
丹侠帝貌!英伟达用全新GPU引爆了AI
就像为追求画质极致体验而不断升级自己显卡的游戏玩家一样,AI方向的从业者和爱好者也有属于自己的狂欢节。
自从生成式人工智能席卷全球后,各家公司的模型比拼俨然变成了算力和数据竞争。而浪潮中心的英伟达则备受瞩目,就像这次GTC2024大会的演讲主题一样:“见证AI的变革时刻”。

看完这次会议,最惊讶的还是黄老板带来的新GPU系列,只能说是贫穷限制了自己的想象力
BlackWell——让大模型坐上火箭
在一年前英伟达推出H100时,其股价迎来了飙升,并迅速超过了亚马逊。就在一年后的今天,英伟达再次放出大招——全新GPU系列BlackWell

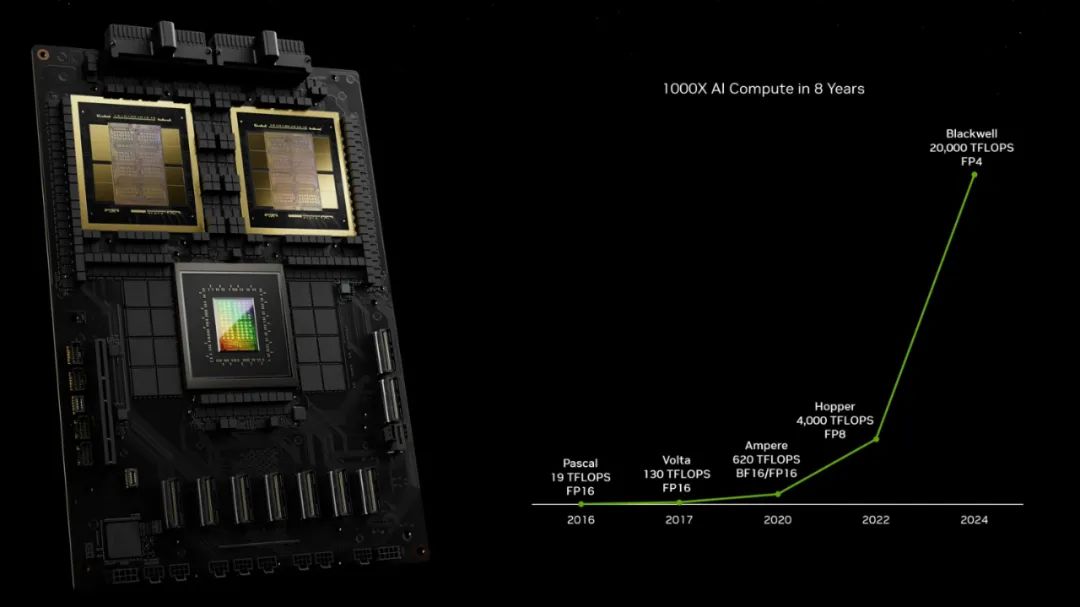
从黄仁勋的描述来看,BlackWell GPU单个晶体管数量就达到2080亿。对比H100的800亿和A100的540亿,有了巨大的提升,直接增加了5倍的AI表现和4倍的芯片内存
展示中,英伟达还提供了两种GPU形式,一种为B200,顾名思义就是将两张B100合二为一,算力达到惊人的20petaFLOPS。

这里petaFLOPS指计算机每秒进行一千万亿次浮点运算(
),相当于现在一张B200就是20台2008年的超级计算机Roadrunner。
更具创意性的是,英伟达将GB200与一张Grace CPU结合,构成了一张“超级芯片”,算力达到40petaFLOPS,能加速大模型推理30倍,并且比H100降低25倍的能源开销。

可以说,GB200不仅降本,还增效,英伟达这次真的是想把AI往AGI上推动了。
直播到这里,黄仁勋展示GB200时几乎每放几张图,台下都会响起掌声,GPU不仅牵动着台下硅谷人的内心,同样也让我期待:
既然Scaling Law(模型参数量越大越可能出现模型涌现)被不断实践证明有效,那么在底层算力不断跟进的背景下,是否会有第二次涌现的机会,即AGI的实现。
观察英伟达产品算力发展时间线,几乎一年算力就有近五倍的增长,如我们熟悉的3060等GPU是4年前的Ampere架构,目前主流的在线深度学习平台Autodl、阿里云等提供的V100、A100等算力则是两年前的Hopper架构,而现在的BlackWell架构算力则是上一代近5倍。
惊喜之余,也有些担忧。就算是上一代的A100、H100也仍然在美国对华禁令之中,而现在BlackWell出来,中美算力差距可能还会进一步加大,
1/4能耗训练GPT4参数量模型
当然,对不熟悉GPU计算的AI爱好者而言,最直接的展示算力方法当然是拿经典的GPT4来做例子了。
按目前透露的GPT4是8个2200亿的MOE模型来看,总体有近1.8万亿参数,相当于5.6个Grok1、10个GPT3.5、25.7个通义千问1.5-70B。
在90天内训练一个GPT4,Hopper系列模型需要8000个GPU的集群,消耗15MW的能量。而2000块GB200,能在同样的天数内,以1/4的能量消耗完成训练!
最后只能说,黄老板的确眼界着实,不仅在GPU深耕多年并在生成式AI时代成为算力第一人,也同时在其他领域不断布局,如会议中提到的生物领域BioNemo、气象领域的CoreDiv以及机器人相关技术。
最后,以黄老板的一句幽默来结束吧
这个,我不知道,100亿美元吧。第二个是5亿,之后就便宜了
