
用于半监督语义分割的基于掩码的数据增强
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


利用卷积神经网络(CNN)进行语义分割是图像分析中的一个重要组成部分。训练一个CNN来进行语义分割需要大量的标记数据,而这些标记数据的生产既昂贵又劳动密集型。半监督学习算法通过利用未标记的数据来解决这个问题,从而减少了训练所需的标记数据量。特别是,CutMix和ClassMix等数据增强技术从现有的标记数据生成额外的训练数据。在本文中,作者提出了一种新的数据增强方法,称为ComplexMix,它结合了CutMix和ClassMix的特性,提高了性能。所提议的方法能够控制增强数据的复杂性,同时尝试实现语义正确,并解决复杂性和正确性之间的权衡。提出的ComplexMix方法在一个标准的语义分割数据集上进行了评估,并与其他最先进的技术进行了比较。实验结果表明,作者的方法在标准数据集的语义图像分割方面优于最先进的方法。
本文提出的方法属于对无监督混合样本进行一致性预测的范畴。作者提出了一种更有效的基于掩码的分割地图扩展策略,称为ComplexMix,以解决半监督语义分割问题。作者假设在增加语义上正确的增广的复杂性中有附加价值,因此试图产生语义上正确的复杂增广。作者将一幅图像的分割图分割成几个相同大小的正方形,并根据当前模型预测每个正方形中的语义标签。遵循ClassMix[9]的扩展策略,然后作者在每个正方形中选择预测类的一半,并将它们粘贴到扩展图像上,以形成尊重语义边界的新扩展。加法的复杂度是由初始分割时产生的平方数控制的。实验结果表明,所提出的ComplexMix增强方法优于随机增强或简单的语义正确增强技术。
本文的主要贡献是通过一种新的数据增强策略将一致性正则化应用于语义分割,从而从未标记的示例中生成复杂且语义正确的数据。该方法能够控制增强数据的复杂性,从而在复杂性和正确性之间取得平衡。在标准数据集上的实验评估结果表明,与最先进的技术相比,性能得到了改进。
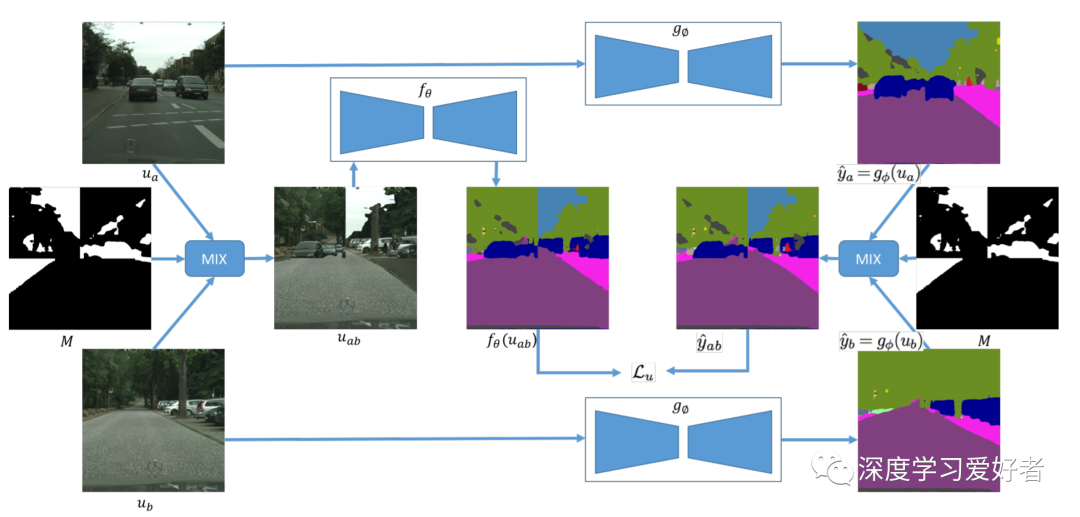
作者提出的通过基于掩码的数据增强的半监督分割方法。作者的方法采用了刻薄教师策略。该网络的顶部和底部分支属于训练有素的教师,以产生语义分割预测,而中间分支属于学生,学生试图匹配教师的混合预测与自己基于混合图像输入的预测。
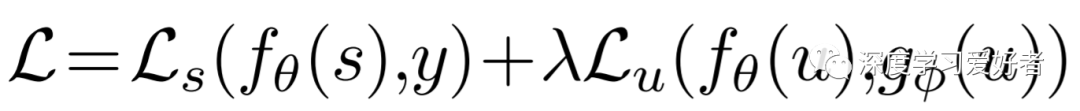
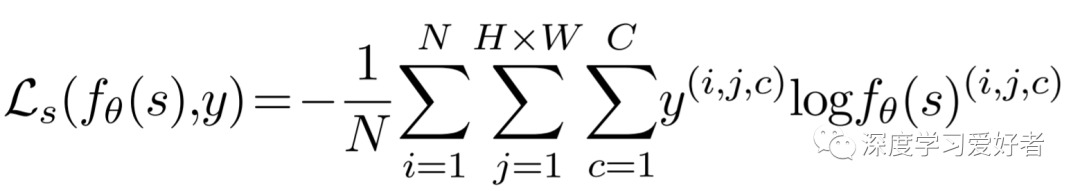
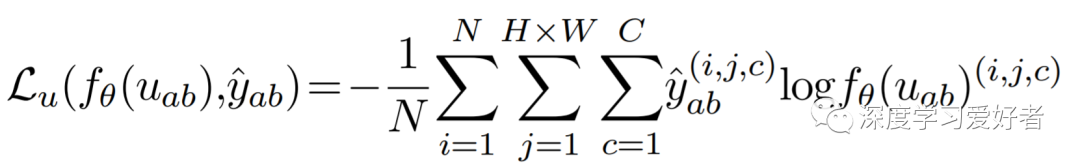
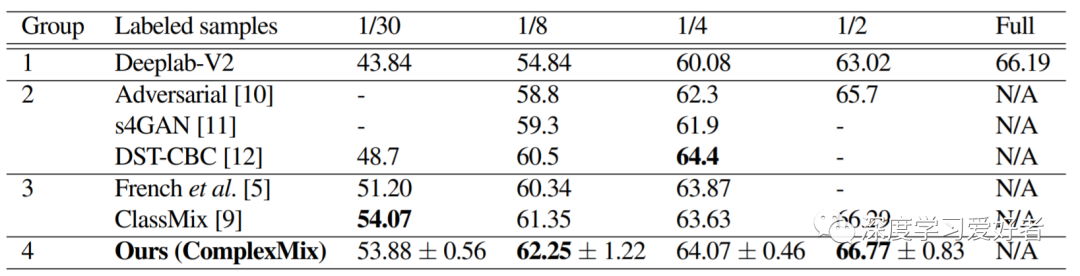
评估结果显示带有标签的数据的不同部分的平均欠条百分比。符号-表示参考文献中没有提供数据。不同的列显示了训练中使用的标记数据的比例。
在本文中,作者解决了使用基于掩码的数据增强的半监督学习语义分割问题。作者提出了一种新的增强技术,可以平衡复杂性和正确性,并表明通过使用它,作者能够在标准数据集上评估语义分割时改进最先进的技术。
论文链接:https://arxiv.org/pdf/2101.10156.pdf
每日坚持论文分享不易,如果喜欢我们的内容,希望可以推荐或者转发给周围的同学。
- END -
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~