
从源码分析如何优雅的使用 Kafka 生产者
本文公众号来源:crossoverJie作者:crossoverJie本文已收录至我的GitHub前言
其中有朋友咨询在大量消息的情况下 Kakfa 是如何保证消息的高效及一致性呢?
正好以这个问题结合 Kakfa 的源码讨论下如何正确、高效的发送消息。
简单的消息发送内容较多,对源码感兴趣的朋友请系好安全带?(源码基于
v0.10.0.0版本分析)。同时最好是有一定的 Kafka 使用经验,知晓基本的用法。
在分析之前先看一个简单的消息发送是怎么样的。
以下代码基于 SpringBoot 构建。
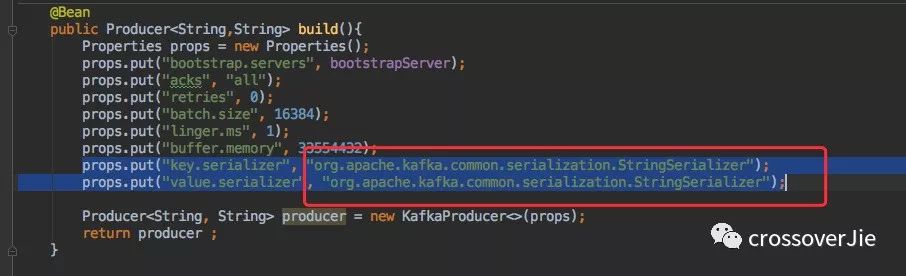
首先创建一个 org.apache.kafka.clients.producer.Producer 的 bean。
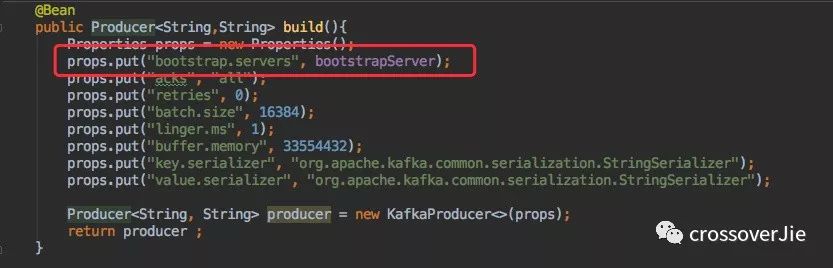
主要关注 bootstrap.servers,它是必填参数。指的是 Kafka 集群中的 broker 地址,例如 127.0.0.1:9094。
其余几个参数暂时不做讨论,后文会有详细介绍。
接着注入这个 bean 即可调用它的发送函数发送消息。
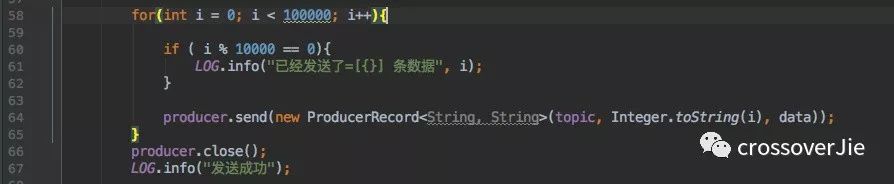
这里我给某一个 Topic 发送了 10W 条数据,运行程序消息正常发送。
但这仅仅只是做到了消息发送,对消息是否成功送达完全没管,等于是纯 异步的方式。
同步
那么我想知道消息到底发送成功没有该怎么办呢?
