
Kylin 优化 | Kylin 4 云上性能优化:本地缓存与软亲和性调度
一、背景介绍
日前,Apache Kylin 社区发布了全新架构的 Kylin 4.0。Kylin 4.0 的架构支持存储和计算分离,这使得 Kylin 用户可以采取更加灵活、计算资源可以弹性伸缩的云上部署方式来运行 Kylin 4.0。借助云上的基础设施,用户可以选择使用便宜且可靠的对象存储来储存 cube 数据,比如 S3 等。不过在存储与计算分离的架构下,我们需要考虑到,计算节点通过网络从远端存储读取数据仍然是一个代价较大的操作,往往会带来性能的损耗。
为了提高 Kylin 4.0 在使用云上对象存储作为存储时的查询性能,我们尝试在 Kylin 4.0 的查询引擎中引入本地缓存(Local Cache)机制,在执行查询时,将经常使用的数据缓存在本地磁盘,减小从远程对象存储中拉取数据带来的延迟,实现更快的查询响应;除此之外,为了避免同样的数据在大量 spark executor 上同时缓存浪费磁盘空间,并且计算节点可以更多的从本地缓存读取所需数据,我们引入了 软亲和性(Soft Affinity )的调度策略,所谓软亲和性策略,就是通过某种方法在 spark executor 和数据文件之间建立对应关系,使得同样的数据在大部分情况下能够总是在同一个 executor 上面读取,从而提高缓存的命中率。
二、实现原理
在 Kylin 4.0 执行查询时,主要经过以下几个阶段,其中用虚线标注出了可以使用本地缓存来提升性能的阶段:
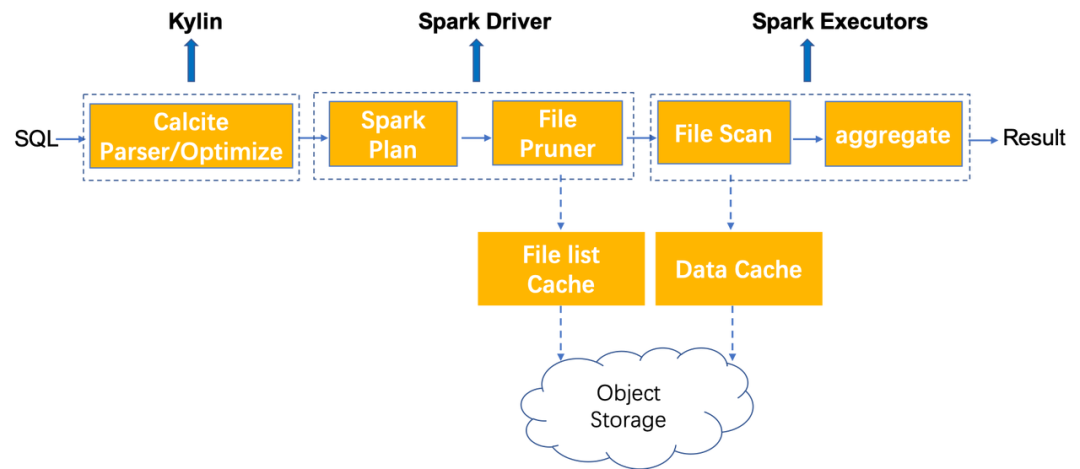
File list cache:在 spark driver 端对 file status 进行缓存。在执行查询时,spark driver 需要读取文件列表,获取一些文件信息进行后续的调度执行,这里会将 file status 信息缓存到本地避免频繁读取远程文件目录。
