
Deepfake视频中时空不一致学习
【GiantPandaCV导语】
针对Deepfake Video检测任务上的时空不一致问题,提出了三种模块对时间信息、空间信息、时间差异进行建模,能够灵活地即插即用到2D CNN中。
1前言
在本次工作中,我们将时空不一致学习引入到Deepfake Video检测任务上。我们分别提出了三种模块。
Spatial Inconsistency Module (SIM) Temporal Inconsistency Module (TIM) Information Supplement Module (ISM)
具体来说,我们在TIM模块中,利用相邻视频帧在水平,垂直方向时间差异来进行建模。ISM模块则分别利用TIM模块的时间信息,SIM的空间信息,建立更全面的时空表示。上述这三个模块构成的STIL Block是一个灵活的插件模块,可以灵活地插入到2d CNN中。
仓库地址:https://github.com/Holmes-GU/MM-2021(目前暂时是空的,作者后续应该会更新)
论文地址:http://arxiv.org/pdf/2109.01860v1
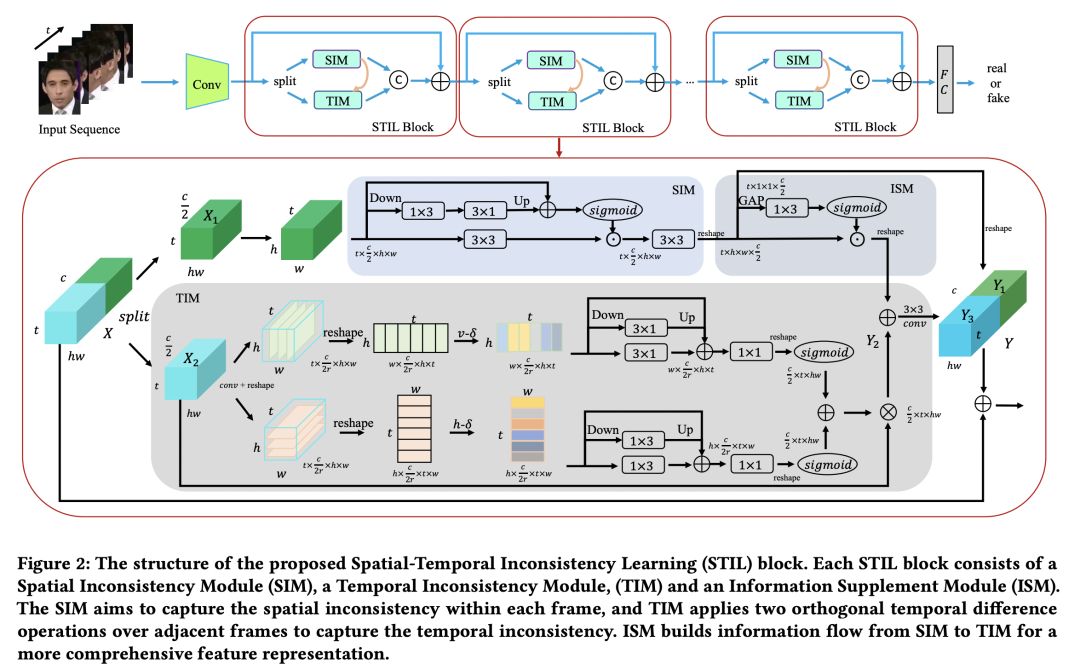
