
【经典】GAT作者Petar剑桥大学博士论文《深层神经网络结构的复兴...

新智元推荐
编辑:元子
【新智元导读】图神经网络依然是当下的研究热点之一。DeepMind研究科学家Petar Veličković在Twitter上开放了自己的剑桥大学博士论文《深度神经网络结构的》,共有147页pdf,里面涵盖了出名的图神经网络GAT和Deep Graph Infomax的经典工作。

Petar Veličković,DeepMind研究科学家。在Pietro Lio的指导下获得了剑桥大学的计算机科学博士学位。我的研究兴趣包括设计操作非平凡结构数据(如图)的神经网络架构,以及它们在算法推理和计算生物学中的应用。
特别地,我是Graph Attention Network(图注意力网络)的第一作者和Deep Graph Infomax的第一作者。我的研究已经在ZDNet等媒体上发表。
https://petar-v.com/
深层神经网络结构的复兴
 使用深度神经网络的机器学习(“深度学习”)允许直接从原始输入数据学习复杂特征,完全消除了学习流程中手工“硬编码”的特征提取。这促使了计算机视觉,自然语言处理,强化学习和生成模型的相关任务性能的提升。
使用深度神经网络的机器学习(“深度学习”)允许直接从原始输入数据学习复杂特征,完全消除了学习流程中手工“硬编码”的特征提取。这促使了计算机视觉,自然语言处理,强化学习和生成模型的相关任务性能的提升。
这些成功案例几乎都是与大量带有标记的训练样本(“大数据”)密切相关的,这些示例展示了简单的网格状结构(例如文本或图像),可通过卷积或循环层加以利用。这是因为神经网络的自由度非常大,使得它们的泛化能力容易受到过度拟合等影响。然而,在许多领域,广泛的数据收集并不总是合适的,负担得起的,甚至是可行的。
此外,数据通常以更复杂的结构组织起来——大多数现有的方法都会简单地抛弃这种结构。这类任务的例子在生物医学领域非常丰富。我假设,如果深度学习要在这样的环境中充分发挥其潜力,我们需要重新考虑“硬编码”方法——通过结构性归纳偏差,将输入数据中的固有结构假设直接整合到我们的架构和学习算法中。
在本文中,我通过开发三个注入结构的神经网络架构(操作稀疏多模态和图结构的数据)和一个基于结构的图神经网络学习算法直接验证了这一假设,证明了超越传统基线模型和算法的性能提升。
论文结构:
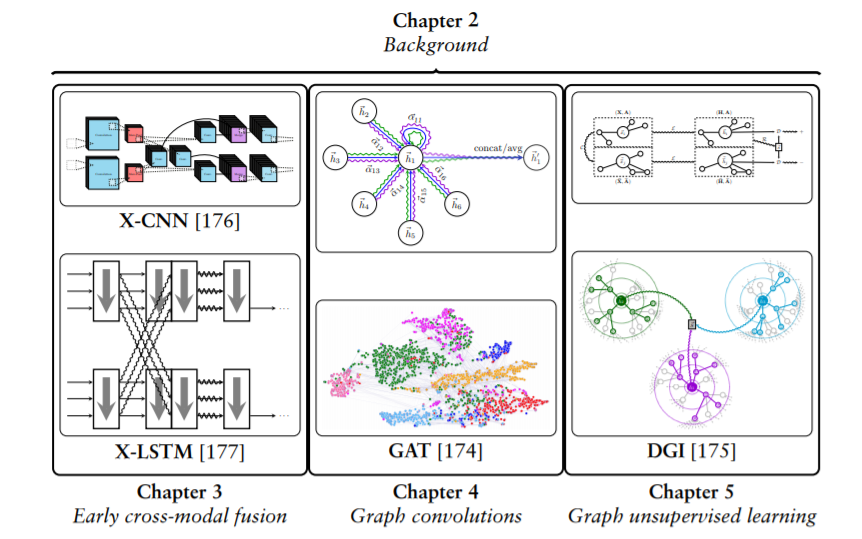
本文主要贡献的概述。
首先,提出了两种具有特殊结构诱导偏差的多模态学习早期融合模型;一个用于网格结构输入模式(X‐CNN[176]),另一个用于顺序输入模式(X‐LSTM[177])。接下来,图卷积层的理想结构偏差在图注意力网络(GAT[174])模型中得到了应用,并且第一次同时得到了满意的结果。
最后,通过Deep Graph Infomax (DGI[175])算法成功地引入了局部互信息最大化,将其作为一个无监督学习目标用于图的结构输入,允许在学习节点表示时结合图卷积编码器引入非常强大的结构诱导偏差。



地址:
https://www.repository.cam.ac.uk/handle/1810/292230
本文授权转载自公众号:专知