Data cache:在 spark executor 端对数据进行缓存。用户可以设置将数据缓存到内存或是磁盘,若设置为缓存到内存,则需要适当调大 executor memory,保证 executor 有足够的内存可以进行数据缓存;若是缓存到磁盘,需要用户设置数据缓存目录,最好设置为 SSD 磁盘目录。除此之外,缓存数据的最大容量、备份数量等均可由用户配置调整。
基于以上设计,在 Kylin 4.0 的查询引擎 sparder 的 driver 端和 executor 端分别做不同类型的缓存,基本架构如下:
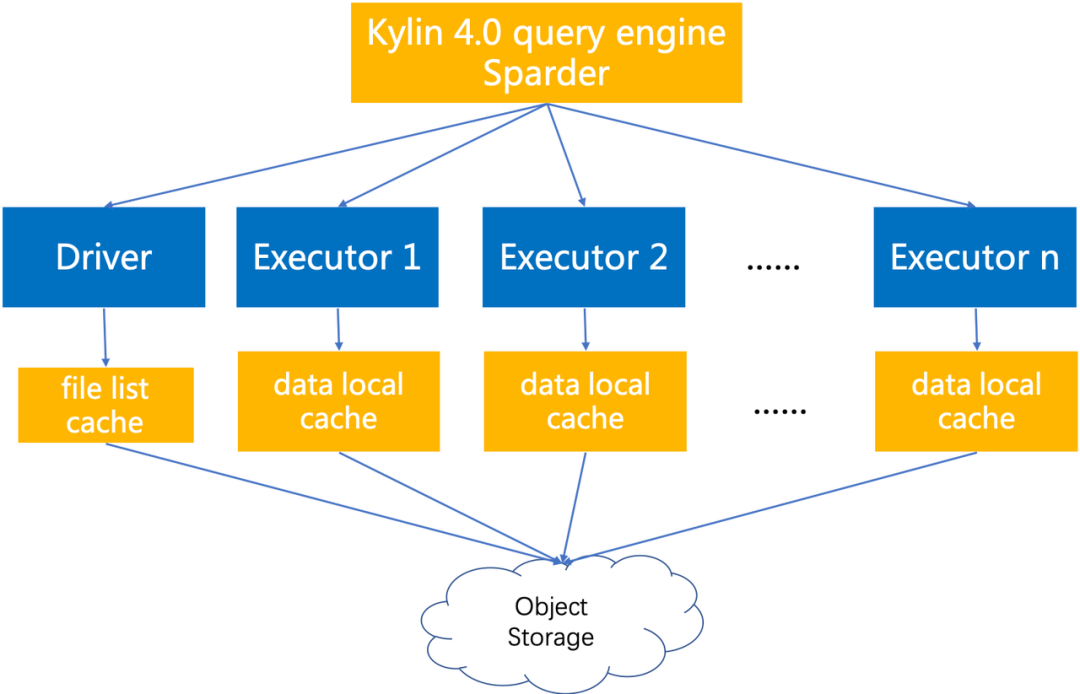
在 executor 端做 data cache 时,如果在所有的 executor 上都缓存全部的数据,那么缓存数据的大小将会非常可观,极大的浪费磁盘空间,同时也容易导致缓存数据被频繁清理。为了最大化 spark executor 的缓存命中率,spark driver 需要将同一文件的 task 在资源条件满足的情况下尽可能调度到同样的 executor,这样可以保证相同文件的数据能够缓存在特定的某个或者某几个 executor 上,再次读取时便可以通过缓存读取数据。
为此,我们采取根据文件名计算 hash 之后再与 executors num 取模的结果来计算目标 executor 列表,在多少个 executor 上面做缓存由用户配置的缓存备份数量决定,一般情况下,缓存备份数量越大,击中缓存的概率越高。当目标 executor 均不可达或者没有资源供调度时,调度程序将回退到 spark 的随机调度机制上。这种调度方式便称为软亲和性调度策略,它虽然不能保证 100% 击中缓存,但能够有效提高缓存命中率,在尽量不损失性能的前提下避免 full cache 浪费大量磁盘空间。
三、相关配置
根据以上原理,我们在 Kylin 4.0 中实现了本地缓存+软亲和性调度的基础功能,并分别基于 SSB 数据集和 TPCH 数据集做了查询性能测试。
这里列出几个比较重要的配置项供用户了解,实际使用的配置将在结尾链接中给出:
