
【Python】分享14条非常实用的Pandas函数方法,建议珍藏!!
今天和大家来分享几个十分好用的pandas函数,可能平时并不是特别的常见,但是却能够帮助我们在平时的工作、学习当中极大的提高效率,小编也希望读者朋友们在看完本文之后能够大有收获
使用ExcelWriter()可以向同一个excel的不同sheet中写入对应的表格数据,首先要创建一个writer对象,传入的主要参数为文件名及其路径
import pandas as pda = pd.DataFrame({"a": [1, 2, 3, 4, 5],"b": [2, 5, 6, 8, 10],})b = pd.DataFrame({"c": [5, 2, 3, 1, 4],"d": [2, 5, 7, 8, 10],})
# 写入到同一个excel当中去with pd.ExcelWriter("data.xlsx") as writer:a.to_excel(writer, sheet_name="a_sheet", index = False)b.to_excel(writer, sheet_name="b_sheet", index = False)
pipe()方法可以将一连串的函数以链式的结构嵌套在数据集当中,例如一个脏数据集当中有重复值、空值和极值等等,我们分别建立了3个函数来"drop_duplicates","remove_outliers"和"fill_nans"分别处理上面提到的3个问题,然后用pipe()方法将这三个函数以链式的结构串联起来,作用在同一个数据集上面,代码如下图所示
df_preped = (df.pipe(drop_duplicates).pipe(remove_outliers, ['price', 'carat', 'depth']).pipe(encode_categoricals, ['cut', 'color', 'clarity']))
df = pd.Series([1, 6, 7, [46, 56, 49], 45, [15, 10, 12]]).to_frame("dirty")

df.explode("dirty", ignore_index=True)
data = {'name': ['John', 'Mike', 'Tom', 'Greg', 'Jim'],'income': [8000, 9000, 10000, 10000, 20000],'age': [20, 24, 25, 23, 28]}df = pd.DataFrame(data)
我们挑选出收入在8000到10000范围之内的数据
df[df['income'].between(8000, 10000, inclusive='neither')]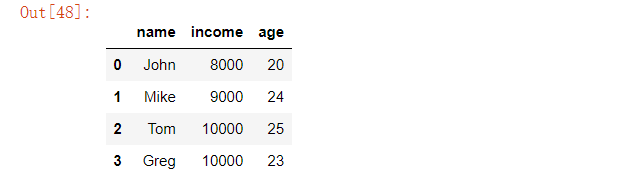
df = pd.DataFrame({'a':[1,2,3],'b':[0.55,0.66,1.55],'c':['Jack','Tony','Posi']})df.dtypes
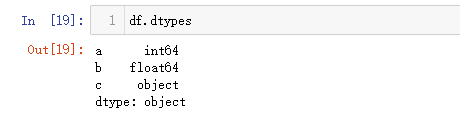
df.convert_dtypes().dtypes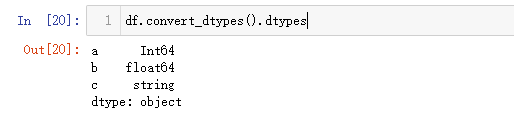
pandas当中的select_dtypes()方法功能是返回那些指定数据类型的列,当中的include顾名思义就是筛选出指定数据类型的列,例如下面我们挑选出是bool数据类型的数据来
a = pd.DataFrame({"a": [1, 2, 3, 4, 5],"b": [True, False, False, True, True],"c": ["John", "Tom", "Mike", "Jim", "Dylan"]})
a.select_dtypes(include='bool')
而exclude就是排除掉指定数据类型的数据,将其他类型的数据筛选出来
a.select_dtypes(exclude='bool')
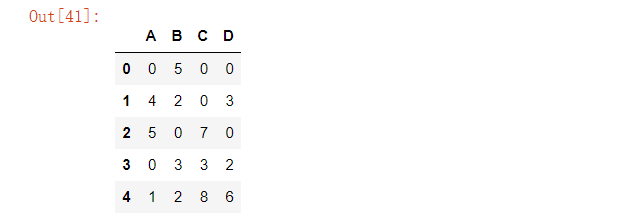
pandas当中的mask()方法主要是对按照指定的条件,对数据集当中的数据进行替换,例如下面数据集当中对于大于0的数据替换成0
df = pd.DataFrame({"A":[12, 4, 5, 44, 1],"B":[5, 2, 54, 3, 2],"C":[20, 16, 7, 3, 8],"D":[14, 3, 17, 2, 6]})
