
英伟达又一个GAN!PoE-GAN,AI绘图细节拉满,看完直接沸腾了!
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
大家好,我是 阿潘~
最近已经入职新公司了,开启 965 的生活,也开始做新的项目了。最近在适应新环境,不过我依然会努力分享有趣的前沿成果哈。过年的时候,收到小伙伴的私信,说多分享一些实战的内容,以后我也会多多总结一些常见的坑,和大家一起学习成长。
回归正题,今天跟大家分享一篇英伟达的最新成果
提出了一个新的生成对抗网络 (PoE-GAN) 框架,该框架可以合成以多种输入模式或其任何子集为条件的图像。即可以文本 + 分割、文本 + 草图或分割 + 草图等等合成高质量的图像结果。
论文标题:
Multimodal Conditional Image Synthesis with Product-of-Experts GANs
论文、代码和主页链接:
http://arxiv.org/abs/2112.05130
https://deepimagination.cc/PoE-GAN/
摘要
现有的条件图像合成框架基于单一模态中的用户输入生成图像,例如文本、分割、草图或样式参考。它们通常无法在可用时利用多模式用户输入,这降低了它们的实用性。为了解决这一限制,我们提出了专家产品生成对抗网络 (PoE-GAN) 框架,该框架可以合成以多种输入模式或其任何子集为条件的图像,甚至是空集。PoE-GAN 由专家产品生成器和多模态多尺度投影判别器组成。通过我们精心设计的训练方案,PoE-GAN 学会了合成高质量和多样性的图像。除了提高多模态条件图像合成的最新技术水平外,PoE-GAN 在单模态条件下进行测试时也优于现有的最佳单模态条件图像合成方法。
生成效果:

解读
Product-of-Experts
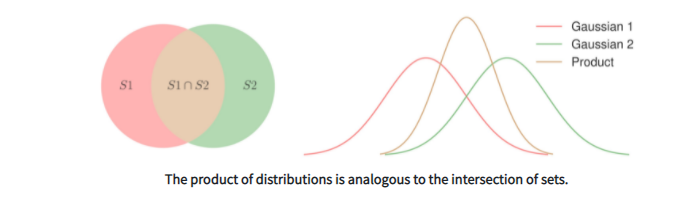
我们的目标是训练一个单一的生成模型,该模型可以捕获以任意模态子集为条件的图像分布。在本文中,我们考虑了四种不同的模式,包括文本、语义分割、草图和样式参考。直观地说,每个输入模态都会增加一个合成图像必须满足的约束。满足所有约束的图像集合是集合的交集,每个集合都满足一个单独的约束。如下图所示,我们通过假设联合条件概率分布与单条件概率分布的乘积成比例来对此进行建模。在此设置下,要使产品分布在某个区域具有高密度,则每个单独的分布都需要在该区域具有高密度,从而满足每个约束。这也被称为 product-of-experts。
Generator Design
下图展示了我们的生成器的架构。我们将每种模态编码为一个特征向量,然后使用专家产品在 Global PoE-Net 中进行聚合。解码器使用 Global PoE-Net 的输出生成图像,并跳过分割和草图编码器的连接。

生成器架构。查看论文获取架构的更多细节。
Discriminator Design
我们提出了一种多模态投影判别器,它将投影判别器推广到处理多个条件输入。与计算图像嵌入和条件嵌入之间的单个内积的标准投影判别器不同,我们为每个输入模态计算一个内积并将它们加在一起以获得最终损失。
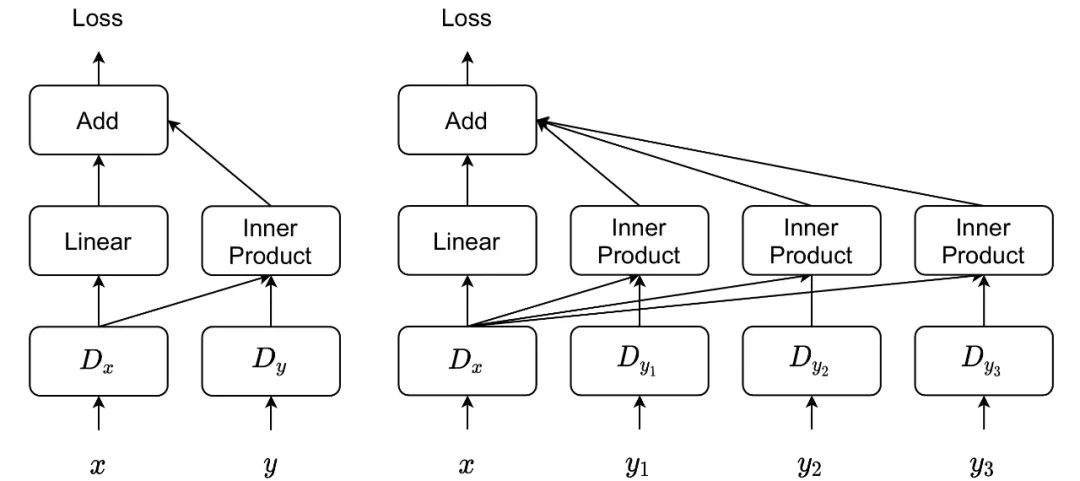
标准投影判别器(左)和本文的多模态投影判别器(右)之间的比较。
Results
当使用单一输入模态进行测试时,PoE-GAN 优于以前专门为该模态设计的 state-of-the-art方法,例如分割到图像的方法(SPADE、OASIS)和文本到图像的合成方法 (DF-GAN,DM-GAN + CL)。






当以任意模态子集为条件时,PoE-GAN 可以产生不同的输出图像。下面我们展示了来自 PoE-GAN 的随机样本,这些样本基于风景图像数据集上的两种模式(文本 + 分割、文本 + 草图和分割 + 草图)。


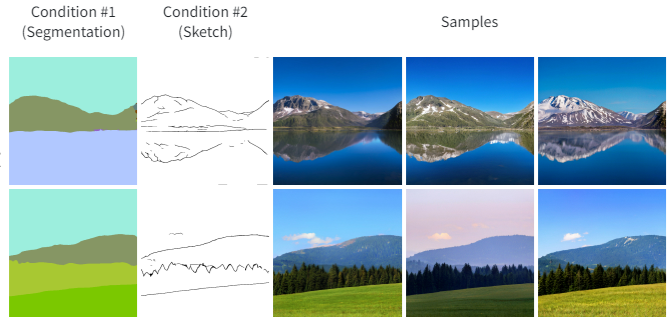
下面我们展示了来自 PoE-GAN 的随机样本,这些样本基于两种模式,包括样式参考(分割 + 样式、文本 + 样式和草图 + 样式)。



在没有输入模式的情况下,PoE-GAN 成为无条件生成模型。以下是由 PoE-GAN 无条件生成的未经处理的样本。



好的,今天的分享就到这里,更多细节查看论文
推荐阅读
CVPR2021 最具创造力的那些工作成果!或许这就是计算机视觉的魅力!