是否开启软亲和性调度策略:kylin.query.spark-conf.spark.kylin.soft-affinity.enabled
是否开启本地缓存:kylin.query.spark-conf.spark.hadoop.spark.kylin.local-cache.enabled
Data cache 的备份数量,即在多少个 executor 上对同一数据文件进行缓存:kylin.query.spark-conf.spark.kylin.soft-affinity.replications.num
缓存到内存中还是本地目录,缓存到内存设置为 BUFF,缓存到本地设置为 LOCAL:kylin.query.spark-conf.spark.hadoop.alluxio.user.client.cache.store.type
最大缓存容量:kylin.query.spark-conf.spark.hadoop.alluxio.user.client.cache.size
四、性能对比
我们在 AWS EMR 环境下进行了 3 种场景的性能测试,在 scale factor = 10的情况下,对 SSB 数据集进行单并发查询测试、TPCH 数据集进行单并发查询以及 4 并发查询测试,实验组和对照组均配置 S3 作为存储,在实验组中开启本地缓存和软亲和性调度,对照组则不开启。除此之外,我们还将实验组结果与相同环境下 HDFS 作为存储时的结果进行对比,以便用户可以直观的感受到 本地缓存+软亲和性调度 对云上部署 Kylin 4.0 使用对象存储作为存储场景下的优化效果。
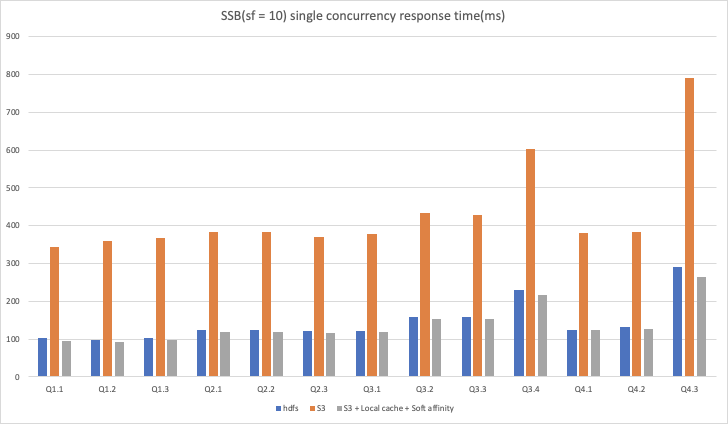
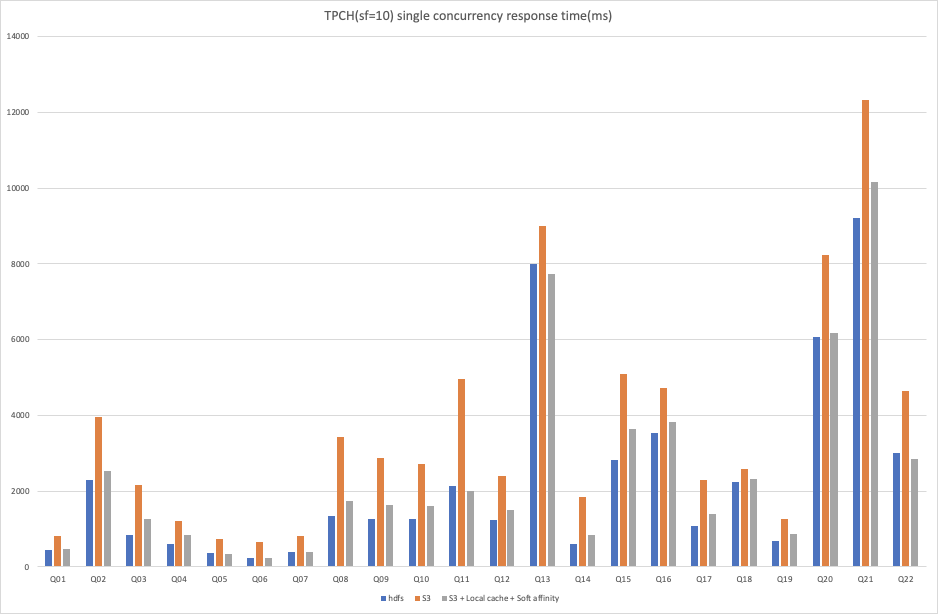
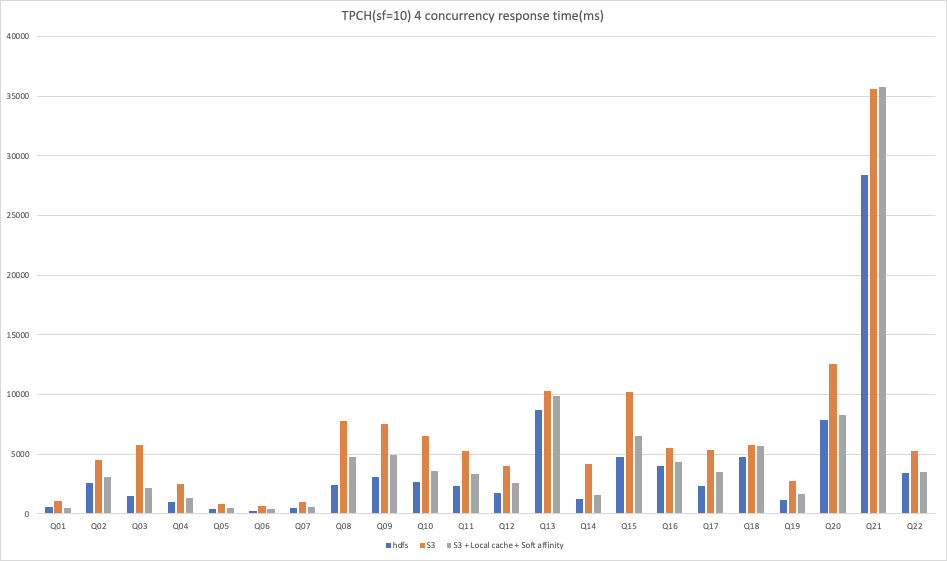
从以上结果可以看出:
在 SSB 10 数据集单并发场景下,使用 S3 作为存储时,开启本地缓存和软亲和性调度能够获得3倍左右的性能提升,可以达到与 HDFS 作为存储时的相同性能甚至还有 5% 左右的提升。
在 TPCH 10 数据集下,使用 S3 作为存储时,无论是单并发查询还是多并发查询,开启本地缓存和软亲和性调度后,基本在所有查询中都能够获得大幅度的性能提升。
不过在 TPCH 10 数据集的 4 并发测试下的 Q21 的对比结果中,我们观察到,开启本地缓存和软亲和性调度的结果反而比单独使用 S3 作为存储时有所下降,这里可能是由于某种原因导致没有通过缓存读取数据,深层原因在此次测试中没有进行进一步的分析,在后续的优化过程中我们会逐步改进。由于 TPCH 的查询比较复杂且 SQL 类型各异,与 HDFS 作为存储时的结果相比,仍然有部分 SQL 的性能略有不足,不过总体来说已经与 HDFS 的结果比较接近。
本次性能测试的结果是一次对 本地缓存+软亲和性调度 性能提升效果的初步验证,从总体上来看,本地缓存+软亲和性调度 无论对于简单查询还是复杂查询都能够获得明显的性能提升,但是在高并发查询下相比单并发查询存在一定的性能损失。
如果用户使用云上对象存储作为 Kylin 4.0 的存储,在开启 本地缓存+ 软亲和性调度的情况下,是可以获得很好的性能体验的,这为 Kylin 4.0 在云上使用计算和存储分离架构提供了性能保障。
五、代码实现
由于目前的代码实现还处于比较基础的阶段,还有许多细节需要完善,比如实现一致性哈希、当 executor 数量发生变化时如何处理已有 cache 等,所以作者还未向社区代码库提交 PR,想要提前预览的开发者可以通过下面的链接查看源码:
https://github.com/apache/kylin/commit/4e75b7fa4059dd2eaed24061fda7797fecaf2e35
相关链接
想要了解更多详情,可通过链接查阅性能测试结果数据和 kylin.properties:
https://github.com/Kyligence/kylin-tpch/issues/9