其实 Producer 的 API 已经帮我们考虑到了,发送之后只需要调用它的 get() 方法即可同步获取发送结果。

发送结果:

这样的发送效率其实是比较低下的,因为每次都需要同步等待消息发送的结果。
异步
为此我们应当采取异步的方式发送,其实 send() 方法默认则是异步的,只要不手动调用 get() 方法。
但这样就没法获知发送结果。
所以查看 send() 的 API 可以发现还有一个参数。
Future<RecordMetadata> send(ProducerRecord<K, V> producer,Callback callback);
Callback 是一个回调接口,在消息发送完成之后可以回调我们自定义的实现。
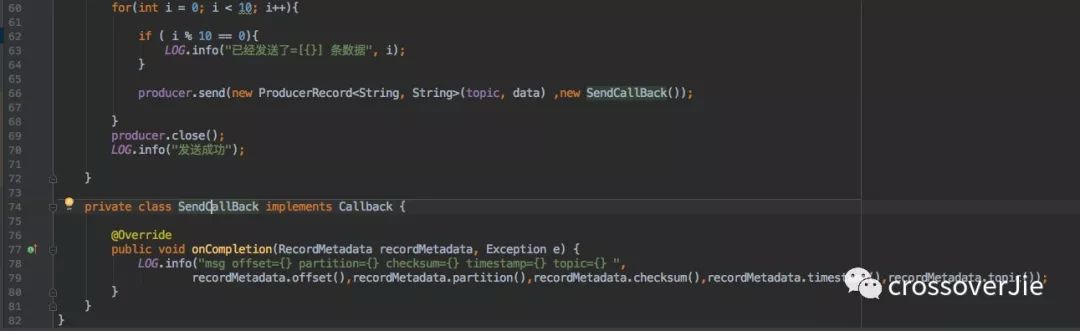
执行之后的结果:

同样的也能获取结果,同时发现回调的线程并不是上文同步时的 主线程,这样也能证明是异步回调的。
同时回调的时候会传递两个参数:
RecordMetadata和上文一致的消息发送成功后的元数据。Exception消息发送过程中的异常信息。
但是这两个参数并不会同时都有数据,只有发送失败才会有异常信息,同时发送元数据为空。
所以正确的写法应当是:
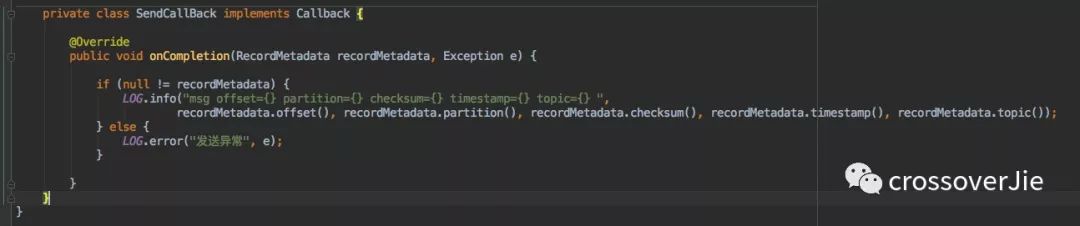
源码分析至于为什么会只有参数一个有值,在下文的源码分析中会一一解释。
现在只掌握了基本的消息发送,想要深刻的理解发送中的一些参数配置还是得源码说了算。
