
CNN网络结构的发展(最全整理)

极市导读
本文介绍了十五种经典的CNN网络结构。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
CNN基本部件介绍
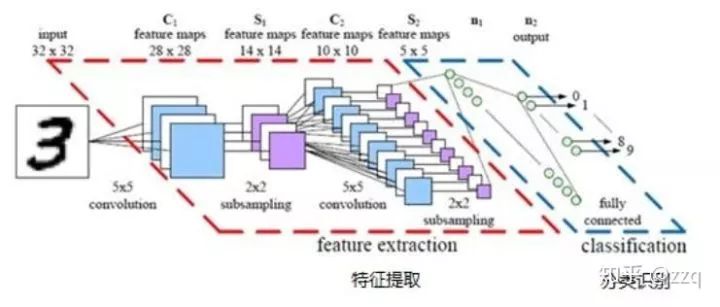
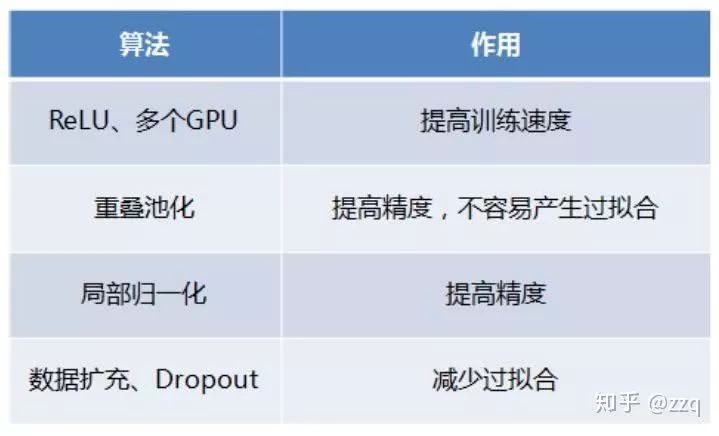
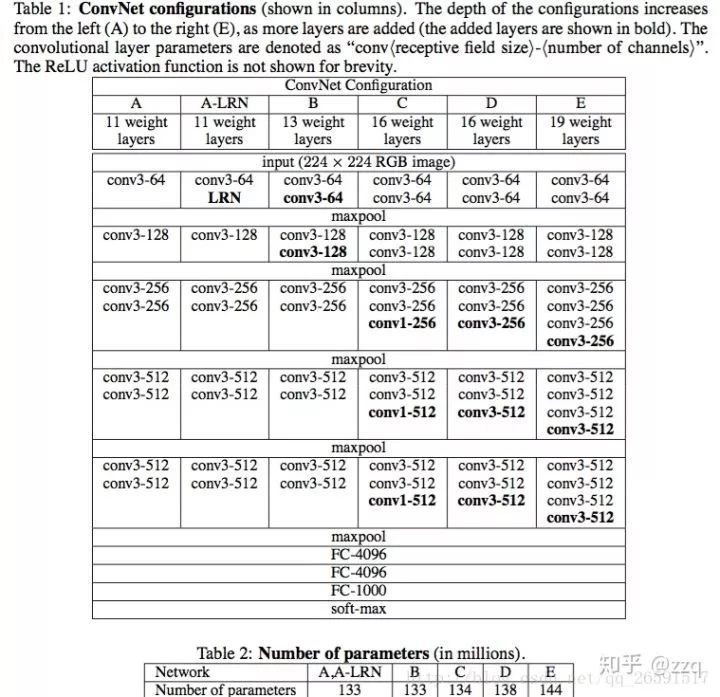
