、1、2的进程,由于属于不同的namespace,所以它们之间并不冲突。
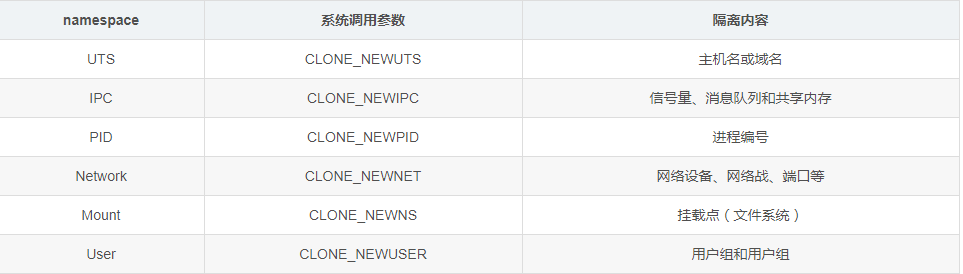
PS:Linux 内核提拱了6种 namespace 隔离的系统调用,如下图所示。
3.2 CGroup 分配资源
Docker 通过 Cgroup 来控制容器使用的资源配额,一旦超过这个配额就发出OOM。配额主要包括 CPU、内存、磁盘三大方面, 基本覆盖了常见的资源配额和使用量控制。
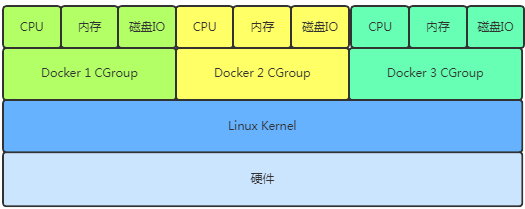
Cgroup 是 Control Groups 的缩写,是Linux 内核提供的一种可以限制、记录、隔离进程组所使用的物理资源(如 CPU、内存、磁盘 IO 等等)的机制,被 LXC(Linux container)、Docker 等很多项目用于实现进程资源控制。Cgroup 本身是提供将进程进行分组化管理的功能和接口的基础结构,I/O 或内存的分配控制等具体的资源管理是通过该功能来实现的,这些具体的资源 管理功能称为 Cgroup 子系统。
3.3 chroot 跟 pivot_root 文件系统
chroot(change root file system)命令的功能是 改变进程的根目录到指定的位置。比如我们现在有一个$HOME/test目录,想要把它作为一个 /bin/bash 进程的根目录。
首先,创建一个HOME/test/{bin,lib64,lib} 把bash命令拷贝到test目录对应的bin路径下 cp -v /bin/{bash,ls} $HOME/test/bin 把bash命令需要的所有so文件,也拷贝到test目录对应的lib路径下 执行chroot命令,告诉操作系统,我们将使用HOME/test /bin/bash
ls / 返回的都是$HOME/test目录下面的内容,Docker就是这样实现容器根目录的。为了能够让容器的这个根目录看起来更真实,一般在容器的根目录下挂载一个完整操作系统的文件系统,比如Ubuntu16.04的ISO。这样在容器启动之后,容器里执行ls /查看到的就是Ubuntu 16.04的所有目录和文件。容器镜像。更专业的名字叫作:rootfs(根文件系统)。所以一个最常见的 rootfs 会包括如下所示的一些目录和文件:$ ls /
bin dev etc home lib lib64 mnt opt proc root run sbin sys tmp usr var
3.4 一致性
打包操作系统的能力,这个最基础的依赖环境也终于变成了应用沙盒的一部分。这就赋予了容器所谓的一致性:无论在本地、云端,还是在一台任何地方的机器上,用户只需要解压打包好的容器镜像,那么这个应用运行所需要的完整的执行环境就被重现出来了。
3.5 UnionFS 联合文件系统
$ tree
.
├── fruits
│ ├── apple
│ └── tomato
└── vegetables
├── carrots
└── tomato
$ mkdir mnt
$ sudo mount -t aufs -o dirs=./fruits:./vegetables none ./mnt
$ tree ./mnt
./mnt
├── apple
├── carrots
└── tomato
$ echo mnt > ./mnt/apple
$ cat ./mnt/apple
mnt
$ cat ./fruits/apple
mnt
$ echo mnt_carrots > ./mnt/carrots
$ cat ./vegetables/carrots
old
$ cat ./fruits/carrots
mnt_carrots
在mount aufs命令时候,没有对 vegetables 跟 fruits 设置权限,默认命令行上第一个的目录是可读可写的,后面的全都是只读的。有重复的文件名,在mount命令行上,越往前的被操作的优先级越高。
3.6 layer 分层
rw 表示可写可读read-write。 ro 表示read-only,如果你不指权限,那么除了第一个外,ro是默认值,对于ro分支,其永远不会收到写操作,也不会收到查找whiteout的操作。 rr 表示 real-read-only,与read-only不同的是,rr 标记的是天生就是只读的分支,这样,AUFS可以提高性能,比如不再设置inotify来检查文件变动通知。
$ tree
.
