
人工智能十问:越来越卷的AI,未来路在何方

最近几年,人工智能经历了爆火、发展、再到最近的热度逐渐下降,似乎人工智能已经成了大厂才能玩的游戏。
究其原因,就是人工智能的「门槛」越来越高了。
前不久,谷歌AI的代表人物Jeff Dean发表了一个新的工作,但在行业内却引发了一阵不小的风波。究其原因,并不是工作本身有多么出色。这个研究只比最新结果提升了0.03%,但却花费了价值57000多美元的TPU算力,这一下就炸锅了。
很多人说,现在的AI研究已经变成了拼算力、拼资源的代表,普通学者卷不动了。
还有很多人有这样的疑惑:人工智能究竟给我们带来了哪些改变?它除了下围棋之外还会做什么,它的未来还会如何发展?
带着这些问题,我们和冯霁博士进行了深入沟通。他是创新工场南京AI研究院的执行院长、倍漾量化创始人,在AI领域有着多年的研究经验。通过这次对谈,让我们对AI未来的发展和落地有了新的认识。
下面的小视频提炼了对话的亮点,文章是对于对话的整理和采编:
注:以下的“我”,指的都是冯霁博士。
1、人工智能创新,遇到天花板?
谷歌最近这个问题的确受到了挺多关注,我觉得有三个问题值得思考:
第一,大厂开始逐渐地走向「暴力美学」,也就是用「超大规模的数据」+「超大规模的算力」,暴力探索深度神经网络的天花板。不过,这种方法的边界和极限在哪?
第二,从学术和科研的角度,这种方法是否是AI唯一的出路?事实上,目前已经有大量研究在探索其他的技术路线,比如怎样做到从感知智能往认知智能去做转变、怎样利用比较小的数据量解决人工智能遇到的问题,等等。
第三,对于工业界的实际应用,是否真的需要如此大的算力?工业界有大量任务是非语音图像文本相关的,这也是在倒逼着学术界去做一些比较高效的算法。
2、人工智能算法,只有深度神经网络?
90年代之前,「人工智能」的代表技术还是以「符号主义」为主,也就是基于逻辑推理,去做Planning、Searching这样的技术。
2010年之后,迎来了人工智能的一次重要的转变,那就是用神经网络技术去更好地表示这些感知类的任务。但是,目前还有大量的人工智能的「圣杯」问题没有得到解决,比如怎样做逻辑推理、怎样做常识、怎样更好地对记忆进行建模等等。
为了解决这些问题,是不是用深度神经网络就够?这可能是目前学术界和工业界更关心的下一个重要的方向。
3、人工智能的未来:感知 vs 认知?
所谓的「感知人工智能」,其实就是最近几年人工智能成功落地的代表性例子,比如图像识别、语音转文字,以及一些文本生成的任务等。
但更重要的是,怎么从这种感知类的任务,转向具有认知能力的任务,尤其是怎么用人工智能的方式来实现逻辑推理、实现常识,从而真正实现通用人工智能?
针对这个问题,据我所知,学术界主要有三条技术路线。
第一,仍然沿着神经网络这条路,通过不断地堆数据和算力尝试解决问题。
第二,尝试导入符号主义的技术,也就是连接主义+符号主义的结合。
第三,继续提升传统的逻辑推理技术,而这条路线也是最难的。
4、数据:数字时代的石油怎么采?
