
使用Tesseract做文字识别(OCR)
共 2342字,需浏览 5分钟
·
2022-02-09 17:41
前言
OCR(optical character recognition,光学字符识别)是指直接将包含文本的图像识别为计算机文字(计算机黑白点阵)的技术。图像中的文本一般为印刷体文本。
Tesseract是github上的OCR开源库,今天我将使用Tesseract来进行文字识别。
安装Tesseract
安装Tesseract挺简单的,直接按照官网上安装方法安装即可。安装完记得配一下环境变量。
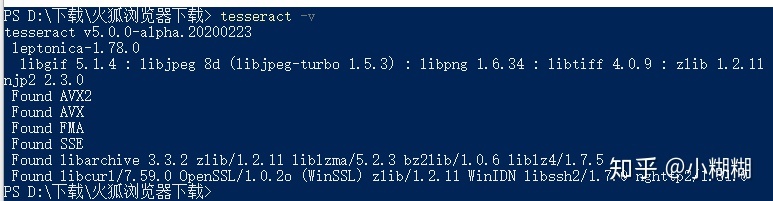
Tesseract官网我是在Win10下安装的,打开命令行,输入tesseract -v查看Tesseract版本号,输出以下信息表示安装成功:

用Tesseract做文字识别
现在我使用Tesseract来识别下面图片中的字符:


命令行运行:(指定简体中文)
tesseract 5.png stdout -l chi_sim输出如下:


可以看到,Tesseract很好的识别了图片中的文字。
上面的测试用例背景十分干净,对比明显,Tesseract识别得很好,但是现实中的图片可能没有这么好的条件,直接识别可能会出错,往往要先进行图像处理,然后将处理后的图片送入Tesseract文字识别。
Python中使用Tesseract
Python安装Tesseract接口:
pip install pillow
pip install pytesseract注意:Python只是提够了调用Tesseract的接口,方便我们在Python程序中使用Tesseract,实际运行的还是前面安装的Tesseract库。
使用以下代码测试:
# USAGE
# python ocr.py --image images/example_01.png
# python ocr.py --image images/example_02.png --preprocess blur
# import the necessary packages
from PIL import Image
import pytesseract
import argparse
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
ap.add_argument("-p", "--preprocess", type=str, default="thresh",
help="type of preprocessing to be done")
args = vars(ap.parse_args())
# load the example image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Image", gray)
# check to see if we should apply thresholding to preprocess the
# image
if args["preprocess"] == "thresh":
gray = cv2.threshold(gray, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# make a check to see if median blurring should be done to remove
# noise
elif args["preprocess"] == "blur":
gray = cv2.medianBlur(gray, 3)
# write the grayscale image to disk as a temporary file so we can
# apply OCR to it
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
# load the image as a PIL/Pillow image, apply OCR, and then delete
# the temporary file
text = pytesseract.image_to_string(Image.open(filename))
os.remove(filename)
print(text)
# show the output images
# cv2.imshow("Image", image)
cv2.imshow("Output", gray)
cv2.waitKey(0)上面的Python脚本对输入图像先进行了简单的图像处理,比如模糊和二值化。然后将处理后的图片使用tesseract进行文字识别。
测试图片1为:


命令行运行:
python ocr.py --image images/example_01.png经过阈值分割后的图像如下,可以看到把背景阴影很好的去掉了:


命令行输出如下,正确的识别了结果。

总结
直接使用tesseract识别图片文字容易出错,一般先对图片做图像处理后再使用tesseract识别文字。