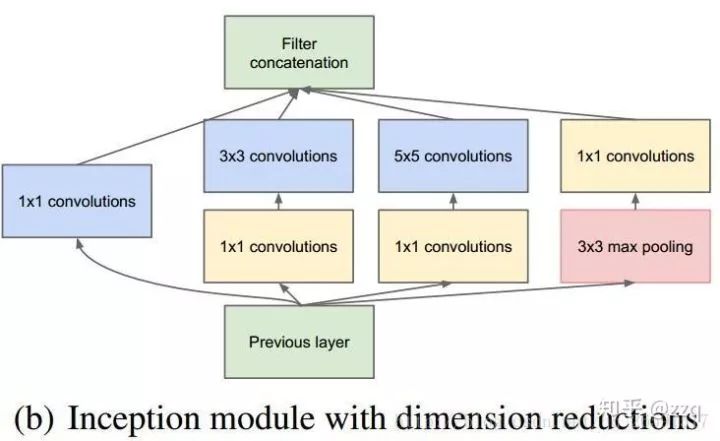
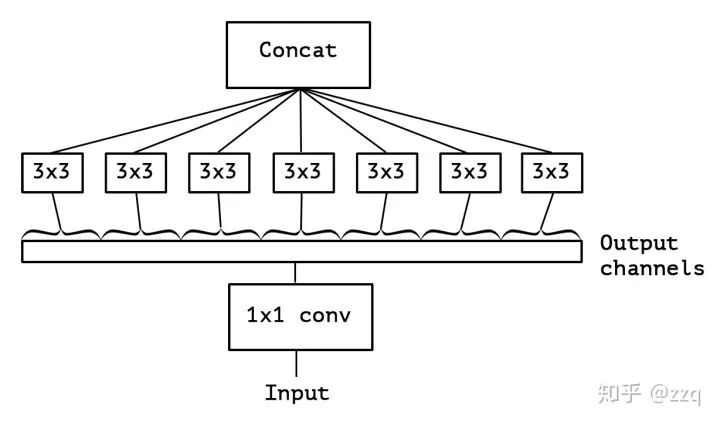
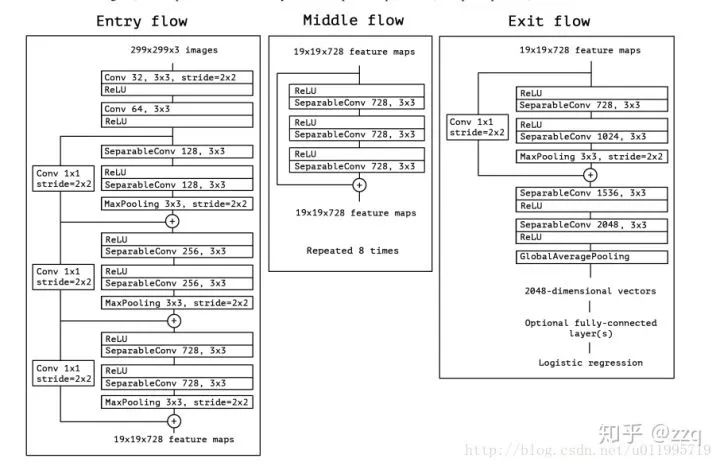
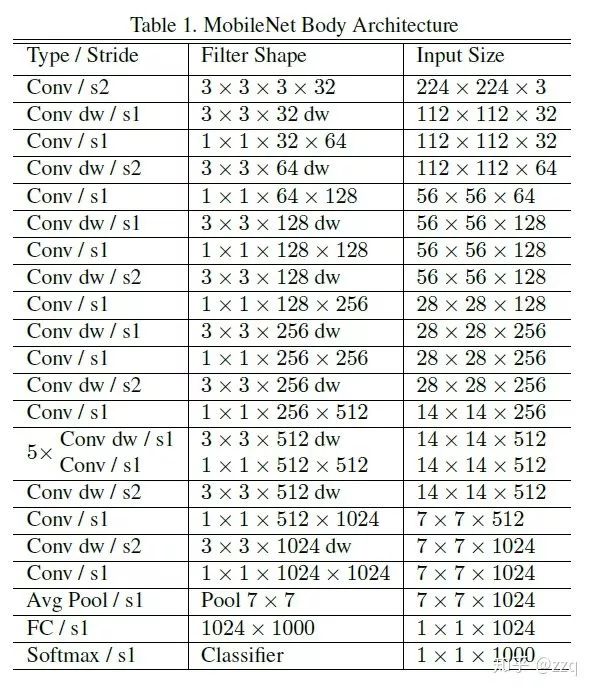
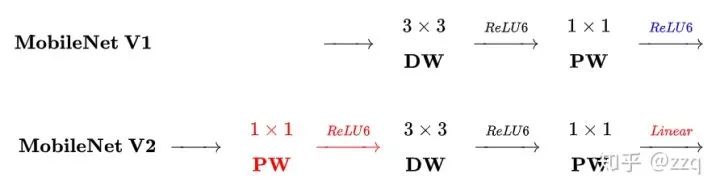
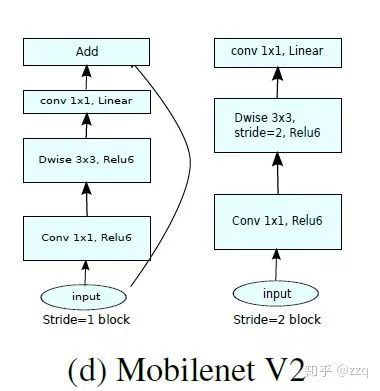
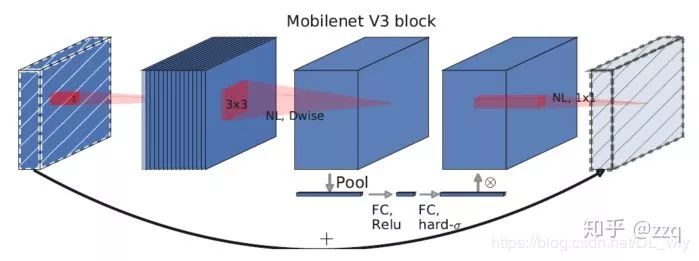