首先还是来谈谈消息发送时的整个流程是怎么样的, Kafka 并不是简单的把消息通过网络发送到了 broker中,在 Java 内部还是经过了许多优化和设计。
发送流程
为了直观的了解发送的流程,简单的画了几个在发送过程中关键的步骤。
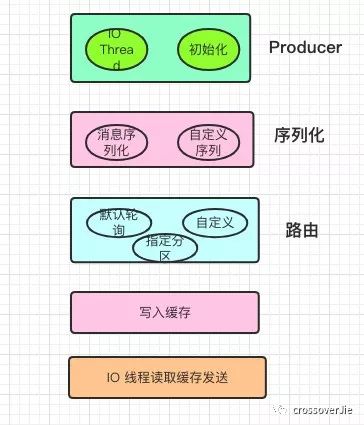
从上至下依次是:
初始化以及真正发送消息的
kafka-producer-network-threadIO 线程。将消息序列化。
得到需要发送的分区。
写入内部的一个缓存区中。
初始化的 IO 线程不断的消费这个缓存来发送消息。
步骤解析
接下来详解每个步骤。
初始化

调用该构造方法进行初始化时,不止是简单的将基本参数写入 KafkaProducer。比较麻烦的是初始化 Sender 线程进行缓冲区消费。
初始化 IO 线程处:

可以看到 Sender 线程有需要成员变量,比如:
acks,retries,requestTimeout
等,这些参数会在后文分析。
序列化消息
在调用 send() 函数后其实第一步就是序列化,毕竟我们的消息需要通过网络才能发送到 Kafka。

其中的 valueSerializer.serialize(record.topic(),record.value()); 是一个接口,我们需要在初始化时候指定序列化实现类。
我们也可以自己实现序列化,只需要实现 org.apache.kafka.common.serialization.Serializer 接口即可。
路由分区
接下来就是路由分区,通常我们使用的 Topic 为了实现扩展性以及高性能都会创建多个分区。
