
龙芯:自研GPU首次亮相


下载链接:
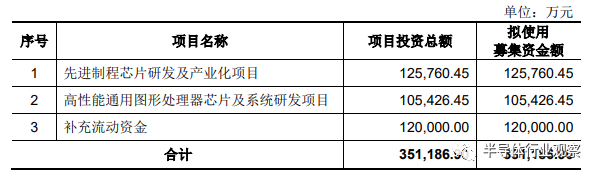
募资35.12亿,投先进制程芯片和GPU芯片
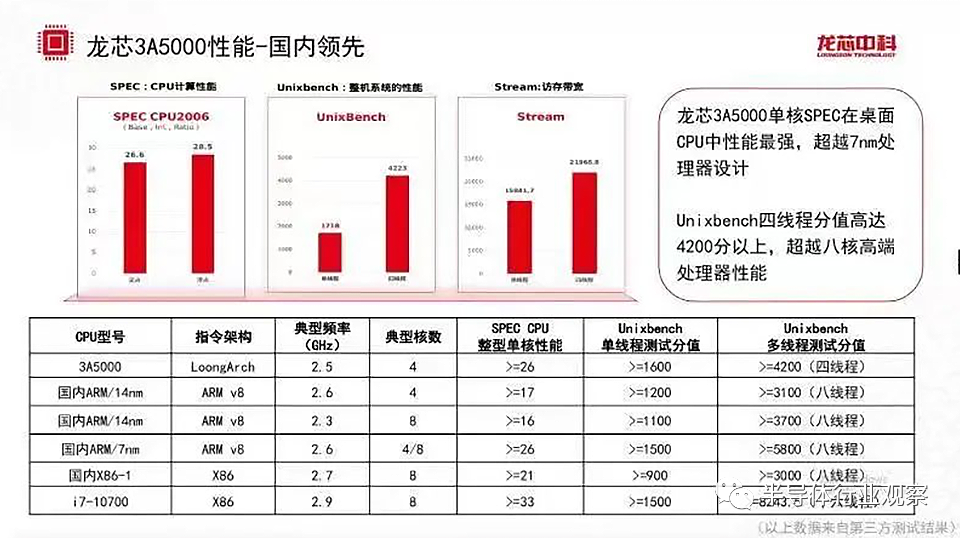
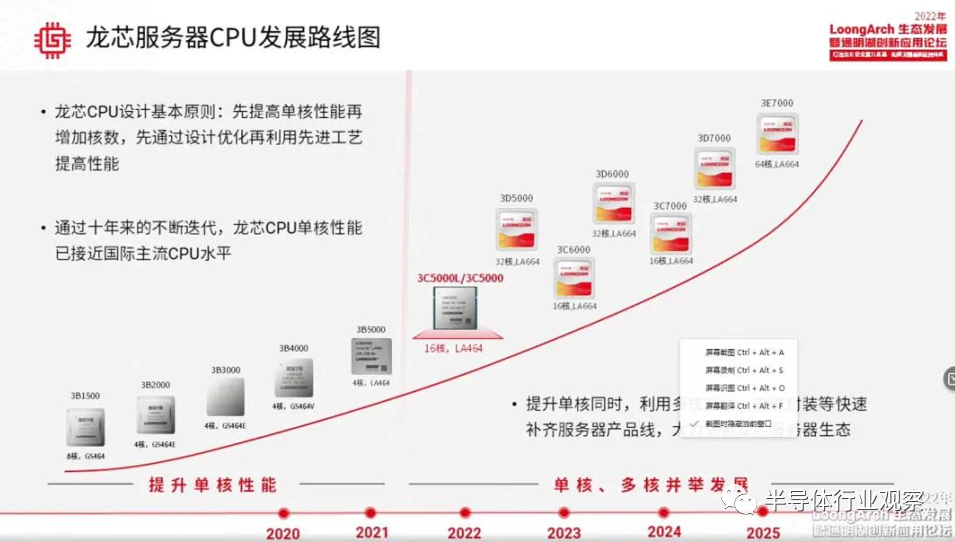
龙芯下一代 CPU ,
可与 AMD 的 Zen 3 匹敌?
下载链接:
1、行业深度报告:GPU研究框架
2、信创产业研究框架
3、ARM行业研究框架
4、CPU研究框架
5、国产CPU研究框架
6、行业深度报告:GPU研究框架
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕。
获取方式:点击“阅读原文”即可查看182页 PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。

评论