
【深度】未来5-10年计算机视觉发展趋势为何?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:计算机视觉联盟

计算机视觉是人工智能的“眼睛”,是感知客观世界的核心技术。进入21世纪以来,计算机视觉领域蓬勃发展,各种理论与方法大量涌现,并在多个核心问题上取得了令人瞩目的成果。为了进一步推动计算机视觉领域的发展,CCF-CV组织了RACV 2019,邀请多位计算机视觉领域资深专家对相关主题的发展现状和未来趋势进行研讨。
1. 查红彬

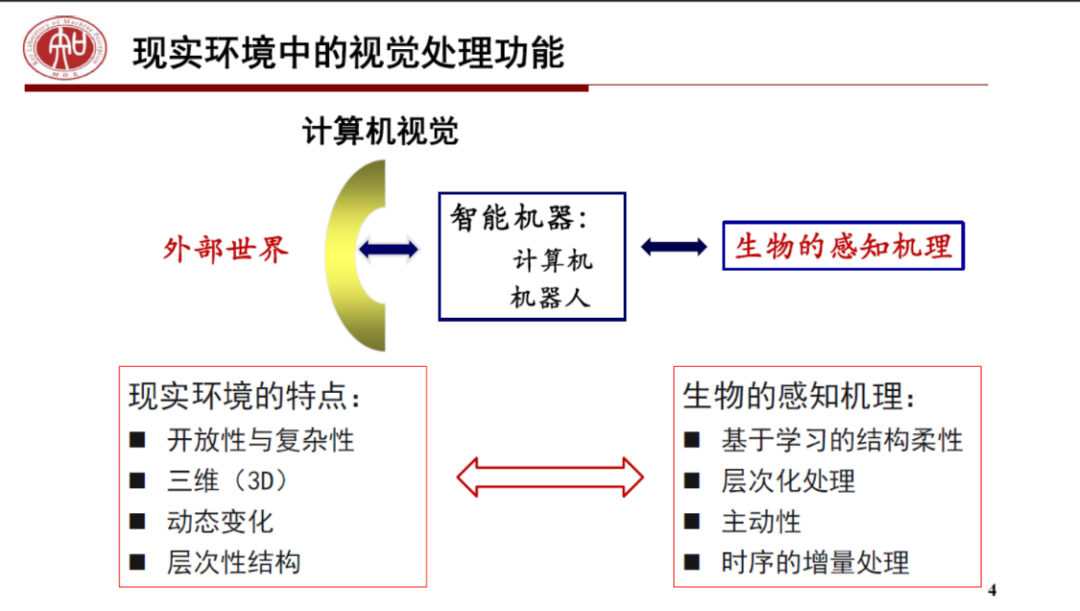

2. 陈熙霖

3. 卢湖川
4. 刘烨斌

5. 章国锋



交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论