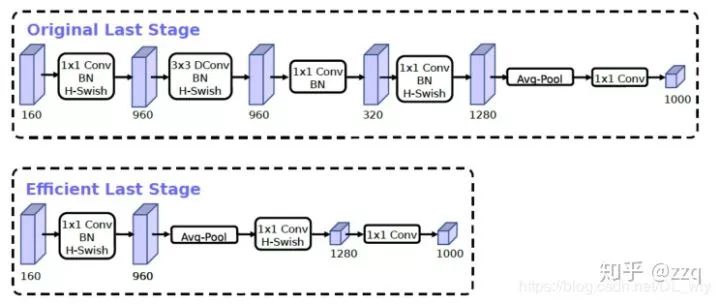
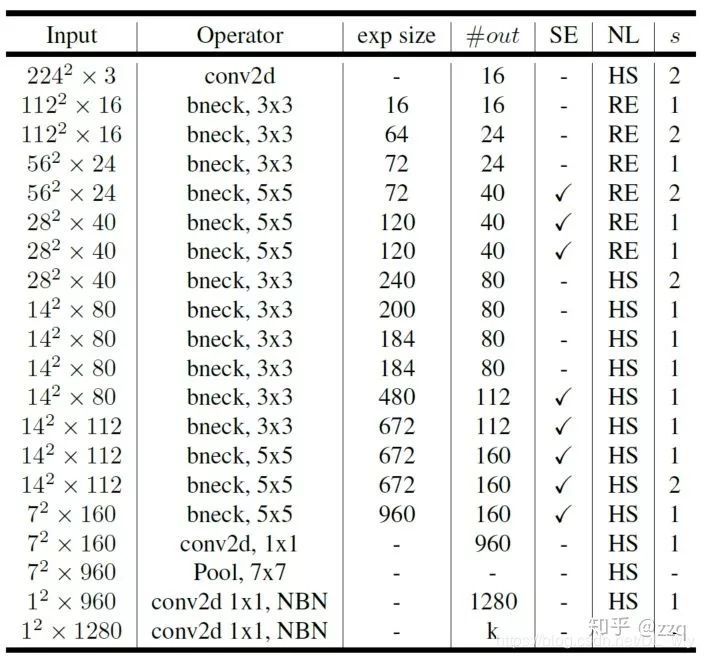
经典网络结构


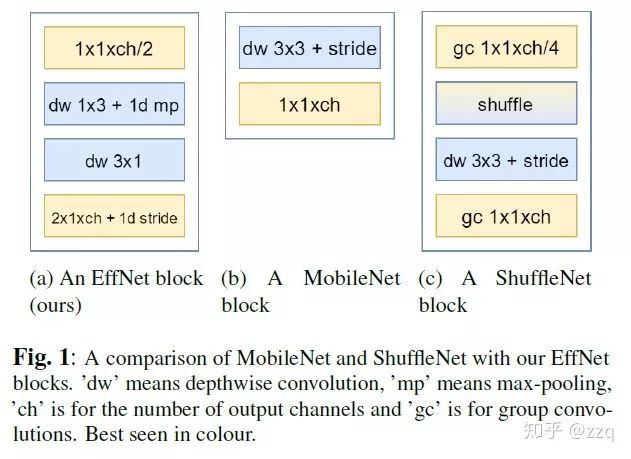
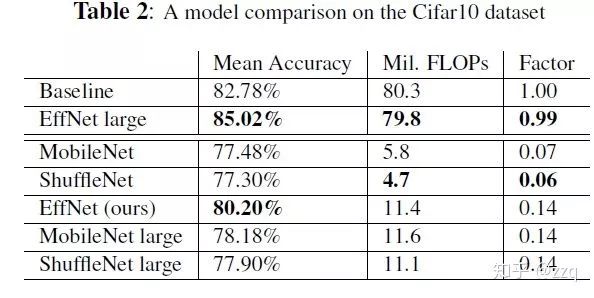
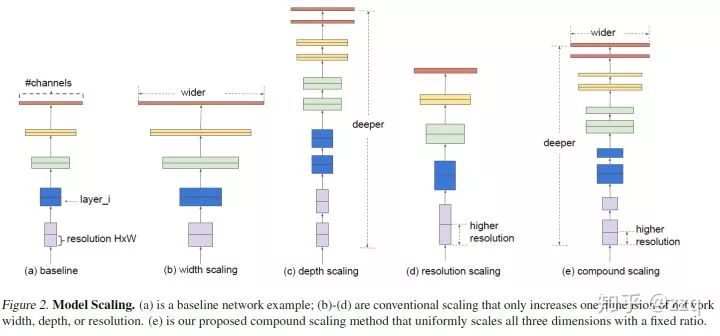