如果是一个分区好说,所有消息都往里面写入即可。
但多个分区就不可避免需要知道写入哪个分区。
通常有三种方式。
指定分区
可以在构建 ProducerRecord 为每条消息指定分区。
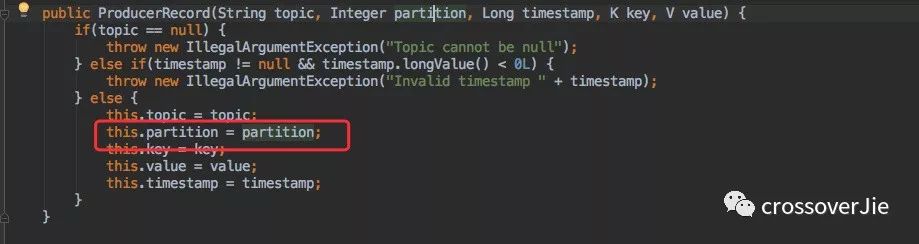
这样在路由时会判断是否有指定,有就直接使用该分区。
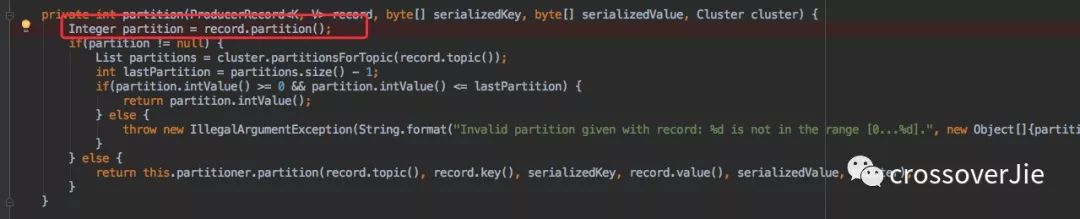
这种一般在特殊场景下会使用。
自定义路由策略
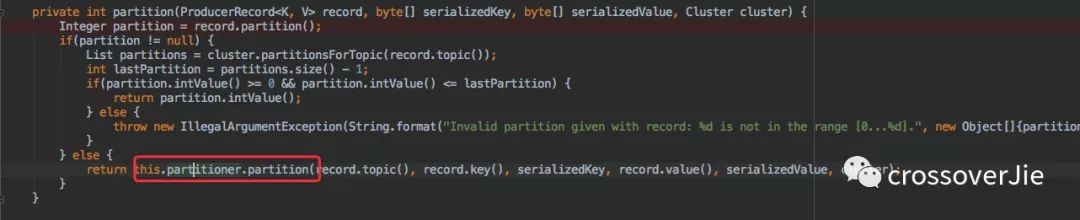
如果没有指定分区,则会调用 partitioner.partition 接口执行自定义分区策略。
而我们也只需要自定义一个类实现 org.apache.kafka.clients.producer.Partitioner 接口,同时在创建 KafkaProducer 实例时配置 partitioner.class 参数。

通常需要自定义分区一般是在想尽量的保证消息的顺序性。
或者是写入某些特有的分区,由特别的消费者来进行处理等。
默认策略
最后一种则是默认的路由策略,如果我们啥都没做就会执行该策略。
该策略也会使得消息分配的比较均匀。
来看看它的实现:
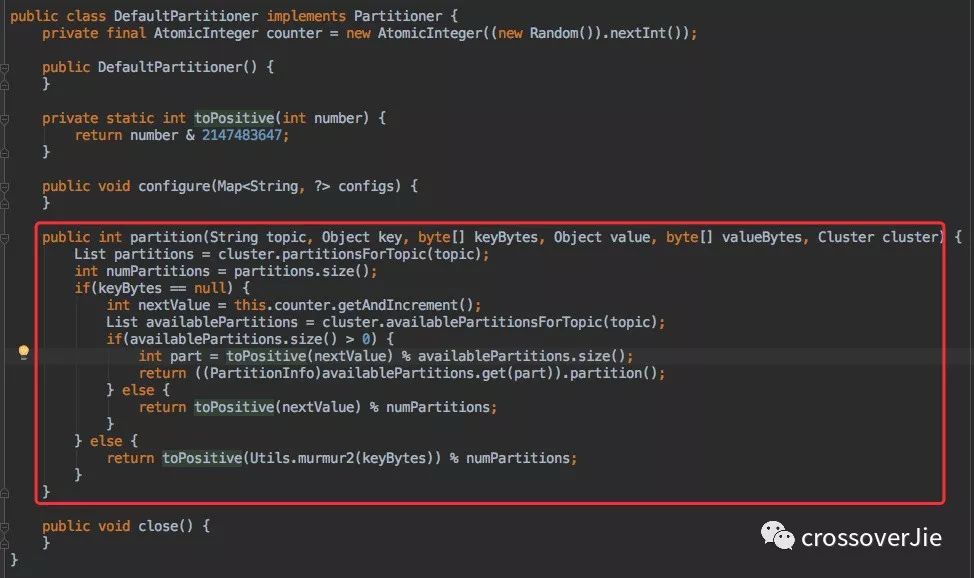
简单的来说分为以下几步:
获取 Topic 分区数。
将内部维护的一个线程安全计数器 +1。
与分区数取模得到分区编号。
其实这就是很典型的轮询算法,所以只要分区数不频繁变动这种方式也会比较均匀。
写入内部缓存