├── fruits
│ ├── apple
│ └── tomato
├── test #目录为空
└── vegetables
├── carrots
└── tomato
$ mkdir mnt
$ mount -t aufs -o dirs=./test=rw:./fruits=ro:./vegetables=ro none ./mnt
$ ls ./mnt/
apple carrots tomato
.wh.apple,你就会发现 ./mnt/apple 这个文件就消失了,跟执行了 rm ./mnt/apple 是一样的结果:$ touch ./test/.wh.apple
$ ls ./mnt
carrots tomato
/var/lib/docker/aufs/diff目录下,然后通过查询/sys/fs/aufs 查看被联合挂载在一起的各个层的信息,多个基础层最终被联合挂载在/var/lib/docker/aufs/mnt里面,这里面存储的就是一个成品。3.6.1 只读层
docker image inspect ubuntu:latest 会发现容器的rootfs最下面的四层,对应的正是ubuntu:latest镜像的四层。它们的挂载方式都是只读的(ro+wh),都以增量的方式分别包含了Ubuntu操作系统的一部分,四层联合起来组成了一个成品。3.6.2 可读写层
3.6.3 init 层
-init结尾的层,夹在只读层和读写层之间。Init层是Docker项目单独生成的一个内部层,专门用来存放 /etc/hosts 等信息。
4 Docker 网络
docker network ls会发现它会自动创建三个网络。[root@server1 ~]$ docker network ls
NETWORK ID NAME DRIVER SCOPE
0147b8d16c64 bridge bridge local
2da931af3f0b host host local
63d31338bcd9 none null local

4.1 Host 模式
4.2 Container 模式
4.3 None 模式
4.4 Bridge 模式
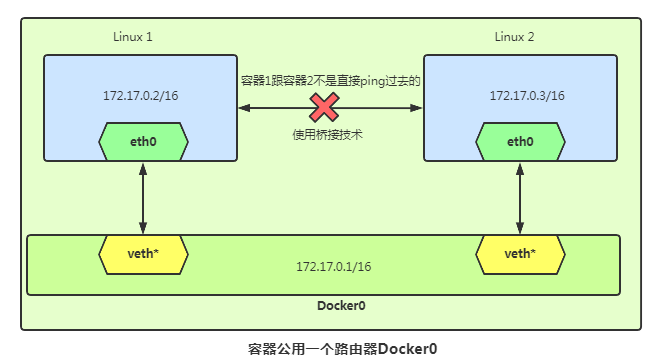
在主机上创建一对虚拟网卡 veth pair 设备。veth设备总是成对出现的,它们组成了一个数据的通道,数据从一个设备进入,就会从另一个设备出来。因此veth设备常用来连接两个网络设备。 Docker 将 veth pair 设备的一端放在新创建的容器中,并命名为eth0。另一端放在主机中,以veth65f9 这样类似的名字命名,并将这个网络设备加入到docker0网桥中,可以通过brctl show命令查看。 从 docker0 子网中分配一个IP给容器使用,并设置 docker0 的IP地址为容器的默认网关。
容器访问外部
假设主机网卡为eth0,IP地址10.10.101.105/24,网关10.10.101.254。从主机上一个IP为172.17.0.1/16 的容器中ping百度(180.76.3.151)。首先IP包从容器发往自己的默认网关 docker0,包到达docker0后,会查询主机的路由表,发现包应该从主机的 eth0 发往主机的网关10.10.105.254/24。接着包会转发给eth0,并从eth0发出去。这时Iptable规则就会起作用,将源地址换为 eth0 的地址。这样,在外界看来,这个包就是从10.10.101.105上发出来的,Docker容器对外是不可见的。
外部访问容器
创建容器并将容器的80端口映射到主机的80端口。当我们对主机 eth0 收到的目的端口为80的访问时候,Iptable规则会进行DNAT转换,将流量发往172.17.0.2:80,也就是我们上面创建的Docker容器。所以,外界只需访问10.10.101.105:80就可以访问到容器中的服务。
4.5 --link
docker run -d -P --name linux03 --link linux02 linux
docker exec -it linux03 ping linux02 可ping通。
docker exec -it linux02 ping linux03 不可ping通。
172.17.0.3 linux03 12ft4tesa # 跟Windows的host文件一样,只是做了地址绑定
4.6 自建Bridge
docker run -d -P --name linux01 LinuxSelf
docker run -d -P --name linux01 --net bridge LinuxSelf
# --driver bridge 网络模式定义为 :桥接
# --subnet 192.168.0.0/16 定义子网 ,范围为:192.168.0.2 ~ 192.168.255.255
# --gateway 192.168.0.1 子网网关设为: 192.168.0.1
docker network create --driver bridge --subnet 192.168.0.0/16 --gateway 192.168.0.1 mynet
docker run -d -P --name linux-net-01 --net mynet LinuxSelf
docker run -d -P --name linux-net-02 --net mynet LinuxSelf
docker exec -it linux-net-01 ping linux-net-02的IP # 结果OK
docker exec -it linux-net-01 ping linux-net-02 # 结果OK
5 可视化界面
5.1 Portainer
5.2 DockerUI
5.3 Shipyard
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️