2概览
我们将Deepfake视频检测视为一种二分类问题,给定一段输入视频序列(T,C,H,W),其中T表示的是视频帧数量,使用2D-CNN模型来进行建模。
我们将deepfake视频检测表述为一个时空不一致性的学习过程,并设计了STIL模块,插入到ResNet模型中。
STIL模块是一种双流模型,我们将输入X从通道维上均分得到{X1, X2}。
X1进入到SIM中,以捕捉空间伪造模式。TIM则以逐帧的方式来挖掘deepfake给人脸带来的时间不一致性。ISM则将信息流从空域引入时域(说人话就是把SIM的东西给融进TIM)。最后双流的信息被拼接到一起(还有底下一条残差支路),输入到下一层。
3SIM (Spatial Inconsistency Module)
之前也有一些研究关于GAN中,使用Upsample操作会产生棋盘纹理。
笔者记得是可以通过合理配置stride,kernelsize来避免棋盘纹产生。
并且Deepfake在做人脸融合的时候,融合边缘附近的图像质量并不一致,我们将这些特征视为空间不一致性。
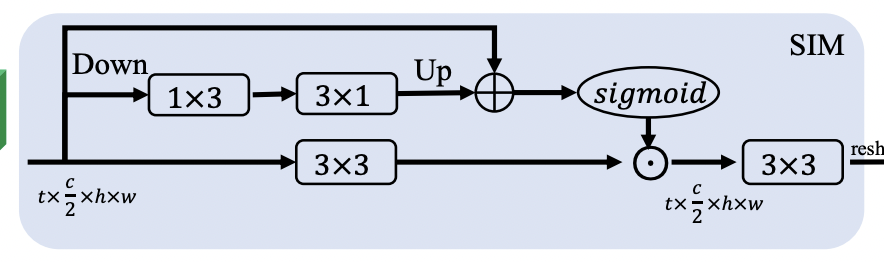
该模块仅考虑空域而不考虑时域,我们将SIM设置为一个3路的模块。首先将通道一分二,SIM的输入是(T, C/2, H, W)。
