
YOLOv7 自定义数据训练
对象检测技术被广泛用作业界许多应用程序的后端,包括桌面和 Web 应用程序。此外,它是许多计算机视觉任务的支柱,包括对象分割、对象跟踪、对象分类、对象计数等。在现代,每个人对任何应用程序的目标是:
应用程序必须易于使用、处理时间更少并提供最佳结果。
日前,YOLOv7 已经发布,由AlexeyAB(YOLOv4作者)和WongKinYiu(YOLOR作者)投稿。与YOLOR、YOLOv5 和 YOLOX 相比,YOLOv7 实现的目的是达到更高的准确性。
作者AlexeyAB:https://github.com/AlexeyAB
YOLOv4:https://github.com/AlexeyAB/darknet
作者WongKinYiu:https://github.com/WongKinYiu
YOLOR:https://github.com/WongKinYiu/yolor
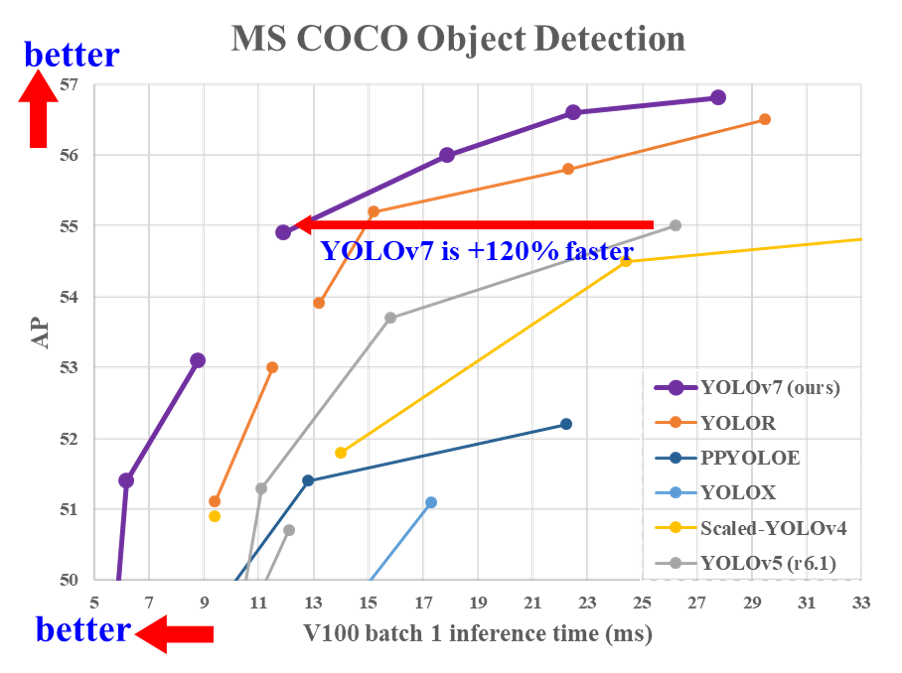
Fig-1 来源:YOLOv7 BenchMarks [ https://github.com/WongKinYiu/yolov7 ]
在图 1 中,你可以清楚地看到 YOLOv7 在精度和速度方面都超过了 YOLOX、PP-YOLOE、YOLOR 和 YOLOv5。YOLOv7 的开发是在 PyTorch 中完成的。
在本文中,我们将重点介绍“自定义数据上的 YOLOv7 训练”。你可以按照下面提到的步骤在你自己的数据上训练 YOLOv7。
所有提到的步骤都已在Ubuntu 18.04 和 20.04上使用 CUDA 10.x/11.x 进行了测试。
模块安装
预训练对象检测
自定义数据训练
使用自定义权重进行推理
模块安装:
创建一个名为“ YOLOv7 ”的文件夹。在“YOLOv7”文件夹中打开终端/cmd,使用上述命令创建一个虚拟环境,然后激活它。
python3 -m venv yolov7training #creation of virtual environment
source yolov7training/bin/activate #activation of virtualenvxxxxxxxxxx python3 -m venv yolov7training #creation of virtual environmentsource yolov7training/bin/activate #activation of virtualenvpython3 -m venv yolov7training #创建虚拟环境源码 yolov7training/bin/activate #激活virtualenv
注意:以上步骤不是必需的,但如果你不想打扰 python 系统包,建议你使用。
从链接:https://github.com/WongKinYiu/yolov7 克隆 YOLOv7 存储库,升级 pip 并使用上述命令移动到克隆的文件夹。
git clone https://github.com/WongKinYiu/yolov7.git
cd yolov7
pip install --upgrade pip
我们需要安装所有有助于 YOLOv7 训练的库。你可以使用提到的命令来安装所需的模块。
pip install -r requirements.txt
sudo apt install -y zip htop screen libgl1-mesa-glx
预训练的目标检测
我们已经安装了所有模块。我们现在使用预先训练的权重测试检测,以确认我们所有的模块都工作正常。你可以在终端/cmd 中使用上述命令来检测具有预训练权重的对象。
注意: YOLOv7 权重必须在 yolov7 文件夹中,从这个链接:https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7.pt)下载预训练的权重文件并将下载的文件移动到当前工作目录**{** yolov7}
python detect.py --weights yolov7.pt --source inference/images/horses.jpg --img 640
如果一切正常,那么你将能够在下面提到的目录中获得结果。
结果目录:[yolov7/runs/detect/exp/horses.jpg]

