
AMD高级副总裁专访:GPU也将进入Chiplet时代!
6月24日消息,近日,外媒Tomshardware采访了AMD 高级副总裁、企业研究员兼产品技术架构师 Sam Naffziger,就AMD近年来在CPU、GPU以及Chiplet技术上的探索进行了分享。
AMD 最近提供了有关其即将推出的RDNA 3 GPU架构的一些诱人细节,该架构将采用Navi 3x核心,5nm工艺,采用基于Chiplet设计,计划在今年年底前推出。因此,Tomshardware的采访也主要围绕着GPU与Chiplet展开。
Sam Naffziger拥有超过33年的行业经验,曾在惠普、英特尔和AMD从事微处理器和电路设计。他拥有加州理工学院(CalTech)的电气工程学士学位和斯坦福大学的理学硕士学位并在该领域拥有130多项美国专利,并撰写了数十篇关于处理器、架构和电源管理的出版物和演讲。同时,他还是IEEE院士。

目前,Sam Naffziger已经在 AMD 工作了 17 年,负责多个产品领域,专注于推动更高的每瓦性能以及提升 AMD CPU 和 GPU 的整体竞争力。他也是 AMD Chiplet架构背后的主要人物之一,该架构在 Ryzen 和 EPYC CPU 系列中已被证明非常成功,现在将以某种形式出现在 AMD RDNA 3 显卡中。Naffziger 概述了公司面临的挑战,以及他认为创新技术(如基于小芯片的 GPU 架构)如何提高性能和能效。
对于Chiplet设计不了解的朋友,可以先观看此前的文章《后摩尔时代的“助推剂”:Chiplet到底有何优势,挑战又有哪些?》,以便于理解。
撞上功率墙
对于现代微处理器核心的设计来说,性能和功耗问题正变得越来越棘手,没有一家公司能幸免于副作用。所有迹象都表明下一代 GPU 会增加功耗:PCIe 5.0 电源接口和即将推出的支持它的电源可以通过单个 16 针连接器提供高达 600W 的功率,预示着更广泛的行业转向更高功率的 GPU。
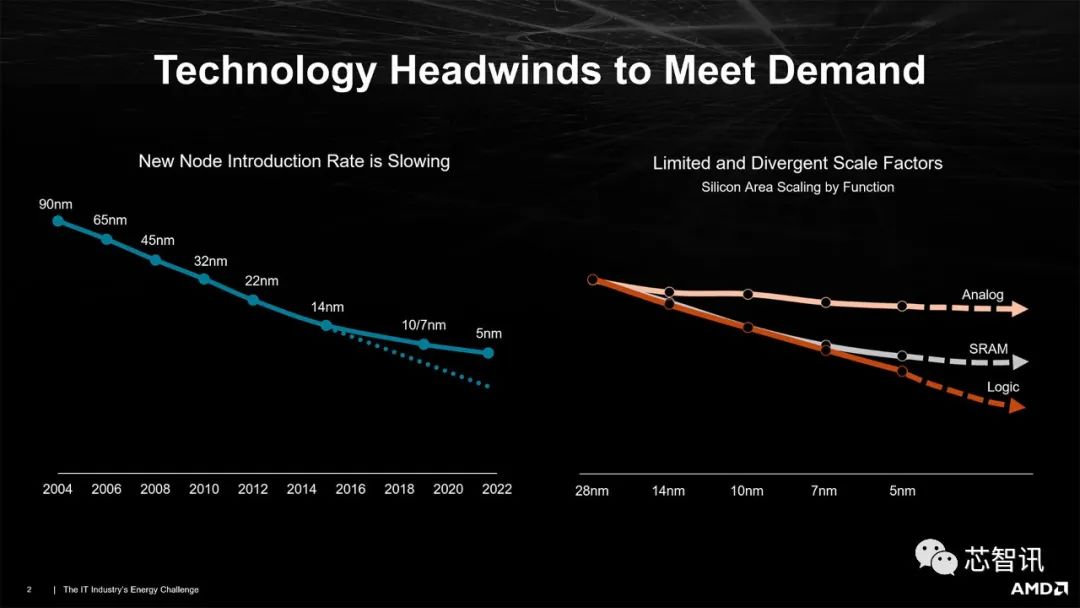
众所周知,Nvidia(英伟达)的 Ada 架构将推动比我们过去看到的更高的功率限制——目前的传闻表明,我们可能会看到 450W TBP(典型的主板功率),甚至可能会看到顶级 RTX 40 系列的 600W TBP GPU。目前还没有关于 AMD RDNA 3 的 TBP 的消息,但公平地认为他们可以遵循同样的趋势。
因此,此次采访集中在 AMD 提高效率的方法上,但总体功耗问题仍然存在。Naffziger 证实我们可以预期下一代 GPU 的总功耗会增加,但解释了关注效率如何可以最大限度地提高性能。
Naffziger 解释说:“物理学的基本原理持续推动功率的上升。用户对游戏和计算性能的需求正在加速,与此同时,底层的半导体制程工艺技术的推进正在显着放缓。因此,功率水平会继续上升。但我们的改进速度也在加快。现在,我们有一个多年的路线图,有着非常显着的效率改进来抵消这条曲线,但功率上升的趋势确实在那里。”
