
3D点云 (Lidar)检测入门篇 : PointPillars PyTorch实现
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达

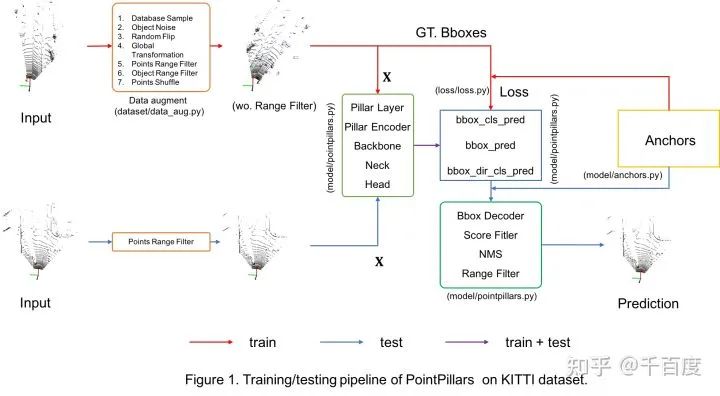
一、KITTI 3D检测数据集
1.1 数据集信息:
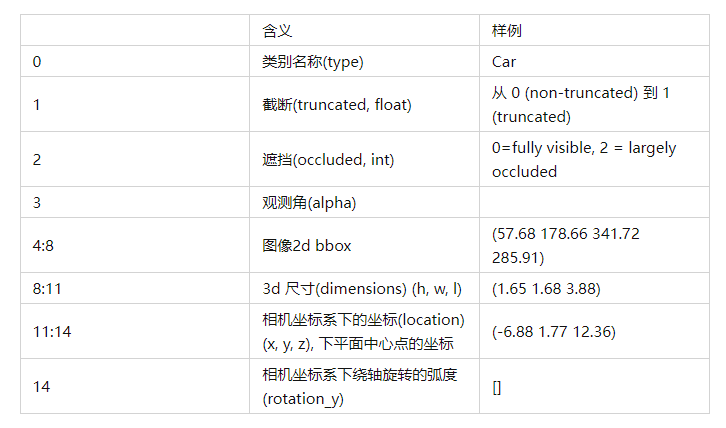
utils/io.py。1.2 ground truth label信息 [file]
1.3 坐标系的变换
utils/process.py。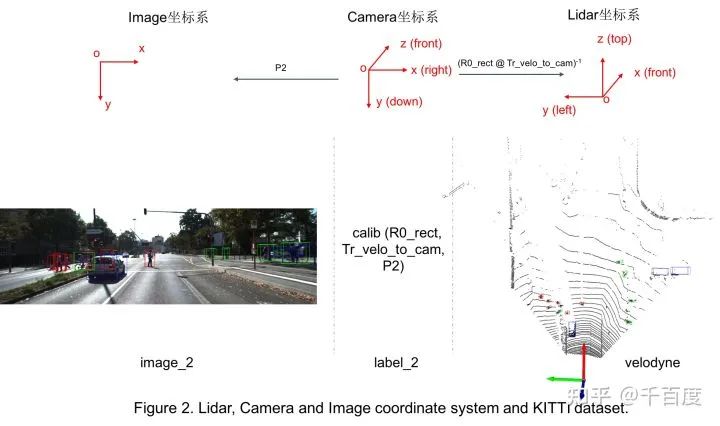
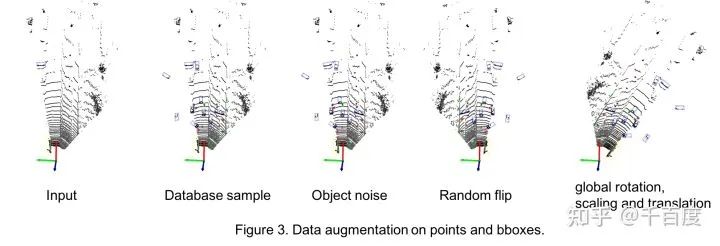
1.4 数据增强
dataset/data_aug.py。采样gt bbox并将其复制到当前帧的点云 从Car, Pedestrian, Cyclist的database数据集中随机采集一定数量的bbox及inside points, 使每类bboxes的数量分别达到15, 10, 10. 将这些采样的bboxes进行碰撞检测, 通过碰撞检测的bboxes和对应labels加到gt_bboxes_3d, gt_labels 把位于这些采样bboxes内点删除掉, 替换成bboxes内部的点. bbox 随机旋转平移 以某个bbox为例, 随机产生num_try个平移向量t和旋转角度r, 旋转角度可以转成旋转矩阵(mat). 对bbox进行旋转和平移, 找到num_try中第一个通过碰撞测试的平移向量t和旋转角度r(mat). 对bbox内部的点进行旋转和平移. 对bbox进行旋转和平移. 随机水平翻转 points水平翻转 bboxes水平翻转 整体旋转/平移/缩放 object旋转, 缩放和平移 point旋转, 缩放和平移 对points进行shuffle: 打乱点云数据中points的顺序。
二、网络结构与训练