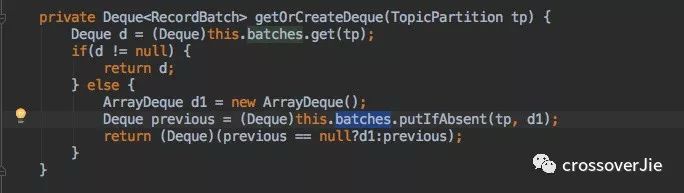
在 send() 方法拿到分区后会调用一个 append() 函数:

该函数中会调用一个 getOrCreateDeque() 写入到一个内部缓存中 batches。
消费缓存
在最开始初始化的 IO 线程其实是一个守护线程,它会一直消费这些数据。
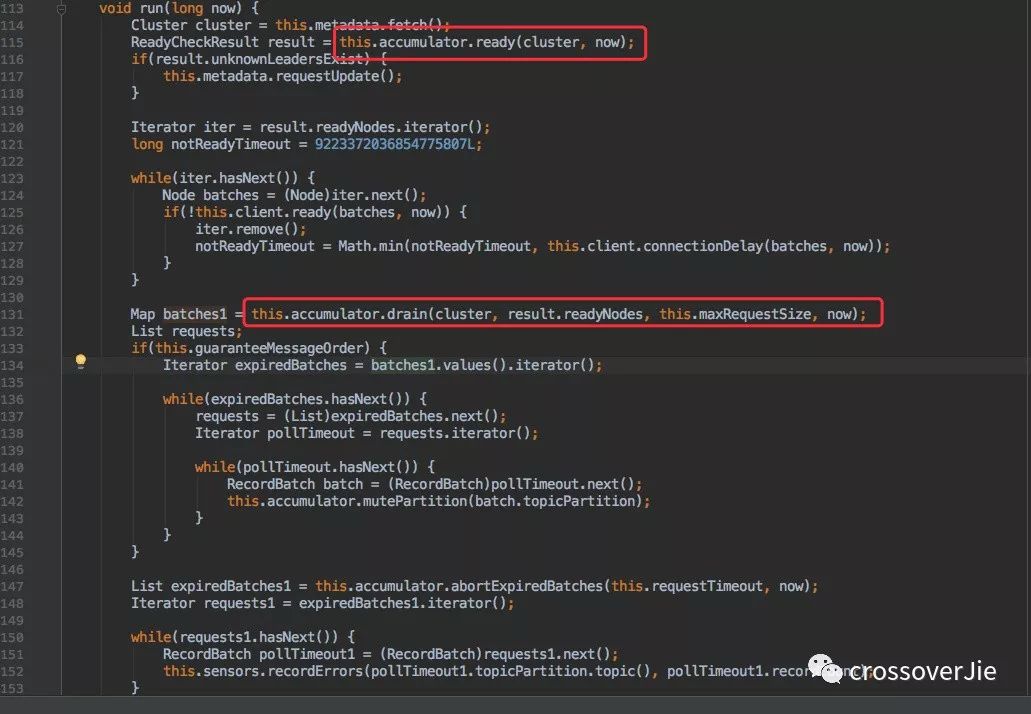
通过图中的几个函数会获取到之前写入的数据。这块内容可以不必深究,但其中有个 completeBatch 方法却非常关键。
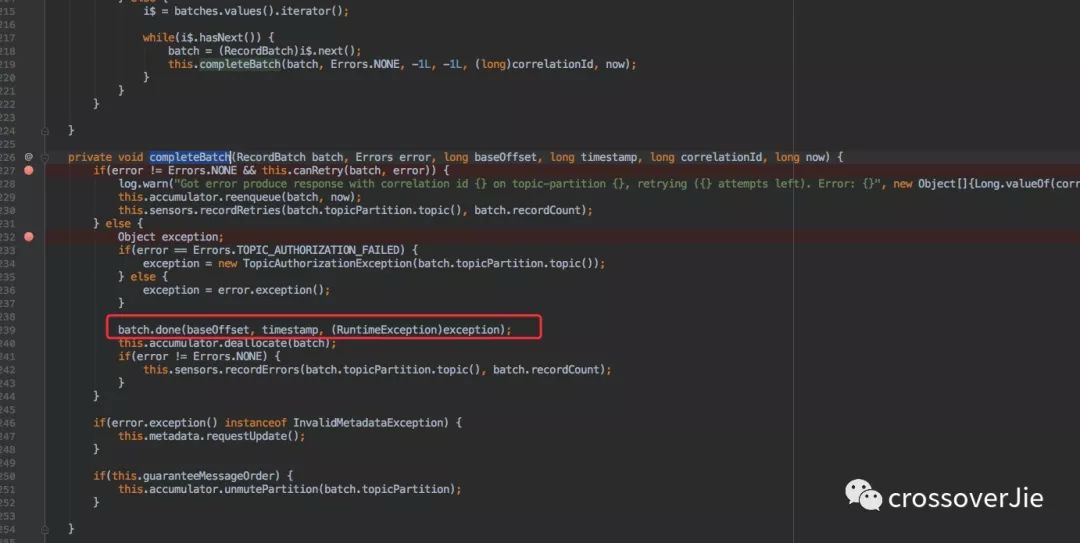
调用该方法时候肯定已经是消息发送完毕了,所以会调用 batch.done() 来完成之前我们在 send() 方法中定义的回调接口。
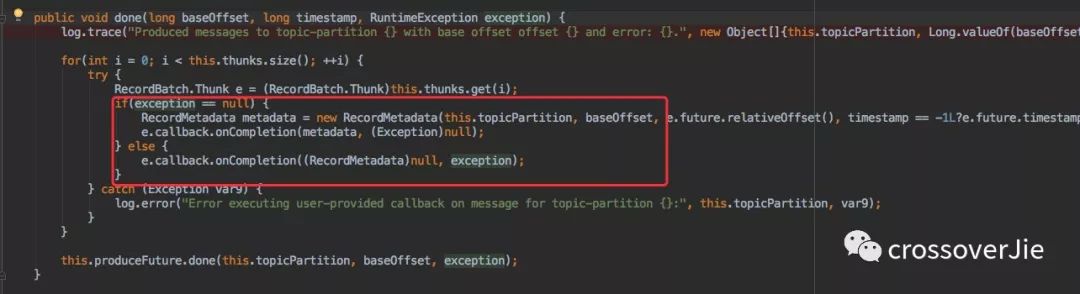
Producer 参数解析从这里也可以看出为什么之前说发送完成后元数据和异常信息只会出现一个。
发送流程讲完了再来看看 Producer 中比较重要的几个参数。
acks
acks 是一个影响消息吞吐量的一个关键参数。

主要有 [all、-1,0,1] 这几个选项,默认为 1。
由于 Kafka 不是采取的主备模式,而是采用类似于 Zookeeper 的主备模式。
前提是
Topic配置副本数量replica>1。
当 acks=all/-1 时:
意味着会确保所有的 follower 副本都完成数据的写入才会返回。
这样可以保证消息不会丢失!