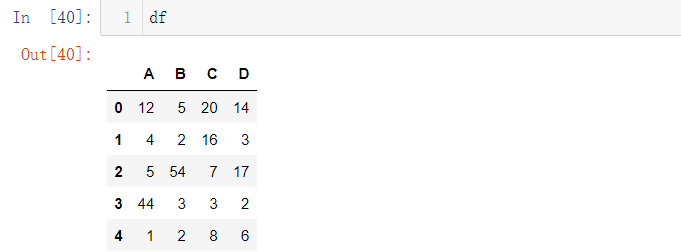
# 将大于10的数字替换成0df.mask(df > 10, 0)
nlargest和nsmallest的作用在于可以让我们看到根据特定的列排序的最大或者是最小的若干列,例如
data = {'name': ['John', 'Mike', 'Tom', 'Greg', 'Jim'],'income': [2500, 4500, 5000, 3000, 2000],'age': [20, 24, 25, 23, 28]}df = pd.DataFrame(data)
我们按照income这一列将数据排序,并且显示出最大的前3行
df.nlargest(3, 'income')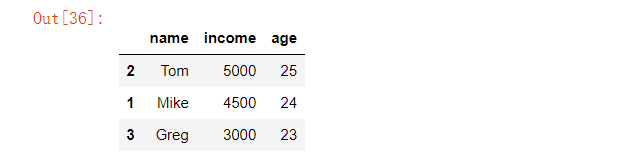
主要用来返回最大值或者是最小值的位置,也就是索引值
data = {'income': [8000, 9000, 10000, 10000, 20000],'age': [20, 24, 25, 23, 28]}df = pd.DataFrame(data, index = ['John', 'Mike', 'Tom', 'Greg', 'Jim'])
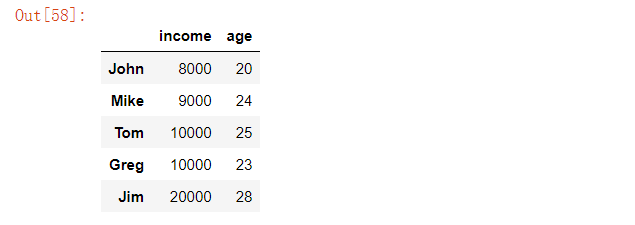
df['income'].idxmax()>>>> Jimdf['income'].idxmin()>>> John
在给出指定范围的前提下,对于数据集当中超出该范围的值进行更改,例如我们将范围限定在-4到6之间,超过6的数字会被设置为6,超过-4的数字会被设置为-4
data = {'col_0': [9, -3, 0, -1, 5],'col_1': [-2, -7, 6, 8, -5]}df = pd.DataFrame(data)
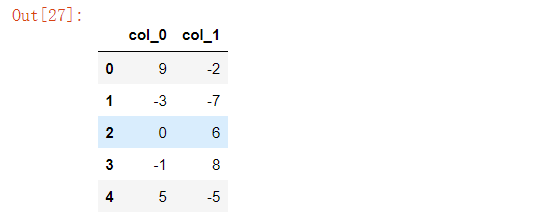
df.clip(-4, 6)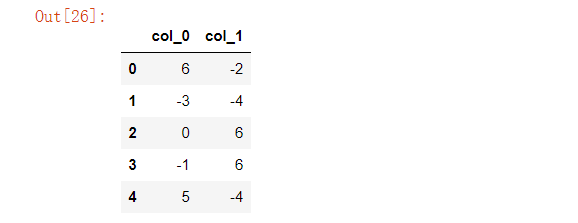
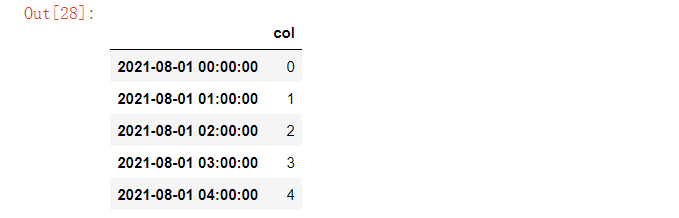
pandas当中at_time()方法和between_time()方法主要是用来处理时间序列的数据,根据给出的时间点或者时间范围来筛选出数据
index = pd.date_range("2021-08-01", periods=100, freq="H")data = pd.DataFrame({"col": list(range(100))}, index=index)data.head()
data.at_time("14:00")data.between_time("11:00", "12:00")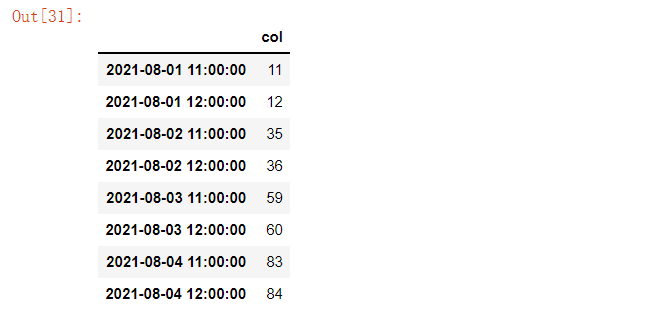
data = {'name': ['John', 'Mike', 'Tom', 'Greg', 'Jim'],'income': [8000, 9000, 10000, 10000, 20000],'age': [20, 24, 25, 23, 28]}df = pd.DataFrame(data)
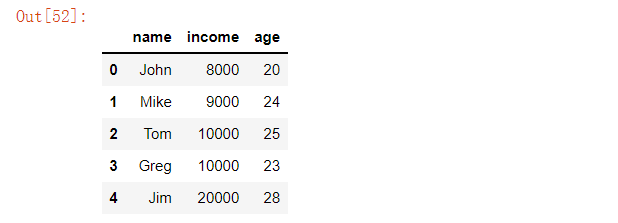
# [index, label]df.at[1, "income"]>>> 9000# [index, index]df.iat[2, 3]>>> 1000
pandas还能够对数据集当中的数据进行上色,我们可以通过该方法将某些我们觉得重要的数据给标注出来,例如我们对数据集中每列的最大值和最小值标注出来
df = pd.DataFrame(np.random.randn(5, 5), columns=list('ABCDE'))# 我们标注出最大、最小的值df.style.highlight_max(color = "yellow")


具体的可以去小编另外写的一篇文章中去看个究竟:厉害了,Pandas表格还能五彩斑斓的展示数据,究竟是怎么做到的呢?
s = pd.Series([2, 4, 6, "abcde", np.nan])s.hasnans>>>> True
往期精彩回顾 本站qq群851320808,加入微信群请扫码: