
性能优化小册 - React 搜索优化:防抖、缓存、LRU
最近要主导 react 项目重构优化等相关的工作,由于有好长时间没碰 React 了,今天索性把一个基于关键字搜索的 demo 做一下简单优化,在此记录一下。
主要从三个方面进行优化处理:
减少事件的触发频率 - 对关键字键入进行 debounce处理减少 HTTP 请求 - 对重复的 HTTP 请求进行缓存拦截 缓存淘汰策略 - 使用 LRU 优化缓存
减少事件的触发频率 - debounce
debounce 旨在时间段内控制事件只在最后一次操作触发。
debounce 原理:是维护一个计时器,在规定的 delay 时间后触发函数,在 delay 时间内再次触发的话,就会取消之前的计时器而重新设置。这样一来,只有最后一次操作能被触发。
下面是 react 中 debounce 优化的代码:
...
handler = e => {
let val = e.target.value;
if(val) {
this.search(val);
}
this.setState(() => ({
value: e.target.value
}))
}
debounce = (fn, delay) => {
let timer = null;
return function(event) {
timer && clearTimeout(timer);
event.persist && event.persist() // 保留引用,已备异步阶段访问
timer = setTimeout(() => {
fn.call(this, event)
}, delay)
}
}
onChangeHandler = this.debounce(this.handler, 1000)
...
render() {
return (
<div>
<input
// 这里不能设置成 value
defaulValue={this.state.value}
onChange={e => this.onChangeHandler(e)}
placeholder="试着输入一些文字"
/>
<div>
<Suspense fallback="Loading">
{this.renderMovies}
Suspense>
div>
div>
);
}
这里需要注意的是: 如果想要异步访问合成事件对象 SyntheticEvent,需要调用 persist() 方法或者对事件对象进行深拷贝 const event = { ...event } 保留对事件的引用。
在 React 事件调用时,React 传递给事件处理程序是一个合成事件对象的实例 SyntheticEvent 是通过合并得到的。这意味着在事件回调被调用后,SyntheticEvent 对象将被重用并且所有属性都将被取消。这是出于性能原因,因此,您无法以异步方式访问该事件。React合成事件官方文档
event.persist()
// or
const event: SyntheticEvent = { ...event }
还有一个隐晦点的需要指出, 我们知道如果想要使 input 为受控元素,正确的做法是:在给 input 绑定 value 时,需要同时绑定 onChange 事件来监听数据变化,否则就会报如下警告。

但是当你异步传递 SyntheticEvent 对象时,使用 value 属性进行绑定的 input,值不会再发生变化(但它仍是一个受控元素)。
...
event.persist()
timer = setTimeout(() => {
fn.call(this, event) // 传递 event
}, delay)
...
defaultValue={this.state.value}
// value={this.state.value} 使用 value 属性,值不会发生变化
onChange={e => this.onChangeHandler(e)}
/>
如下图:

减少 HTTP 请求
减少 HTTP 请求的手段之一就是将 HTTP 请求结果进行缓存,如果下次请求的 url 未发生变化,则直接从缓存中获取数据。
import axios from 'axios';
const caches = {};
const axiosRequester = () => {
let cancel;
return async url => {
if(cancel) {
cancel.cancel();
}
cancel = axios.CancelToken.source();
try {
if(caches[url]) { //如果请求的 url 之前已经提交过,就不在进行请求,返回之前请求回来的数据
return caches[url];
}
const res = await axios.post(url, {
cancelToken: cancel.token
})
const result = res.data.result;
caches[url] = result; //将 url作为 key, result 为请求回来的数据,存储起来
return result;
} catch(error) {
if(axios.isCancel(error)) {
console.log('Request canceled', error.message);
} else {
console.log(error.message);
}
}
}
}
export const _search = axiosRequester();
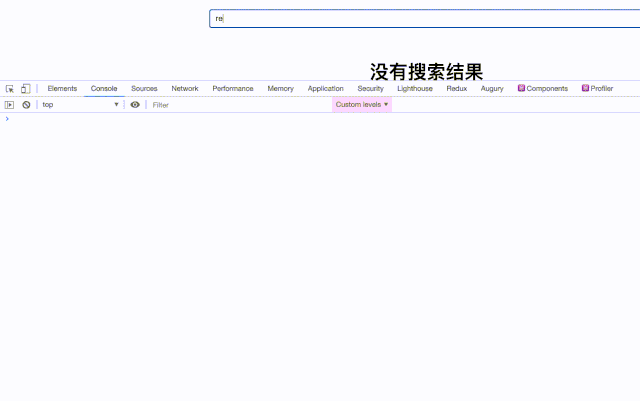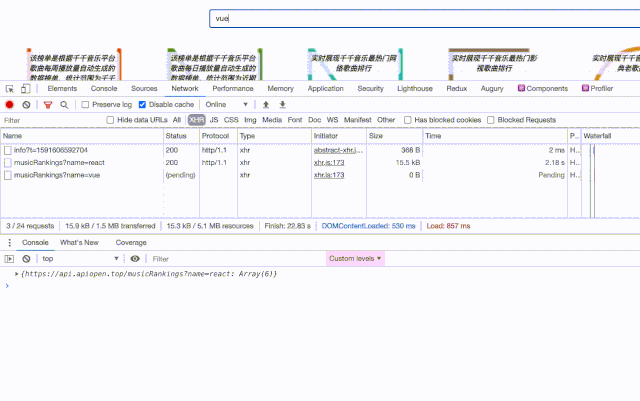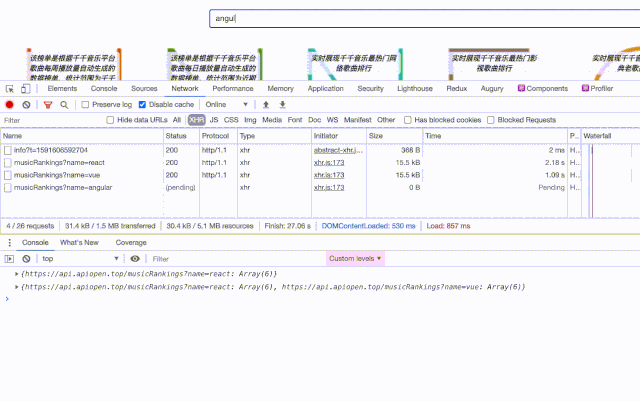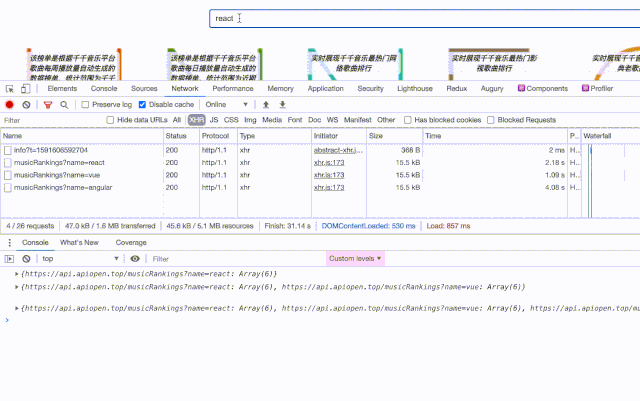
在使用 axios 进行 HTTP 请求时,首先根据 url 判断数据是否已被缓存,如果命中则直接从缓存中拿数据。如果未被缓存,则发起 HTTP 请求,并将请求回来的结果以键值对的形式保存在 caches 对象中。
缓存淘汰策略 - LRU
由于缓存空间是有限的,所以不能无限制的进行数据存储,当存储容量达到一个阀值时,就会造成内存溢出,因此在进行数据缓存时,就要根据情况对缓存进行优化,清除一些可能不会再用到的数据。
这里我们用到 keepAlive 相同的缓存淘汰机制 - LRU。
LRU - 最近最少使用策略
以时间作为参考,如果数据最近被访问过,那么将来被访问的几率会更高,如果以一个数组去记录数据,当有一数据被访问时,该数据会被移动到数组的末尾,表明最近被使用过,当缓存溢出时,会删除数组的头部数据,即将最不频繁使用的数据移除。
实现 LRU 策略我们需要一个存储缓存对象 key 的数组:
const keys = [];
并且需要设置一个阀值,控制缓存栈最大的存储数量:
const MAXIMUN_CACHES = 20;
还需要一个用来删除数组 keys 成员项的工具函数 remove:
function remove(arr, item) {
if (arr.length) {
var index = arr.indexOf(item)
if (index > -1) {
return arr.splice(index, 1)
}
}
}
最后再实现一个 pruneCacheEntry 函数,用来删除最少访问的数据(第一项):
// 传入 keys 数组的第一项
if (keys.length > parseInt(MAXIMUN_CACHES)) {
pruneCacheEntry(caches, keys[0], keys);
}
...
// 删除最少访问的数据
function pruneCacheEntry ( caches, key, keys) {
caches[key] = null; // 清空对应的数据
delete caches[key]; // 删除缓存 key
remove(keys, key);
}
最终「键入防抖」结合 LRU 缓存优化后的搜索功能就像这样:
同系列文章:
性能优化小册 - 异步堆栈追踪:为什么 await 胜过 Promise 性能优化小册 - 分类构建:利用好 webpack hash 性能优化小册 - 提高网页响应速度:优化你的 CDN 性能 性能优化小册 - 可编程式缓存:Service Workers 性能优化小册 - 让页面更早的渲染:使用 preload 提升资源加载优先级