
仅用三张图,合成高质量的3D场景,NTU提出SparseNeRF

来源:机器之心
本文约2000字,建议阅读5分钟
最近,一些方法极大地改进了基于神经辐射场 NeRF 稀疏 3D 重建的性能。
随着深度学习与 3D 技术的发展,神经辐射场(NeRF)在 3D 场景重建与逼真新视图合成方面取得了巨大的进展。给定一组 2D 视图作为输入,神经辐射场便可通过优化隐式函数表示 3D。
然而,合成高质量的新视角通常需要密集的视角作为训练。在许多真实世界的场景中,收集稠密的场景视图通常是昂贵且耗时的。因此,有必要研究能够从稀疏视图中学习合成新视角图像且性能不显著下降的神经辐射场方法。
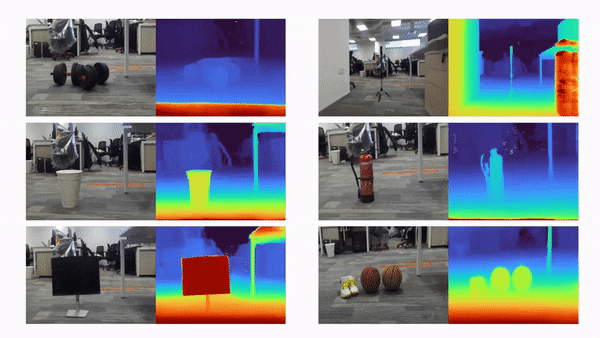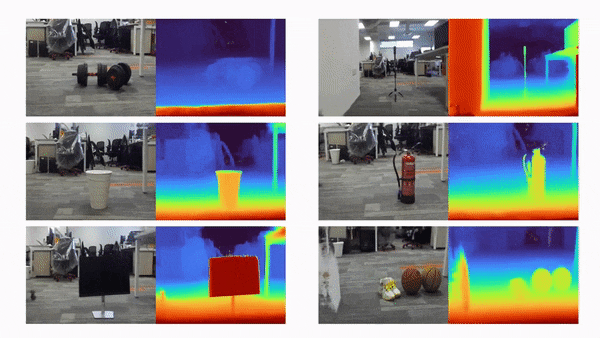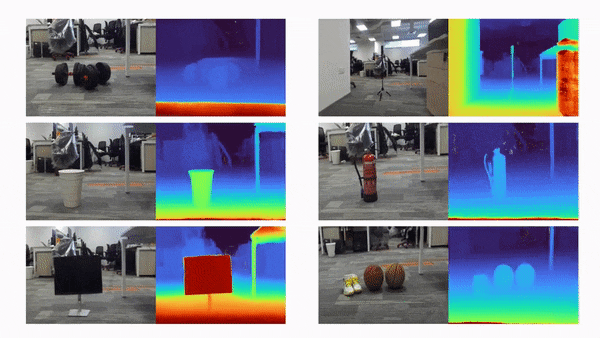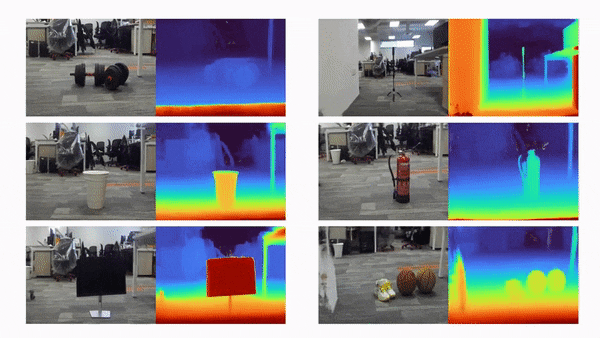
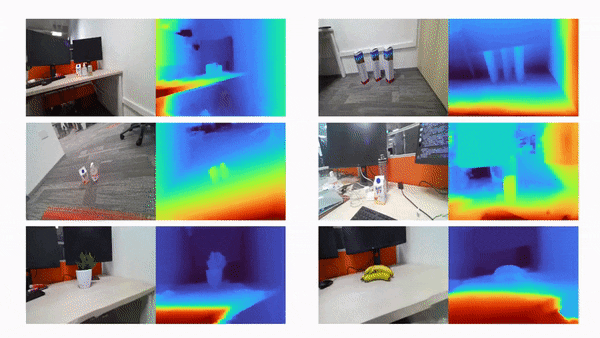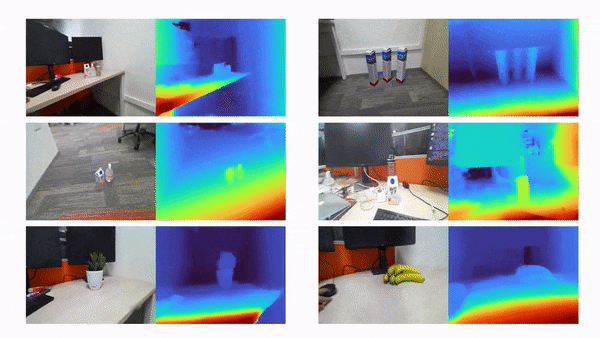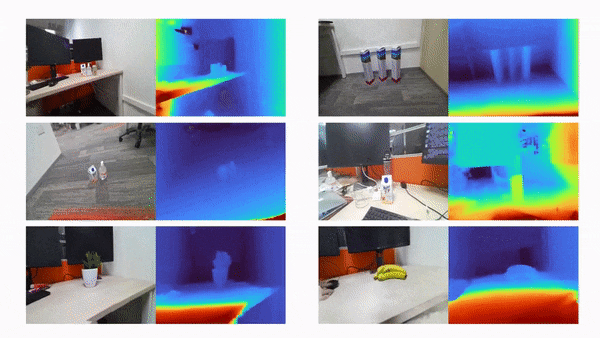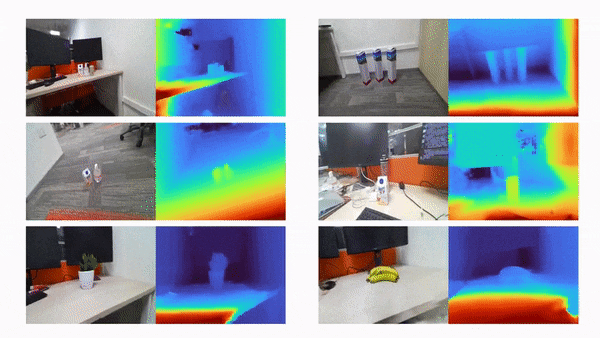
比如说,当输入只有三张视角图片时,我们希望可以训练出真实的 3D 场景,如下动图所示:

利用稀疏视图图像进行新视角合成是一个具有挑战性的问题,这是因为稀疏的 2D 视角不能为 3D 重建提供充足的约束条件,尤其是在纹理较少的区域,将 NeRF 直接应用于稀疏视角场景会导致严重的性能下降。
最近,一些方法极大地改进了基于神经辐射场 NeRF 稀疏 3D 重建的性能。这些方法可以分为三种:
(1) 第一种方法基于几何约束(稀疏性和连续性正则化)和语义约束。例如对不可见观察视点的渲染图像块的几何和外观添加正则约束,或者对每条光线的密度施加了熵约束和空间平滑约束。然而,由于一个场景通常具有复杂的布局,仅利用稀疏视图的几何约束稀疏性 / 连续性和语义不能保证高质量的三维重建。
