
CVPR 2023 | SCConv: 即插即用的空间和通道重建卷积(附源码)
导读
今天看新闻的时候不经意间刷到这个,看了下介绍主要是提出了一个新颖的卷积模块SCConv[1],名字含义是结合空间和通道的重组卷积,此模块目标在于减少视觉任务中由于冗余特征提取而产生的计算成本。
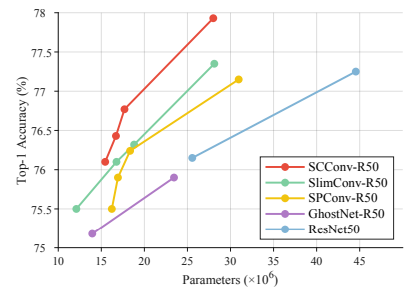
Top1-Accuracy v.s. FLOPs for ResNet50 on ImageNet
Self-Calibrated Convolutions
这里需要提两点,第一点是名字的争议,这个跟前两年程明明教授团队于 2020 年发表在 CVPR 上的 SCNet 中提出的 SCConv 不是同一个工作哈:
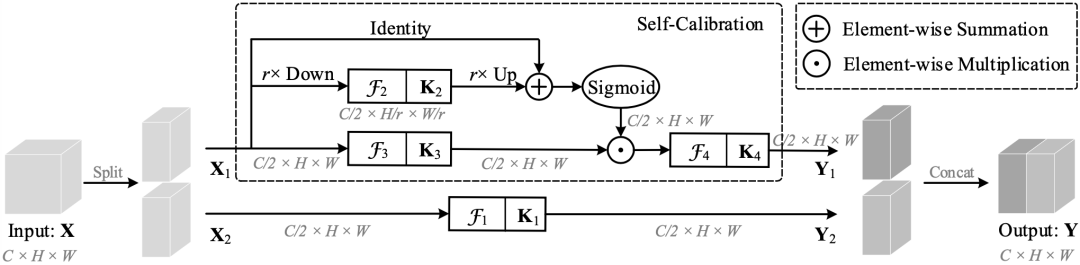
不同于标准卷积采用小尺寸核同时融合空域与通道信息,SCNet 中所设计的 SCConv 可以通过自矫正操作自适应构建远距离空间域与通道间相关性。SCConv 的这种特性可以帮助 CNNs 生成更具判别能力的特征表达,因其具有更丰富的信息。另外这个结构也是极为简单且通用,可以轻易嵌入到现有架构中,而不会导致参数量增加与计算复杂度提升。
class SCConv(nn.Module):
def __init__(self, inplanes, planes, stride, padding, dilation, groups, pooling_r, norm_layer):
super(SCConv, self).__init__()
self.k2 = nn.Sequential(
nn.AvgPool2d(kernel_size=pooling_r, stride=pooling_r),
nn.Conv2d(inplanes, planes, kernel_size=3, stride=1,
padding=padding, dilation=dilation,
groups=groups, bias=False),
norm_layer(planes),
)
self.k3 = nn.Sequential(
nn.Conv2d(inplanes, planes, kernel_size=3, stride=1,
padding=padding, dilation=dilation,
groups=groups, bias=False),
norm_layer(planes),
)
self.k4 = nn.Sequential(
nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride,
padding=padding, dilation=dilation,
groups=groups, bias=False),
norm_layer(planes),
)
def forward(self, x):
identity = x
out = torch.sigmoid(torch.add(identity, F.interpolate(self.k2(x), identity.size()[2:]))) # sigmoid(identity + k2)
out = torch.mul(self.k3(x), out) # k3 * sigmoid(identity + k2)
out = self.k4(out) # k4
return out
Octave Convolution
第二点是关于从“冗余特征提取”角度,其实也有很多类似的工作,例如华为的GhostNet,或者 ICCV 2019 提出的 Octave Convolution,名字也挺有意思的,取名灵感来自于音乐的不同音符,寓意在于高、低频率:
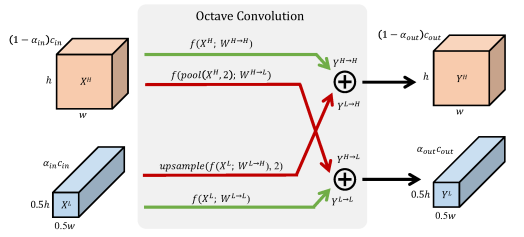
文中提到,不仅自然世界中的图像存在高低频,卷积层的输出特征图以及输入通道,也都存在高、低频分量。低频分量支撑的是整体轮廓,高频分量则关注细节,显然,低频分量是存在冗余的,在编码过程中可以节省。
class OctConv(torch.nn.Module):
"""
This module implements the OctConv paper https://arxiv.org/pdf/1904.05049v1.pdf
"""