AMD 声称 RDNA 和 RDNA 2 的每瓦性能提高了 50%,并且它的目标是使用 RDNA 3 将每瓦性能再提高50%。即在相同功耗下,性能提高50%;或者相同的性能下,功耗降低33%。需要注意的是。与 Nvidia 和英特尔一样,AMD需要在特定的场景下,才能达到每瓦特的性能提高50%的效果。

Naffziger 解释了 AMD 在其先前的 RDNA 2 架构中看到的一些改进。例如,如果它可以在 2.5 GHz 和 1.0V 而不是 1.2V 下运行,而后者需要多 40% 的功率。
Naffziger 表示,通过利用其 CPU 设计团队的专业知识,AMD 能够通过 RDNA 3 驱动更高的时钟频率,同时保持高效。
AMD 长期以来一直在讨论其CPU 和 GPU 设计团队的“cross-pollinating”战略,将双方最好的技术带到每个新的 CPU 和 GPU 设计中。Naffziger 表示,当前的 GPU 内核“本质上更节能”,但仍需要根据市场做出对应的商业决策。
Naffziger 说:“性能为王,即使我们的设计更节能,这并不意味着如果竞争对手在做同样的事情,你就不会提高功率水平。只是他们可能会有把他们功率推得比我们要高得多。”
换句话说,如果与 Nvidia 类似的 AMD 最终增加其顶级 RDNA 3 显卡的 TBP,请不要感到惊讶。
功率效率和每瓦性能
面对摩尔定律推进速度放缓的根本挑战,必须通过巧妙的工程和对功率效率的关注来抵消,而 AMD 在这一领域已经证明了自己。
目前,AMD 的 Zen 3 CPU 在效率和每瓦性能方面普遍领先于英特尔,不过我们必须看看Zen 4和Ryzen 7000的变化。此外,AMD 的 RDNA 2 GPU 在效率方面也倾向于击败竞争对手 Nvidia 的 GPU,具体取决于比较的具体型号。这一点至关重要,因为近年来我们已经看到更高功率的 CPU 和 GPU 迅速升级,从而导致更高的发热量和昂贵的冷却解决方案。
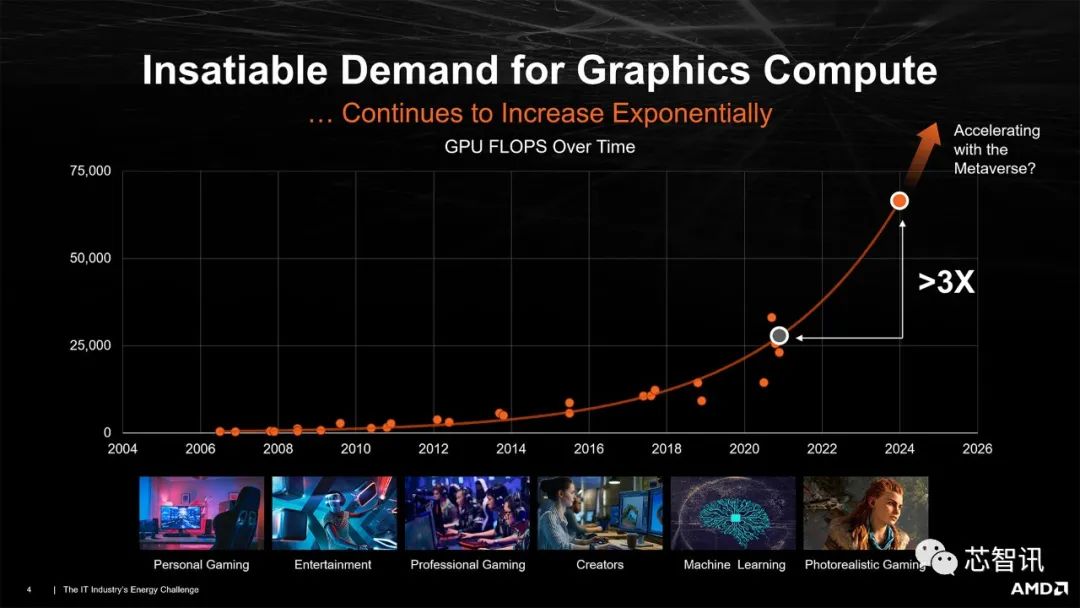
具体来看 AMD 过去两代的图形显卡,与上一代 Vega 和 Polaris 架构相比,RDNA 1 在 2019 年的每瓦性能明显提高了 50% 或更多。例如,GPU 基准层次结构测试结果表明,RX 5700 XT 在Tomshardware的 1080p测试套件中平均为 74 fps,同时消耗 214W,而 RX Vega 64 消耗了 298W却只达到了 57 fps的成绩——这实际上意味着AMD在提高了 80%的每瓦性能。