其中,中路使用了2x2,stride=2的avgpool进行降采样,再跟1x3,3x1的卷积,然后进行上采样,恢复分辨率。 上路是一个残差连接,加到中路,避免降采样带来信息损失 上中路融合的结果经过sigmoid得到置信度,与下路经过3x3卷积的输出后进行相乘
4TIM (Temporal Inconsistency Module)
deepfake基本都是逐帧生成的,没有考虑视频前后的信息,因此给定一个图片来分辨可能很难,但是结合不同帧来看就相对简单了。
视频分类模型基本也是时间,空间解耦合的思想
我们发现分别从水平,垂直方向观察,视频中时间不一致性更加突出。
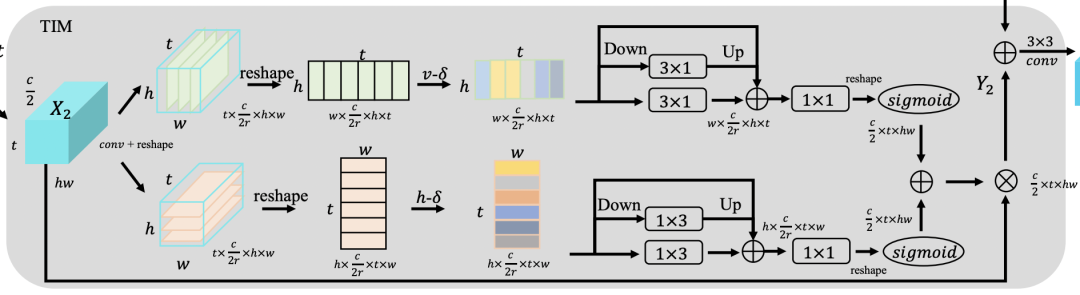 首先输入还是(T, C/2, H, W),经过conv,reshape,给到上下两条支路,分别对水平,垂直方向进行建模。
首先输入还是(T, C/2, H, W),经过conv,reshape,给到上下两条支路,分别对水平,垂直方向进行建模。
注意的是这里reshape将维度做了调整
接着是做一个帧间差操作,以水平方向的支路为例:
就是当前帧经过一层conv,然后减去上一时间帧。