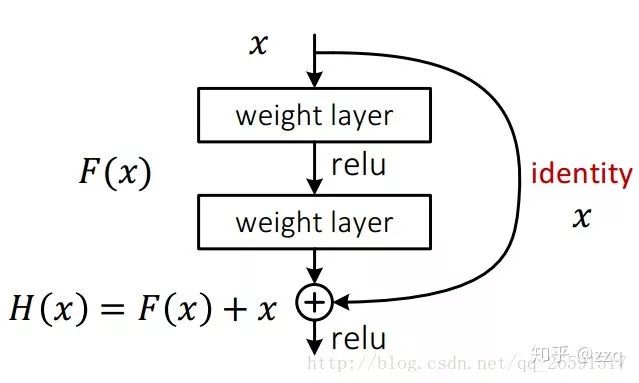
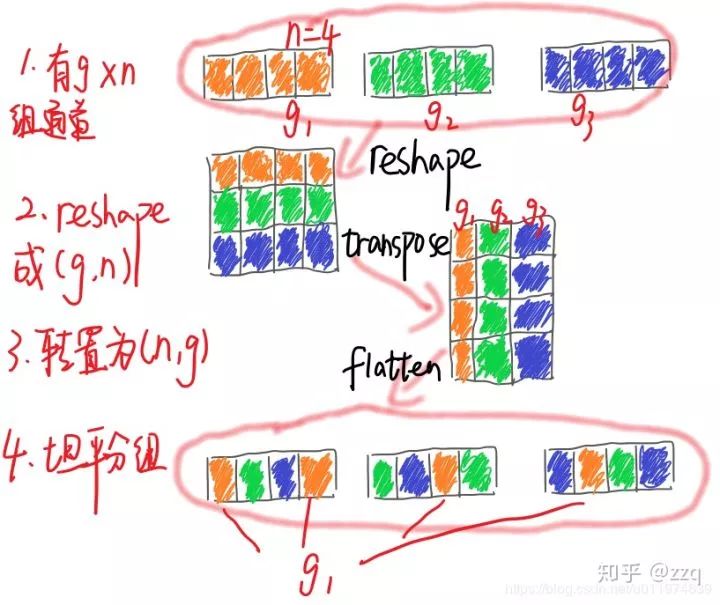
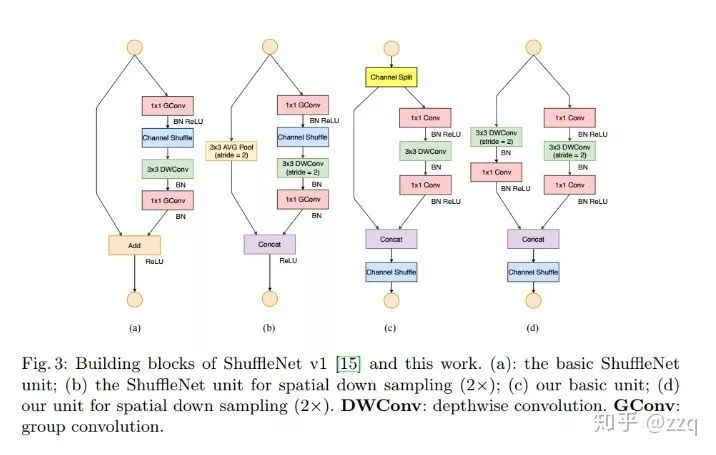
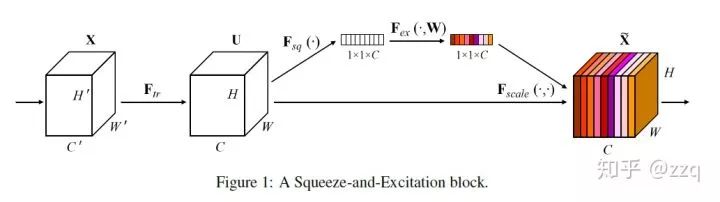
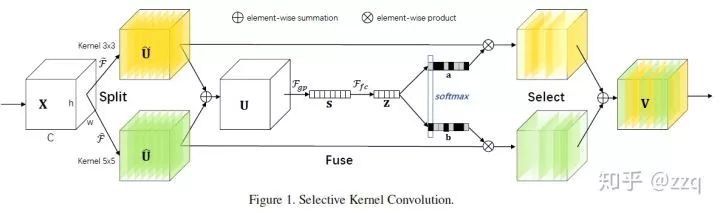

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

评论