Fig-2 【来源】YOLOv7 官方仓库:https://github.com/WongKinYiu/yolov7/blob/main/inference/images/horses.jpg
在自定义数据上训练 YOLOv7
自定义训练的步骤如下:
1- 收集数据
2- 标记数据
3- 拆分数据(训练和测试)
4- 创建配置文件
5- 开始训练
第 1 步:我们需要为YOLOv7 自定义训练创建一个数据集。如果你没有数据,你可以使用 openimages数据库中的数据集。
openimages:https://storage.googleapis.com/openimages/web/index.html
YOLOv7 在 text(.txt) 文件中获取标签数据,格式如下:
<object-class-id> <x> <y> <width> <height>

图 3:YOLO 标记样本
第 2 步:对于自定义数据的标记,请查看我的文章,内容是为对象检测标记数据 (Yolo:https://medium.com/nerd-for-tech/labeling-data-for-object-detection-yolo-5a4fa4f05844)
第 3 步:标记数据后,我们现在需要将数据拆分为训练和测试文件夹。拆分比例将取决于用户,而通常优选的拆分为 (80–20)%,这意味着 80% 的数据用于训练,而 20% 的数据用于测试。
对于数据拆分,你可以查看python-library:https://pypi.org/project/split-folders/),它将你的数据随机拆分为训练、测试和验证。
文件夹结构:
├── yolov7
## └── train
####└── images (folder including all training images)
####└── labels (folder including all training labels)
## └── test
####└── images (folder including all testing images)
####└── labels (folder including all testing labels)
第 4 步:现在我们需要创建一个自定义配置文件。(确保设置正确的路径),因为训练过程将完全依赖于该文件。
创建文件名为“custom. yaml”,在 (yolov7/data) 文件夹中。将以下代码粘贴到该文件中。设置数据集文件夹的正确路径,更改类及其名称,然后保存。
train: (Complete path to dataset train folder)
test: (Complete path to dataset test folder)
valid: (Complete path to dataset valid folder)
#Classes
nc: 1 # replace according to your number of classes
#classes names
#replace all class names list with your classes names
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush']
第 5 步:所有预处理步骤都完成了,是时候开始训练了。在主“yolo v7 ”中打开终端,激活虚拟环境,然后运行下面提到的命令。
source yolov7training/bin/activate
python train.py --weights yolov7.pt --data "data/custom.yaml" --workers 4 --batch-size 4 --img 416 --cfg cfg/training/yolov7.yaml --name yolov7 --hyp data/hyp.scratch.p5.yaml
or
python3 train.py --weights yolov7.pt --data "data/custom.yaml" --workers 4 --batch-size 4 --img 416 --cfg cfg/training/yolov7.yaml --name yolov7 --hyp data/hyp.scratch.p5.yaml --epochs 50
-- img = 模型将训练的图像大小,默认值为 640。
-- batch-size= 训练中使用的批量大小。
-- epochs = 训练 epoch 的数量
-- data = 自定义配置文件的路径
-- 权重= 预训练的权重
yolov7.pt:https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7_training.pt
yolov7x.pt:https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7x_training.pt
yolov7-w6.pt:https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-w6_training.pt
yolov7-e6.pt:https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-e6_training.pt

图 4:YOLOv7 训练开始
注意:如果出现任何图像损坏的话,训练将不会开始,如果是某些标签文件损坏,那么训练不会有问题,因为 yolov7 将忽略该图像和标签文件。
等待训练完成,然后使用新创建的权重进行推理。自定义训练的权重将保存在下面提到的文件夹路径中。
[yolov7/runs/train/yolov7/weights/best.pt]
使用自定义权重进行推理
训练完成后,转到终端并运行下面提到的命令以检测自定义权重。
python detect.py --weights runs/train/yolov7/weights/best.pt --source "path to your testing image"
我使用 Person 数据进行训练,自定义权重的结果如下所示。
查看视频:https://youtu.be/hAdyEobLBnQ
基于自定义数据的 YOLOv7 人员检测
这就是“在自定义数据上训练 YOLOv7”的全部内容。你可以对自己的数据进行尝试。
从视频创建数据集:文章链接:https://medium.com/nerd-for-tech/extraction-of-frames-from-a-single-video-2b9fdd901208
自定义训练的标签数据:文章链接:https://medium.com/nerd-for-tech/labeling-data-for-object-detection-yolo-5a4fa4f05844
在自定义数据上训练 YOLO-v5:文章链接:https://medium.com/nerd-for-tech/how-to-train-yolov5-on-custom-data-9983a545e509
如何修剪和稀疏 YOLOv5:文章链接:https://medium.com/nerd-for-tech/how-to-prune-sparse-yolov5-da19e1d84a6
YOLOv5 的超参数如何工作:文章链接:https://chr043416.medium.com/how-hyperparameters-of-yolov5-works-ec4d25f311a2