数据对于人工智能工程来说,重要性已经越来越高了。工业界提出了一个新的概念,叫「以数据为中心」的开发模式。相比之下,之前叫做「以模型为中心」。
传统情况下,工程师更多的时间会花在如何搭建一个模型、如何通过调参来让这个系统的性能更好。但现如今,大家80%的注意力都放在如何让数据集变得更好、如何让训练集变得更好、如何让训练集更平衡,然后让这个模型在好的数据集上训练,并得到比较好的结果。
随着我们对数据隐私需求的逐渐增长,数据带来的一些负作用以及非技术要求也越来越多了。比如当几家机构做联合建模的时候,出于对数据隐私的保护,数据不能够在机构之间分享。所以像联邦学习这样的技术,就是为了在保护数据隐私的前提下,实现联合建模。
现在大家已经逐渐地意识到,在具体的工业开发中每家机构不一样的地方就是他们的数据。现在有了非常便利的软件开源框架,也有了非常高效的硬件实现,工程师就都转而去关注数据了——这是一个Paradigm Shift,也就是范式级别的转变。
我自己孵化的倍漾量化,是以AI技术为核心的对冲基金。在公司内部,每天需要存储的数据量大概有25-30TB。因此我们就遭遇到了“内存墙”的问题。
为了应对海量数据对内存带来的压力,我们把数据分成了冷数据、温数据和热数据。
“冷数据”指的是,数据访问的频率不是很高,落库就好。“热数据”是指,我们要做大量的读写任务,而数据一般都比较散,每次读写的量又非常得大。那么如何把热数据很好的进行分布式存储?
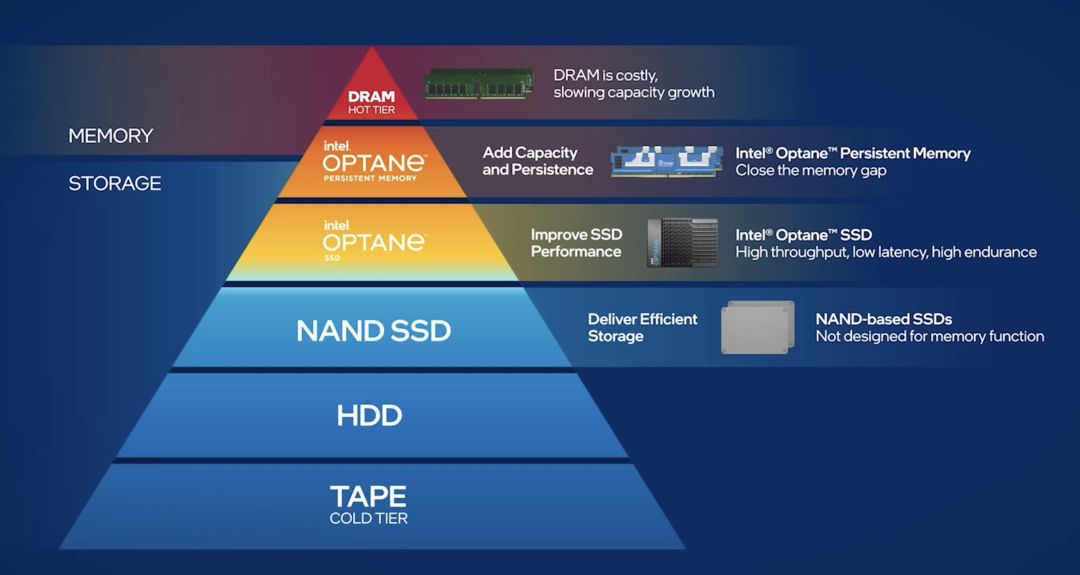
和纯SSD方案相比,现在会有更好的解决方案,比如傲腾持久内存:它介于内存跟SSD之间,可以将热数据做分布式存储,就能一定程度地减缓“内存墙”的问题。
5、「AI-原生」的IT基础设施,是否会出现?
现在有个很火的概念叫「云原生」,它促进了云计算基础设施的重构。而针对人工智能而生的「AI-原生」,也已经实实在在地发生了。尤其在过去的10年,计算机的硬件创新其实都是在围绕着人工智能应用而发展的。
举个例子,当前我们对于云端可信计算的需求越来越多了。比如AI模型的计算过程是一个公司的核心知识产权,如果把它放到云端或者公有平台上,自然会担心计算过程有被窃取的风险。
在这种情况下,有没有基于硬件的解决方案?答案是肯定的,比如我们就在使用英特尔芯片上的SGX隐私沙盒,它能够以硬件的方式来保障我们的计算,这个其实是跨机构之间合作的一个非常重要的基础。
这就是一个非常典型的例子,也就是从需求出发,推动芯片或硬件厂商提供相应的解决方案。
6、人工智能硬件,就等于GPU?