与 RDNA 1 相比,2020 年的 RDNA 2 能够再次提供高达 50% 的每瓦性能提升。当然这也是在特定场景下的结果。例如,RX 6600 在 1080p 分辨率下平均 67 fps,消耗 137W,比 RX 5700 XT 效率高 41%。同时,RX 6700 XT 在使用 215W 时提供 96 fps,仅提升 30% 的纯效率,而 RX 6800 XT 达到 124 fps 并使用 303W,仅提升 18% 的效率。然而,RX 5500 XT 8GB 的平均速度为 40 fps,功率为 126W,因此 RX 6600 至少在某些情况下效率提高了 54%——而且使用了类似的 128 位内存接口。
更令人印象深刻的是,这些收益都是在工艺节点没有变化的情况下实现的,因为 RDNA 1 和 RDNA 2 都使用了台积电的 7nm N7 技术(尽管一些较新的 GPU,如 Navi 24 现在使用 N6)。
AMD此前在其财务分析师日宣布,它再次致力于利用一组新功能,通过 RDNA 3 将每瓦性能提高 50%。我们知道Chiplet设计将成为其中的重要组成部分。Naffziger 还暗示将进一步优化 Infinity Cache 设计,以提高其有效带宽和命中率。不过,确切的细节仍在保密中。
在 CPU 方面,随着 Zen 2 和后来的 Zen 3,AMD 将内存控制器和 PCIe 通道放在称为 I/O 芯片的中央小芯片上,以及用于与封装内的其他小芯片通信的高带宽接口,称为“Infinity Fabric”。到目前为止,这些其他小芯片包括 CPU内核及其关联的缓存,以及小芯片的共享 L3 缓存。
对于消费类 CPU,AMD 发布了带有一个或两个 CPU 小芯片的处理器,每个小芯片最多可以启用八个 CPU 内核。然而,AMD 不仅仅创建了一个 I/O 小芯片,它还希望扩展到多达 8 个 CPU 小芯片。消费类 I/O 芯片只有两个 CPU 芯片的 Infinity Fabric 链接,EPYC 和 Threadripper 变体可以链接多达八个 CPU 芯片,提供多达 64 核 CPU,如 Threadripper Pro 5995WX 和 EPYC 7763。
RDNA 3 也将采用Chiplet设计
AMD 自 Fiji 架构和 R9 Fury X 以来一直在使用小芯片封装技术。这是第一款使用 HBM(高带宽内存)的产品,其硅中介层有助于将主GPU 核心和 HBM 堆栈。
因此,Tomshardware进一步澄清了 GPU 的“Chiplet”的定义,以避免AMD 不是将HBM作为Chiplet设计中的小芯片。对此,Naffziger则证实,RDNA 3 确实会有单独的小芯片(不是HBM内存芯片),尽管他没有具体确定 AMD 将如何对原有的单片GPU进行拆分。
Naffziger 并没有对下一代 RDNA 3 架构透露太多,不过可以猜测的是,AMD 的 GPU中的Chiplet设计最终可能会类似当前的AMD CPU 设计,它将拥有容纳计算的 GPU 小芯片单元 (CU)、着色器核心和一些缓存,然后将至少有两种 I/O 小芯片设计,一种可以通过更宽的内存接口扩展到更高的小芯片数量,另一种可能只支持最多两个具有更窄接口的 GPU 小芯片。AMD 将通过更新的 Infinity Fabric 链接小芯片,并且它可能会在 I/O 小芯片上拥有适度的缓存块,以帮助优化内存访问。
