
Docker内核技术原理之Namespace


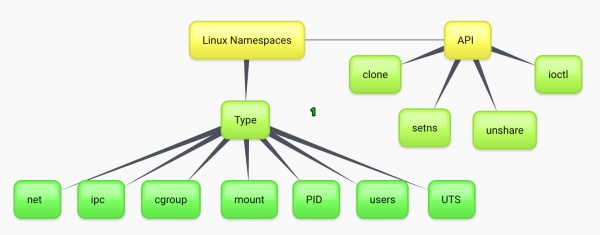
Docker的空间隔离使用的是namespace(空间),它是内核提供的一种空间隔离,在一个空间下,每个进程看到的视图是一致的,相应的如果不在一个空间下看到资源视图是不一致的,举个例子,如果两个进程在同一个网络命名空间下,那么他们看到的网络信息(网卡、IP、路由等)是一样的,可以通过localhost的方式互相访问。常用的有6种namespace,在Linux 内核4.6之后又添加了Cgroup这namespace,5.6 之后又添加了时钟namespace。
| Namespace | 系统调用参数 | 隔离内容 |
|---|---|---|
| UTS | CLONE_NEWUTS | 主机名与域名 |
| IPC | CLONE_NEWIPC | 信号量、消息队列和共享内存 |
| PID | CLONE_NEWPID | 进程编号 |
| Network | CLONE_NEWNET | 网络设备、网络栈、端口等等 |
| Mount | CLONE_NEWNS | 挂载点(文件系统) |
| User | CLONE_NEWUSER | 用户和用户组 |
| Cgroup | CLONE_NEWCGROUP | Cgroup的根目录 |
| Time | CLONE_NEWTIME | 时钟 |
这里有个小细节,上面表格创建Mount Namespace的系统调用参数是CLONE_NEWNS,而不是CLONE_NEWMOUNT。从字面理解是创建一个命名空间的意思,这是由于历史原因导致的,因为Mount Namespace是第一个namespace,内核的开发者可能也没有预料到后续还有其它的namespace的加入,所以就先把CLONE_NEWNS给占用了。
可见,namespace的隔离其实并不充分,除了上面的隔离能力,其他的都一样。譬如,时钟在内核5.6版本之前,所有容器和操作系统都共享同一个时钟,如果修改了操作系统的时间,所有容器都时间都会变化。
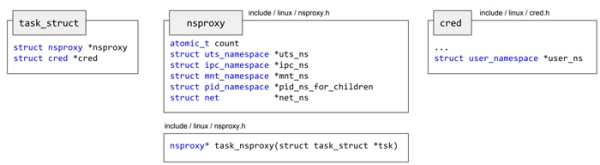
namespace实现原理也非常简单,每个进程(task_struct)都有一个关于namespace的属性nsproxy,表示自己所属的namespace。
struct task_struct { ...
/* namespaces */
struct nsproxy *nsproxy;
...
}
其中的nsproxy就是指向各种namespace的一个代理。如下所示:
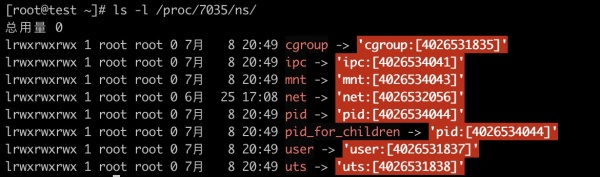
当新进程被创建后会继承其父进程的namespace,这就是为啥一个容器里面的所有进程都共享namespace。在Linux集群上面,通过读取“/proc/进程ID/ns/”下的文件可以获取到每个进程对应的namespace。
(版权归原作者所有,侵删)
![]()

点击下方“阅读原文”查看更多