def __init__(self, in_channels, out_channels, kernel_size, stride=1, alpha_in=0.5, alpha_out=0.5):
super(OctConv, self).__init__()
self.alpha_in, self.alpha_out, self.kernel_size = alpha_in, alpha_out, kernel_size
self.H2H, self.L2L, self.H2L, self.L2H = None, None, None, None
if not (alpha_in == 0.0 and alpha_out == 0.0):
self.L2L = torch.nn.Conv2d(int(alpha_in * in_channels),
int(alpha_out * out_channels),
kernel_size, stride, kernel_size//2)
if not (alpha_in == 0.0 and alpha_out == 1.0):
self.L2H = torch.nn.Conv2d(int(alpha_in * in_channels),
out_channels - int(alpha_out * out_channels),
kernel_size, stride, kernel_size//2)
if not (alpha_in == 1.0 and alpha_out == 0.0):
self.H2L = torch.nn.Conv2d(in_channels - int(alpha_in * in_channels),
int(alpha_out * out_channels),
kernel_size, stride, kernel_size//2)
if not (alpha_in == 1.0 and alpha_out == 1.0):
self.H2H = torch.nn.Conv2d(in_channels - int(alpha_in * in_channels),
out_channels - int(alpha_out * out_channels),
kernel_size, stride, kernel_size//2)
self.upsample = torch.nn.Upsample(scale_factor=2, mode='nearest')
self.avg_pool = partial(torch.nn.functional.avg_pool2d, kernel_size=kernel_size, stride=kernel_size)
def forward(self, x):
hf, lf = x
h2h, l2l, h2l, l2h = None, None, None, None
if self.H2H is not None:
h2h = self.H2H(hf)
if self.L2L is not None:
l2l = self.L2L(lf)
if self.H2L is not None:
h2l = self.H2L(self.avg_pool(hf))
if self.L2H is not None:
l2h = self.upsample(self.L2H(lf))
hf_, lf_ = 0, 0
for i in [h2h, l2h]:
if i is not None:
hf_ = hf_ + i
for i in [l2l, h2l]:
if i is not None:
lf_ = lf_ + i
return hf_, lf_
SCConv
好了,解释完这两个疑惑点后,我们简单了解下今天的主角做了什么。
冗余特征提取的问题
我们知道,卷积在各种计算机视觉任务中表现出色,但是由于卷积层提取冗余特征,其计算资源需求巨大。虽然过去用于改善网络效率的各种模型压缩策略和网络设计,包括网络剪枝、权重量化、低秩分解和知识蒸馏等。然而,这些方法都被视为后处理步骤,因此它们的性能通常受到给定初始模型的上限约束。而网络设计另辟蹊径,试图减少密集模型参数中的固有冗余,进一步开发轻量级网络模型。
SCConv模块的设计
为了解决上述问题,论文提出了一个新的卷积模块,名为SCConv,这个模块利用了两个组件:空间重建单元(SRU)和通道重建单元(CRU)。