但同时性能和吞吐量却是最低的。
当 acks=0 时:
producer 不会等待副本的任何响应,这样最容易丢失消息但同时性能却是最好的!
当 acks=1 时:
这是一种折中的方案,它会等待副本 Leader 响应,但不会等到 follower 的响应。
一旦 Leader 挂掉消息就会丢失。但性能和消息安全性都得到了一定的保证。
batch.size
这个参数看名称就知道是内部缓存区的大小限制,对他适当的调大可以提高吞吐量。
但也不能极端,调太大会浪费内存。小了也发挥不了作用,也是一个典型的时间和空间的权衡。
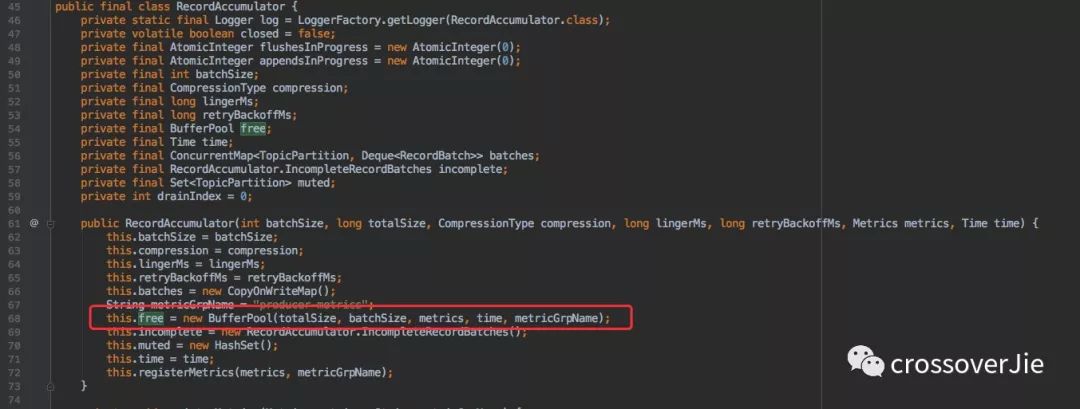
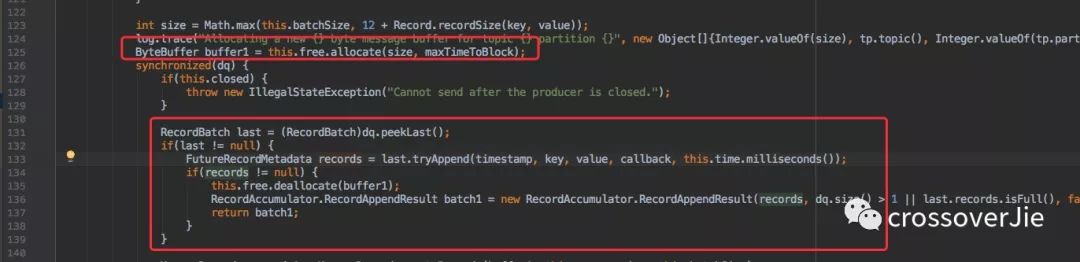
上图是几个使用的体现。
retries
retries 该参数主要是来做重试使用,当发生一些网络抖动都会造成重试。
这个参数也就是限制重试次数。
但也有一些其他问题。
因为是重发所以消息顺序可能不会一致,这也是上文提到就算是一个分区消息也不会是完全顺序的情况。
还是由于网络问题,本来消息已经成功写入了但是没有成功响应给 producer,进行重试时就可能会出现
消息重复。这种只能是消费者进行幂等处理。
如果消息量真的非常大,同时又需要尽快的将消息发送到 Kafka。一个 producer 始终会收到缓存大小等影响。
那是否可以创建多个 producer 来进行发送呢?