(2)第二种方法依赖于相似场景的预训练。例如,提出通过卷积特征图表示从其他场景中学习高级语义,然后在目标场景进行微调。
(3)第三种方法利用额外深度信息进行约束,利用局部深度图块的线性不变性或者精准的稀疏点云来约束神经辐射场。例如,利用由 COLMAP 算法生成稀疏 3D 点直接约束,或者由高精度深度扫描仪和多视图立体匹配(MVS)算法获得的精准深度图,约束此深度图和预测的神经辐射场深度图线性不变,或者利用粗糙深度图块局部的尺度不变进行约束。然而在现实场景中,训练好的深度估计模型或消费级深度传感器获取的深度图通常较为粗糙。基于尺度不变的深度约束假设对于较为粗糙的深度图而言并不够鲁棒,而稀疏的点云数量通常不足与约束纹理较少的区域。
为此,我们希望从粗糙深度图中探索更鲁棒的 3D 先验,以补充稀疏视角重建中约束不充足的问题。为了解决这个问题,我们提出了基于神经辐射场的稀疏视角 3D 重建 SparseNeRF,这是一个简单但有效的方法,可以蒸馏粗糙深度图的鲁棒 3D 先验知识,提升稀疏视角 3D 重建的性能。该工作发表在ICCV 2023上。

项目主页:
https://sparsenerf.github.io/
代码:
https://github.com/Wanggcong/SparseNeRF
论文:
https://arxiv.org/abs/2303.16196
研究动机
从训练的深度估计模型或者消费级的深度传感器可以轻松获取真实场景的粗糙深度图,然而如何从这些粗糙深度图中提取鲁棒的深度线索尚未有充足的研究探索。虽然单视图深度估计方法在视觉性能方面取得了很好的表现(得益于大规模单目深度数据集和大型 ViT 模型),但由于粗糙的深度标注、数据集偏差等,它们无法产生精确的 3D 深度信息。这些粗糙的深度信息与神经辐射场 NeRF 在基于体素渲染的每个像素上重建场景时的密度预测存着不一致性。将粗糙深度图直接缩放用来监督 NeRF 无法获得很好的新视角合成效果。
方法框架
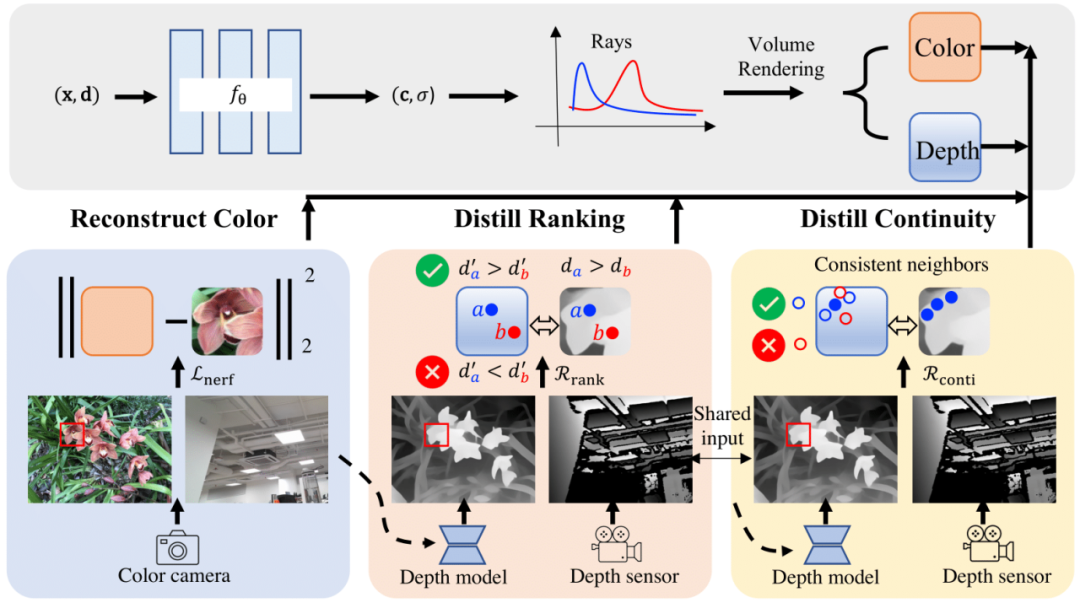