SRU 通过一种分离-重建的方法抑制空间冗余
CRU 则采用一种分割-转换-融合的策略减少通道冗余
此外,SCConv 是一个即插即用的架构单元,可以直接替换各种卷积神经网络中的标准卷积。
SCConv模块的性能
SCConv 模块旨在有效地限制特征冗余,不仅减少了模型参数和FLOPs的数量,而且增强了特征表示的能力。实际上,SCConv 模块提供了一种新的视角来看待CNNs的特征提取过程,提出了一种更有效地利用空间和通道冗余的方法,从而在减少冗余特征的同时提高模型性能。实验结果显示,嵌入了 SCConv 模块的模型能够通过显著降低复杂性和计算成本,减少冗余特征,从而达到更好的性能。
方法
方法部分没什么详细解释的必要,我们简单的过一遍即可,有需要的同学完全可以基于此项工作进一步应用到各种非自然图像的任务上,也不用愁论文没创新点可以改进。
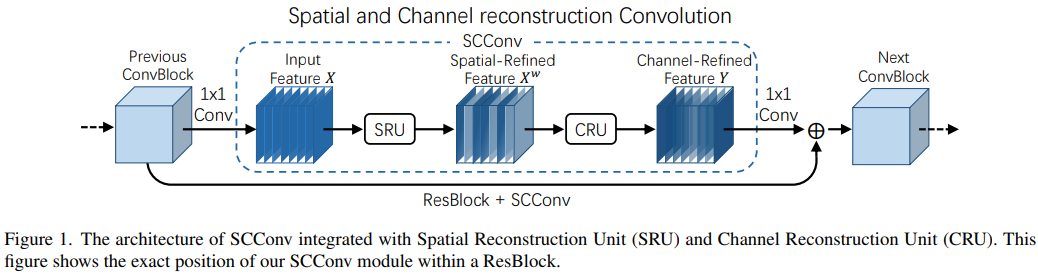
是不是很简单,一个 latent-space 的表征,经过一个空间和一个通道组件的增强,获取更具有判别里的特征表示。模块的设计范式也是很常规,跟SK-Net的Split-Transform-Merge雷同。笔者也确实没想到,2320 年了此类型的工作居然还能中 CVPR,只能说且看且珍惜吧。遗憾的是,作者时至今日居然还没开源代码,呃,不过有 github 上有同学稍微复现了下,下面贴两段代码[2]有需要可以自取。
SRU
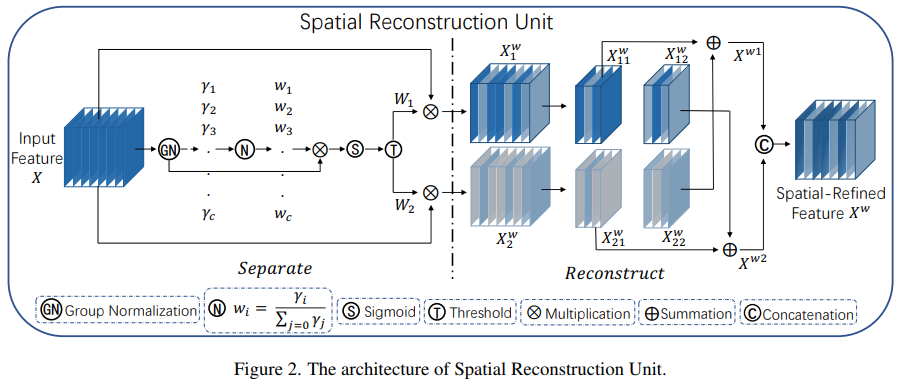
class GroupBatchnorm2d(nn.Module):
def __init__(self, c_num:int,
group_num:int = 16,
eps:float = 1e-10
):
super(GroupBatchnorm2d,self).__init__()
assert c_num >= group_num
self.group_num = group_num
self.gamma = nn.Parameter( torch.randn(c_num, 1, 1) )
self.beta = nn.Parameter( torch.zeros(c_num, 1, 1) )
self.eps = eps
def forward(self, x):
N, C, H, W = x.size()
x = x.view( N, self.group_num, -1 )
mean = x.mean( dim = 2, keepdim = True )
std = x.std ( dim = 2, keepdim = True )
x = (x - mean) / (std+self.eps)
x = x.view(N, C, H, W)
return x * self.gamma + self.beta
class SRU(nn.Module):
def __init__(self,
oup_channels:int,
group_num:int = 16,
gate_treshold:float = 0.5
):
super().__init__()
self.gn = GroupBatchnorm2d( oup_channels, group_num = group_num )
self.gate_treshold = gate_treshold
self.sigomid = nn.Sigmoid()
def forward(self,x):
gn_x = self.gn(x)
w_gamma = F.softmax(self.gn.gamma,dim=0)
reweigts = self.sigomid( gn_x * w_gamma )
# Gate
info_mask = w_gamma>self.gate_treshold
noninfo_mask= w_gamma<=self.gate_treshold
x_1 = info_mask*reweigts * x
x_2 = noninfo_mask*reweigts * x
x = self.reconstruct(x_1,x_2)
return x
def reconstruct(self,x_1,x_2):
x_11,x_12 = torch.split(x_1, x_1.size(1)//2, dim=1)