AMD其在2019年推出的Zen 2 CPU产品线中,就开始全面采用Chiplet架构,其芯片设计最大的特色为将 I/O模块与逻辑运算模块分离,I/O模块继续延用12nm工艺,而逻辑运算模块则是采用7nm工艺。这也使得AMD的CPU实现了出色的规模经济。
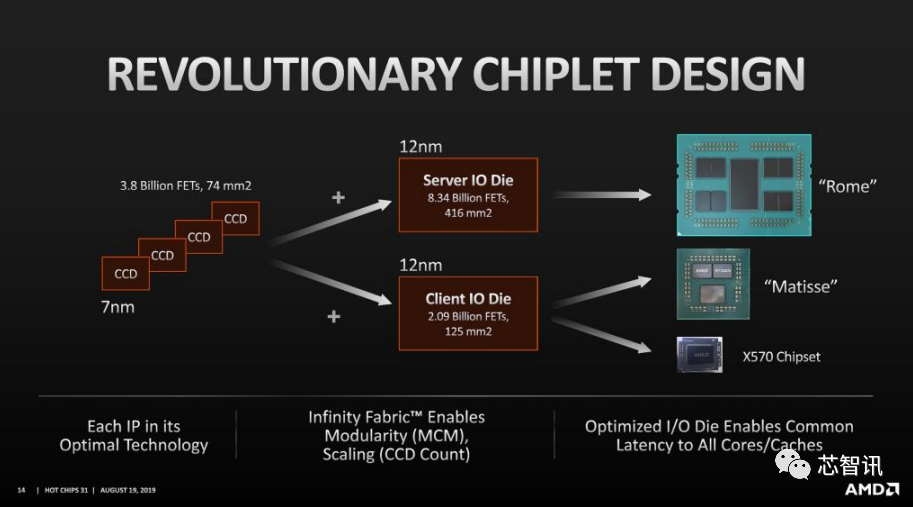
同样,在Zen 3 CPU设计上,CPU逻辑核心依然是使用台积电的7nm节点,而I/O芯片仍使用格芯的12nm工艺。
Zen 3 的逻辑计算核心中包含8个CPU内核和一个统一的 32MB 三级缓存,但它面积大小仍然只有84平方毫米——不到英特尔Alder Lake 酷睿i9-12900K芯片约 215 平方毫米面积的一半,也几乎是拥有较小的六个P核的Alder Lake-s的约163mm平方毫米面积一半。
随后,AMD在其顶级CPU解决方案中也采用了多达8个小芯片的Chiplet设计,考虑到芯片尺寸,收益率会非常高。
对于 GPU,如果 AMD 抽出所有显示接口功能、视频编解码器、内存接口和其他通用硬件,只专注于计算单元,不难想象 AMD 会创建一个具有 40 CU 芯片的构建块,具有2560 个(也可能是 5120 个)着色器内核和 32–64MB 的 L3 缓存,以及AMD的 Infinity Fabric 高速总线接口。
拿 Navi 22 (RX 6700 XT)举例来说,这是一个 335平方毫米的芯片,将其I/O部分单独拿出来制造成小芯片,大约需要一半的大小的面积。然后通过台积电的 5nm N5P 节点制造剩余的GPU核心的CU,可以得到一个小于100 平方毫米的小芯片,最后将其封装在一起。这样收益率将会很高。对于消费领域,AMD 可能拥有多达四个这样的小芯片的解决方案。
I/O 小芯片将是一个完全不同的模块。它将容纳外部存储器接口,因此,它实际上可以通过不在前沿节点上而受益,这意味着 AMD 可以在 N7 或 N6 上而不是 N5 上制造它。I/O 接口往往不能很好地扩展到更小的制程工艺节点,而外部接口通常需要更高的电压,这会给新节点带来设计挑战。AMD 不必在基于稍旧工艺的 I/O 芯片上处理这么多的问题——它已经拥有来自各种 RDNA 2 设计的现有 GDDR6 接口,这些接口经过测试可以直接适用于台积电的7nm工艺。

△AMD 的 EPYC(霄龙)CPU 具有围绕中央 I/O 小芯片的多达 8 个 CPU 小芯片。(图片来源:AMD)
I/O 小芯片的主要症结在于扩展到各种目标市场。具有 8 个小芯片的服务器CPU的最大配置似乎是合理的,但 AMD 已将其面向消费者和数据中心的GPU设计分别分为 RDNA 和 CDNA。