上图展示了我们方法的框架图。SparseNeRF 主要由四个组件组成,即神经辐射场(NeRF)、RGB 颜色重建模块、深度排序蒸馏模块和空间连续性蒸馏模块。具体而言,我们使用神经辐射场为主干网络,并对颜色重建使用 MSE 损失。对于深度先验蒸馏,我们从预训练深度估计模型中蒸馏深度先验。我们提出了局部深度排序正则化和空间连续性正则化,从粗糙深度图中蒸馏出鲁棒的深度先验。
具体而言,与直接用粗糙深度先验监督 NeRF 不同,我们放松了深度约束,从粗糙深度图中提取了鲁棒的局部深度排序,使得 NeRF 的深度排序与粗糙深度图的深度排序一致。也就是说,我们对 NeRF 进行相对深度监督而不是绝对深度监督。为了保证几何的空间连续性,我们进一步提出了一种空间连续性约束,让 NeRF 模型模仿粗糙深度图的空间连续性。通过有限数量的视图获取鲁棒的稀疏几何约束,包括深度排序正则化和连续性正则化,最终实现了更好的新视图合成效果。
值得注意的是,在推断期间,我们的方法 SparseNeRF 不会增加运行时间,因为它仅在训练阶段利用来自预训练深度估计模型或消费级传感器的深度先验(见图示框架)。此外,SparseNeRF 是一个易于集成到不同 NeRF 变种方法中的即插即用的模块。我们结合到 FreeNeRF 中验证了这个观点。
主要贡献
(1)提出了 SparseNeRF,一种简单但有效的方法,可以从预训练的深度估计模型中提取局部深度排序先验。通过局部深度排序约束,SparseNeRF 在基于稀疏视角的新视图合成方面显著地提高了性能,超过了现有模型(包括基于深度的 NeRF 方法)。为了保持场景的几何连贯性,我们提出了一种空间连续性约束,鼓励 NeRF 的空间连续性与预训练深度估计模型的连续性相似。
(2)除了之外,贡献了一个新的数据集,NVS-RGBD,其中包含来自 Azure Kinect、ZED 2 和 iPhone 13 Pro 深度传感器的粗糙深度图。
(3)在 LLFF、DTU 和 NVS-RGBD 数据集上的实验表明,SparseNeRF 在基于稀疏视角的新视图合成方面实现了最优性能。
结果展示
利用三张稀疏视角图训练,得到的新视角渲染视频:


编辑:文婧
评论