这个观点确实就比较片面了。以倍漾量化每天的工作来举例,当我们在做量化交易的时候,如果把数据从CPU拷贝到GPU,再拷贝回来,对于很多量化交易的任务就已经来不及了。也就是说,我们需要有一个非常高性能的、CPU版本的人工智能模型的实现。
再比如,我们有很多任务需要在网卡上直接对数据做分析和处理,而网卡上一般带的是FPGA芯片,它处理的数据如果要传到GPU上就更来不及了。对于这种低时延、又需要人工智能技术帮助的场景,我们需要一个异构的架构。
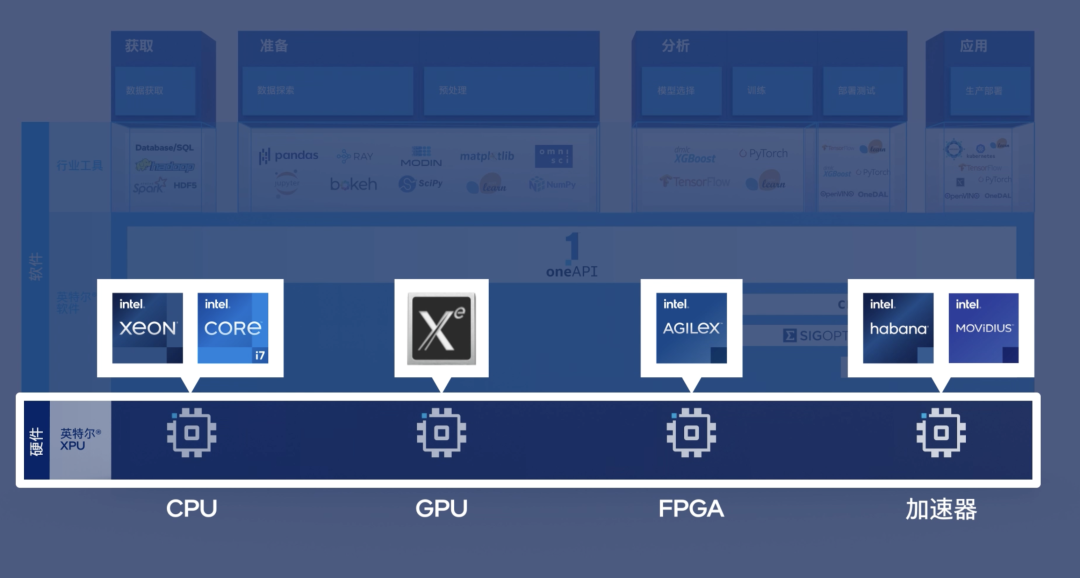
也就是说,不管是FPGA、ASIC,还是CPU、GPU,在不同的场景下,它们都有不同的用武之地。
关于异构平台的编程,我看到工业界已经有了一些尝试。比如英特尔的oneAPI,我觉得是蛮重要的一个工具。也就是说,oneAPI能让同样一套代码能够自动地适配CPU、FPGA或者其他类型的芯片。这样将会大大地减少工程师的编程难度,也能够让他们专注在算法创新上。
我觉得,这对于推动异构应用非常重要。

7、未来人工智能发展的方向,还有哪些?