我们已经知道CDNA 3 和即将推出的 Instinct MI300 APU 的一些内容,它们也将与 Zen 4 CPU 一起用于El Capitan 超级计算机。RDNA 3 将完全不同,就像 RDNA 2 和 CDNA 2 一样。简而言之,预计 AMD 不会像 RDNA 3 那样为 CDNA 3 使用类似的设计,因此可能不需要扩展到八个 GPU 小芯片。
相反,AMD 可以创建两个 I/O 小芯片,一个用于低端和中端显卡,另一个用于高端和超高性能显卡。同时,所有 GPU 小芯片都将采用相同的核心设计。这仍然是当前 RDNA 2 阵容的简化,AMD 已经拥有四个独立的芯片(Navi 21、22、23 和 24),更不用说所有集成的 RDNA 2 解决方案,如 Rembrandt 和 Van Gogh(Steam Deck 处理器) 。
AMD 可以在较小的 I/O 小芯片上放置一个 128 位内存接口,为低层产品提供功能强大的 64 位或 96 位变体,并能够链接到两个 GPU 计算小芯片。更大的高端解决方案可能具有 256 位内存接口(甚至可能高达 384 位),具有针对较低产品层的缩减选项,以及连接四个甚至更多 GPU 小芯片的能力。
这听起来可能更复杂而不是更简单,但会有一些很大的优势。首先,I/O 小芯片可以采用老一点的制程工艺节点,这将降低成本,而 AMD 已经非常熟悉 N7 和 N6 产品的设计。较小的 I/O 小芯片最终可能会得到大约 150 平方毫米的裸片尺寸(给或取),仍然比 Navi 23 小,然后它可以根据需要连接一个或两个 GPU 小芯片。更大的 I/O 芯片可能约为 225 平方毫米,并且可以连接三个或四个相同的 GPU 小芯片。
在任何一种情况下,总的组合芯片面积不会比单片设计差多少,但实际效益却要高得多。AMD 将把其 5nm 生产集中在 GPU 小芯片设计上,并使用较便宜的 N6 或 N7 工艺来生产 I/O 小芯片。唯一的诀窍就是让它们一起正常工作,并通过更多的 GPU 小芯片来扩展性能。
其他 RDNA 3 架构细节
除了小芯片架构之外,Tomshardware还从与 Naffziger 的对话中收集了有关 RDNA 3 的其他一些细节。
比如,AMD 是否会在架构中包含某种形式的张量核心或矩阵核心,类似于 Nvidia 和英特尔在其 GPU 上所做的事情。
Naffziger回应说,RDNA 和 CDNA 之间的分离意味着将一堆专用矩阵内核塞入消费图形产品对于目标市场来说确实不是必需的,而且以前 RDNA 架构中已经存在的 FP16 支持应该足以满足推理类型的工作负载。我们将看看这是否被证明是正确的,但 AMD 似乎满足于将机器学习留给其 CDNA 芯片。

另一个问题是关于 Infinity Cache 的大小。RDNA 2 的缓存大小从 Navi 21 上的 128MB 到 Navi 24 上的低至 16MB 不等,即使使用较小的缓存大小,由此带来的性能提升仍然令人印象深刻。