x_21,x_22 = torch.split(x_2, x_2.size(1)//2, dim=1)
return torch.cat([ x_11+x_22, x_12+x_21 ],dim=1)
CRU
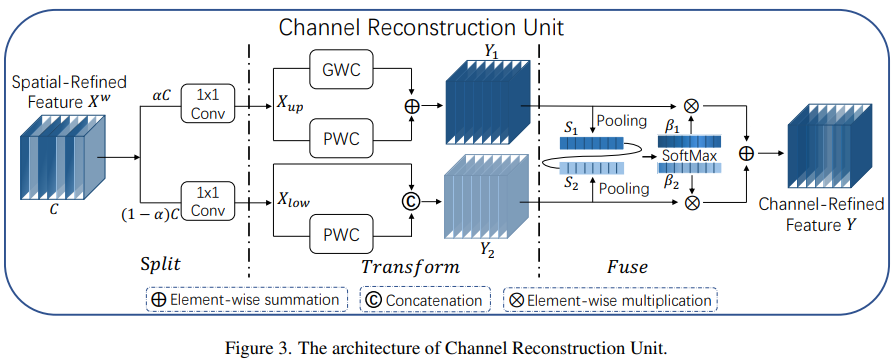
class CRU(nn.Module):
'''
alpha: 0<alpha<1
'''
def __init__(self,
op_channel:int,
alpha:float = 1/2,
squeeze_radio:int = 2 ,
group_size:int = 2,
group_kernel_size:int = 3,
):
super().__init__()
self.up_channel = up_channel = int(alpha*op_channel)
self.low_channel = low_channel = op_channel-up_channel
self.squeeze1 = nn.Conv2d(up_channel,up_channel//squeeze_radio,kernel_size=1,bias=False)
self.squeeze2 = nn.Conv2d(low_channel,low_channel//squeeze_radio,kernel_size=1,bias=False)
#up
self.GWC = nn.Conv2d(up_channel//squeeze_radio, op_channel,kernel_size=group_kernel_size, stride=1,padding=group_kernel_size//2, groups = group_size)
self.PWC1 = nn.Conv2d(up_channel//squeeze_radio, op_channel,kernel_size=1, bias=False)
#low
self.PWC2 = nn.Conv2d(low_channel//squeeze_radio, op_channel-low_channel//squeeze_radio,kernel_size=1, bias=False)
self.advavg = nn.AdaptiveAvgPool2d(1)
def forward(self,x):
# Split
up,low = torch.split(x,[self.up_channel,self.low_channel],dim=1)
up,low = self.squeeze1(up),self.squeeze2(low)
# Transform
Y1 = self.GWC(up) + self.PWC1(up)
Y2 = torch.cat( [self.PWC2(low), low], dim= 1 )
# Fuse
out = torch.cat( [Y1,Y2], dim= 1 )
out = F.softmax( self.advavg(out), dim=1 ) * out
out1,out2 = torch.split(out,out.size(1)//2,dim=1)
return out1+out2
实验
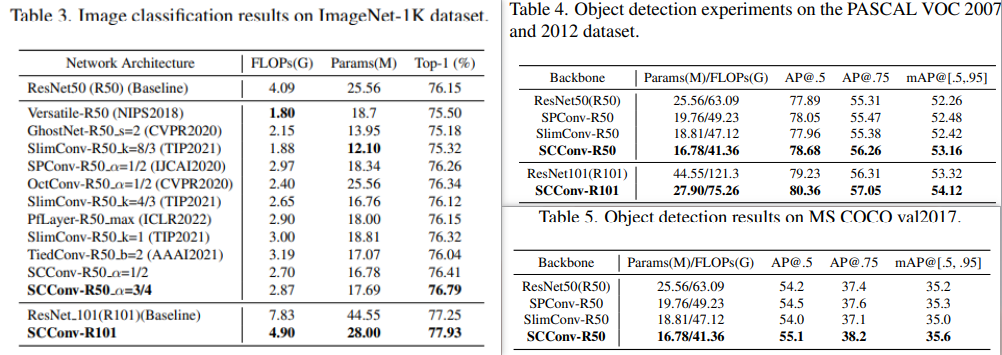
总结
简单总结下吧,本文主要提出了一个新颖的空间和通道重建模块(SCConv),这是一个有效的架构单元,能够通过减少广泛存在于标准卷积中的空间和通道冗余,降低计算成本和模型存储,同时提高CNN模型的性能。通过SRU和CRU,减少了特征图的冗余,同时实现了显著的性能改善,大幅减少了计算负载。此外,SCConv 是一个即插即用的模块,并且通用于替换标准卷积,无需任何模型架构调整。
References
[1]
paper: https://openaccess.thecvf.com/content/CVPR2023/papers/Li_SCConv_Spatial_and_Channel_Reconstruction_Convolution_for_Feature_Redundancy_CVPR_2023_paper.pdf
[2]code: https://github.com/cheng-haha/ScConv/blob/main/ScConv.py