我觉得,可能需要一个更好的端到端的解决方案。现在其实已经从「软件1.0」升级到了「软件2.0」时代。也就是说,从传统规则驱动的复杂软件工程的构建,变成了数据驱动的软件工程构建方法。
之前,我们要靠很高的聪明才智写一系列精妙的系统,才能让整个程序能够跑起来。这就类似于机械手表,最好的程序员们都把精力放在构建“齿轮”的运转、以及如何让这个“手表”能够跑起来。
现在,如果这一套运行的规则我不知道该怎么定,那就直接把它撂给大量的数据或者机器学习算法,这个算法会生成一个新的算法,而这个新的算法是我们想去得到的东西。这种方式,有点像去造一个造机器人的机器人。

在软件2.0时代,整个软件工程的开发范式将有一个很大的转变,我们很希望得到一套端到端的解决方案,核心就是怎样更方便地实现「以数据为中心」的软件工程开发。
8、人工智能,未来如何落地?
我觉得大概有两方面。第一,从工业界来看,还是要从第一性原理出发,也就是基于自己的需求,并综合考虑到很多的非技术因素。比如我看到有一个公司想做小区安防的人脸识别系统,但每个出入口后面要配4个非常昂贵的GPU,这就是典型的没有从需求和成本出发。
第二,学术研究未必要跟风。就像我们在刚开始时说到的那样,对于模型的规模,并不需要相互攀比:你有一个千亿的,我就要搞个万亿的,你有个万亿的我就要搞一个十万亿的。
其实有大量的任务都需要小规模的参数,或者由于成本等限制,只能提供少量的样本。在这种条件下,怎样做创新和突破?这个是学术界应该主动担起的责任。
9、人工智能创业,还是风口吗?
我们可以想想看,90年代末期,建个网站都要花2-3万元,因为当时会网络编程技术的人凤毛麟角。但是在今天,可能任何一个高中生,鼠标点一点就能建站。
也就是说,网络知识已经在每一个普通程序员的工具包里了。
其实,人工智能技术也是一样。在2015年左右时,搭一套深度学习框架、还要在GPU上能跑起来,全球可能不超过1000个人。而现在经历了指数级别的增长,很多人都会了。我们有理由相信,大概在五年之后,随便一个程序员的工具包里就有更为丰富的人工智能解决方案,它的实现的门槛肯定是在不断降低的。也只有这样,人工智能技术才能更为普遍地应用在每一个公司。
所以,大厂里的AI Lab是必然会消失的。就像2000年前后,很多公司都有一个Internet Lab,就是把公司所有跟网络有关的事情专门搞一个实验室,由这个实验室向其他的业务部门做技术输出。这是因为会这项技术的人特别少,他们才要做这件事情。
AI Lab也是一样的,当AI技术落地的门槛逐渐降低时,大量业务部门的人也拥有类似的技术,那这种AI Lab就必然会消失。我觉得这就是在技术发展过程中一个临时产品,这是个好事情。当大厂没有AI Lab的时候,大概就是人工智能真正遍地开花的年代。
10、人工智能,如何普惠大众?
第一,我们还需要摩尔定律的加持。现在还有大量的任务对算力的要求很大,我们必须不断进行硬件的迭代和算法的更新。只有当需要在集群上跑的事情能在手机上跑,AI才可能有大量的落地。
第二,人工智能创新的重点,要从互联网的业务转向一些传统的行业。之前大家的精力都在怎样用人工智能做更好的视觉解决方案,或者更好的推荐系统,或者更好的P图软件。但在实体经济中,其实也有大量产生数据的部门和业务。当这些实体经济数据能够更好地信息化之后,它们所带来的价值才可能远超于目前的虚拟经济。
想要了解英特尔在高效推进AI实践、加速各行各业云数智转型中发挥的更多作用,请点击“阅读原文”。
中芯国际将告别“先进”仅剩“成熟”?传美拟联合日韩荷对华禁运先进制程制造工具
3.9亿元被冻结!印度严查vivo的背后,中国智能手机厂商遭全面打压
2022Q1全球蜂窝物联网芯片市场:展锐拿下25%份额居第二,华为海思仅剩3%
2022Q1全球智能手机芯片组代工市场:台积电拿下近70%份额!
美国向荷兰政府施压!对华禁售EUV之后,欲再禁DUV光刻机!
行业交流、合作请加微信:icsmart01
芯智讯官方交流群:221807116