类似地,也是经过一个三支路模块:
上路是残差链接 中路是avgpool + 3x1(如果是水平方向则是1x3) + 上采样 下路是3x1(如果是水平方向则是1x3)
然后相加,经过1x1卷积+sigmoid操作,得到一个类似置信度的东西。
水平方向和垂直方向两个支路的置信度加到一起,与输入X2相乘。
5ISM (Information Supplement Module)
这个模块主要是做信息融合,作者尝试了三种方式
S -> T T -> S S + T
经过消融实验,发现 S -> T 效果最好。
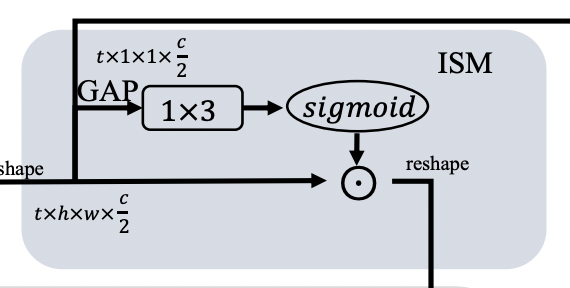
还是分三条路:
上路直接concat到最后输出 中路做了个全局池化,经过1x3卷积+sigmoid得到置信度 下路和置信度相乘,并进一步与TIM的输出一起相乘
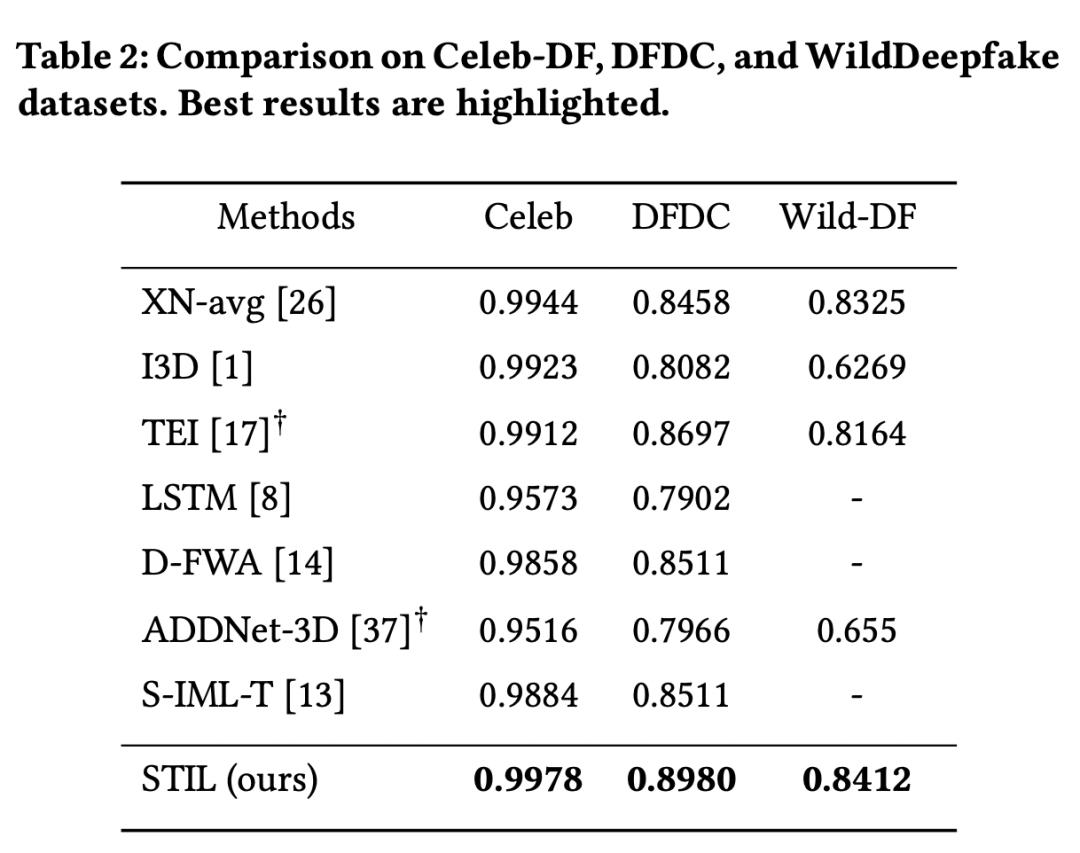
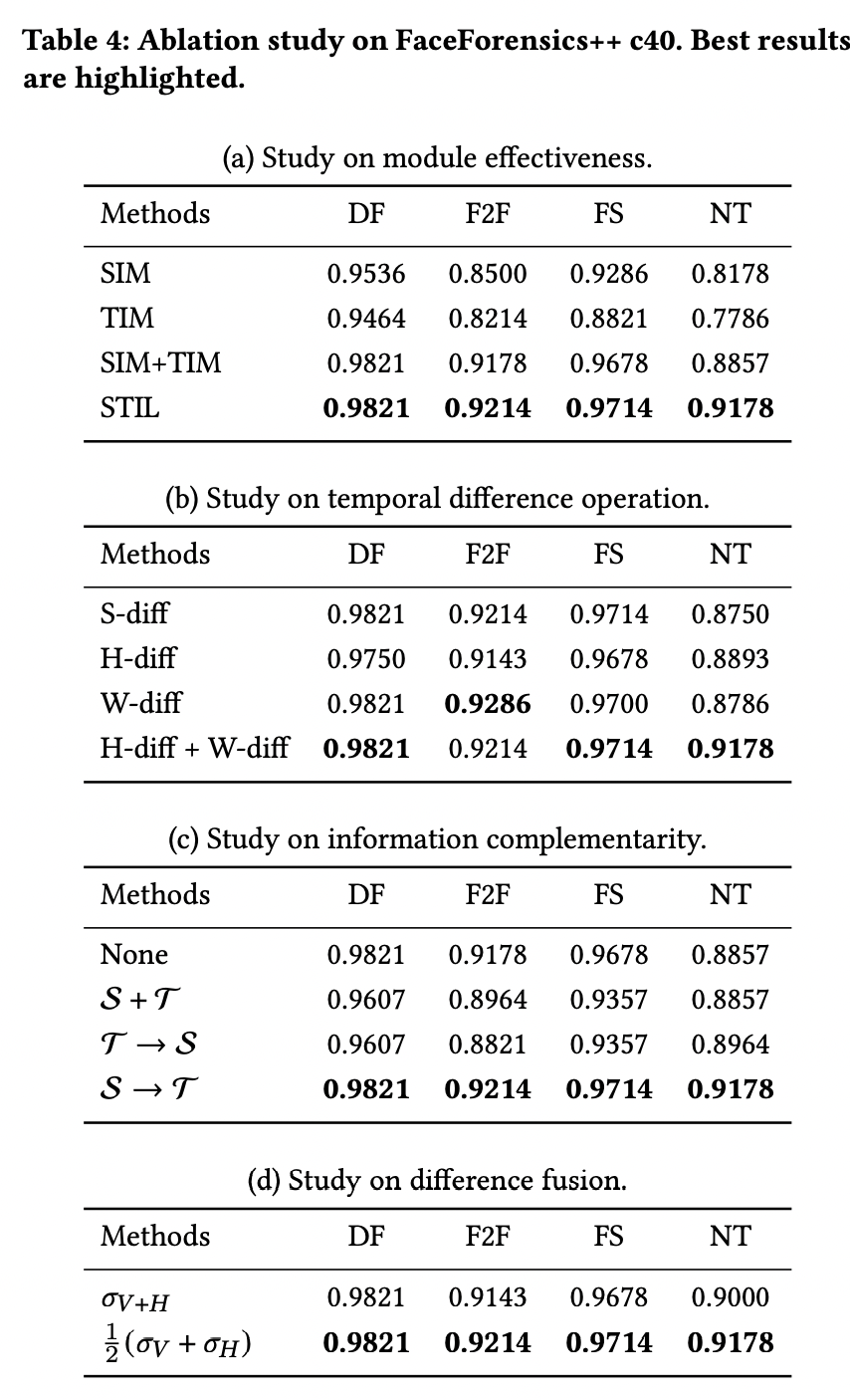
6实验结果
看结果最后都十分不错,并且也做了很完善的消融实验
还有一些STIL Block的可视化图,第1,3行是视频序列,2,4行是heatmap


END

点击在看 支持zzk