配置一个最大 producer 个数。
发送消息时首先获取一个
producer,获取的同时判断是否达到最大上限,没有就新建一个同时保存到内部的List中,保存时做好同步处理防止并发问题。获取发送者时可以按照默认的分区策略使用轮询的方式获取(保证使用均匀)。
这样在大量、频繁的消息发送场景中可以提高发送效率减轻单个 producer 的压力。
最后则是 Producer 的关闭,Producer 在使用过程中消耗了不少资源(线程、内存、网络等)因此需要显式的关闭从而回收这些资源。
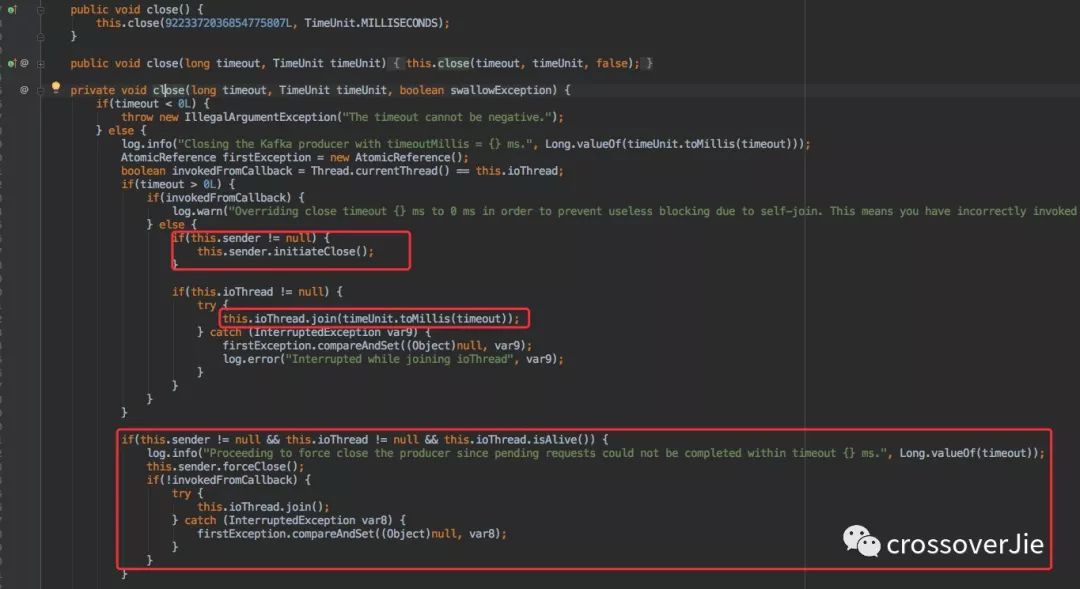
默认的 close() 方法和带有超时时间的方法都是在一定的时间后强制关闭。
但在过期之前都会处理完剩余的任务。
所以使用哪一个得视情况而定。
总结本文内容较多,从实例和源码的角度分析了 Kafka 生产者。
希望看完的朋友能有收获,同时也欢迎留言讨论。
不出意外下期会讨论 Kafka 消费者。
如果对你有帮助还请分享让更多的人看到。
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号Java3y。
?获取海量视频资源

获取Java精美脑图
?获取Java学习路线
获取开发常用工具
?精美整理好的PDF电子书
在公众号下回复「888」即可获取!!
点个在看 ,分享到朋友圈
,分享到朋友圈 ,对我真的很重要!!
,对我真的很重要!!