对于标准 GPU 小芯片,AMD 最终可能会放弃 16MB 缓存并使用 32MB ,或者它可能会使用更大的缓存大小——或者在 I/O 小芯片和 GPU 小芯片中都有缓存。无论采用何种方法,Naffziger 都暗示 AMD 已经学会了优化缓存使用的更好方法的设计决策,包括排除某些不会从缓存中受益的事物(Naffziger 提到显示界面、多媒体处理和音频处理是也许不要。)
尾声
最终,在像 RDNA 3 这样的架构中需要平衡很多因素。采用Chiplet设计在规模经济方面具有优势,并且允许 AMD 比其他方式更快地迁移到最新的先进制程的节点,但这也有缺点,对四处移动的数据有更高的功率要求。
在 Infinity Fabric 上移动数据会带来功率消耗,并且在所有其他因素相同的情况下,与单片芯片设计相比,基于Chiplet设计的架构在数据遍历期间会损失一些效率。因此,必须注意确保平衡设计。AMD 一直处于Chiplet设计的最前沿,Ryzen CPU 在过去三年中一直在使用它们,而 EPYC 和 Threadripper 从 2017 年开始使用Chiplet设计。每一代都带来了性能和效率的提升。
虽然前面已经对 AMD RDNA 3的设计做出了一些有根据的猜测,但 Naffziger 对分享具体细节比较谨慎。
Tomshardware曾一度询问RDNA 3的Chiplet设计是否类似于 Aldebaran(两个大型芯片,具有快速接口连接它们),或者更像带有 I/O 小芯片和多个计算小芯片的 Ryzen CPU。对此,Naffziger表示,后一种方法是“合理的推断”,AMD 将以“一种非常特定于图形的方式”来开发基于Chiplet设计的 GPU 架构。
无论最终实施的具体细节如何,我们都期待在今年晚些时候看到 RDNA 3 投入使用。关于RDNA 3的传闻仍然充满了想法和可能性,包括每个计算单元的 FP32 管道数量可能翻倍。我们还想看看 AMD 是否仍能从最大 256 位内存接口中获得所需的带宽,以及下一代 Infinity Cache 的表现如何。
但最重要的是,我们希望看到代际表现的又一次大飞跃。AMD 专注于电源效率的方法,然后允许它在电压/频率曲线的较高端提取更多性能,这是一个合理的设计原则。当然,每种基本设计理念都有其优点和缺点,我们知道 Nvidia 也不会坐以待毙——当 RDNA 3 和 4 系列面世时,可以期待双方在性能和效能上的激烈竞争。
编辑:芯智讯-浪客剑
编译自:https://www.tomshardware.com/features/gpu-chiplet-era-interview-amd-sam-naffziger
前台积电厂长+前尔必达社长!昇维旭拟建12吋DRAM厂,计划2024年1季度试产
10Gbps!全球最快!国产最强LPDDR5/5X接口IP成功量产!
2021年全球NOR Flash市场:兆易创新收入暴增100%,份额升至23.2%!
台积电2nm细节曝光:功耗降低30%!成熟制程产能2025年将提升50%
行业交流、合作请加微信:icsmart01
芯智讯官方交流群:221807116