2.2 GT值生成
model/anchors.py

2.3 损失函数和训练
loss/loss.py。
torch.optim.AdamW(), 学习率的调整torch.optim.lr_scheduler.OneCycleLR(); 模型共训练160epoches。三、单帧预测和可视化
model/pointpillars.py。一般经过以下几个步骤:
过滤掉类别score 小于 score_thr (0.1) 的bboxes 基于nms_thr (0.01), nms过滤掉重叠框:

test.py和utils/vis_o3d.py。下图是对验证集中id=000134的数据进行可视化的结果。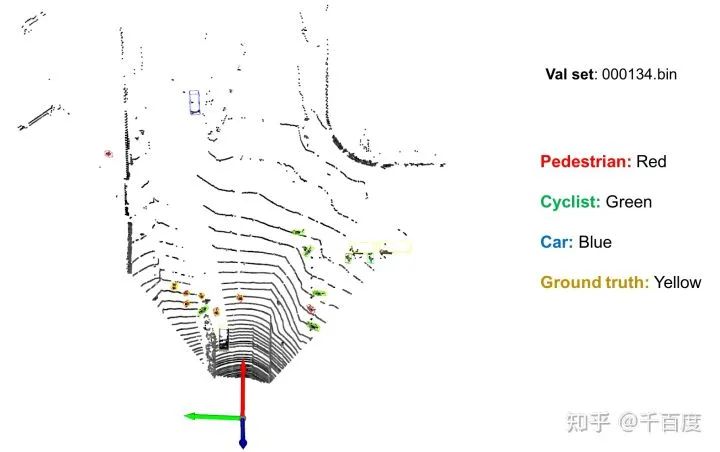

四、模型评估
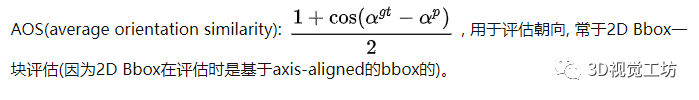
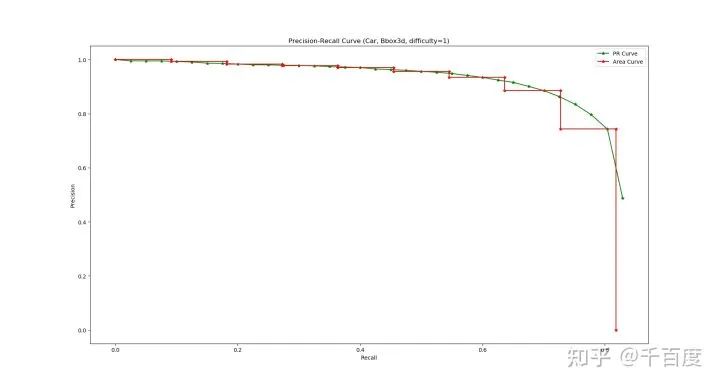
pre_process_kitti.py#L16-32。类别=Car, difficulty=1 AP的计算。注意, difficulty=1的数据实际上是指difficulty<=1的数据; 另外这里主要介绍大致步骤, 具体实现见evaluate.py。iou3d(bboxes1, bboxes2)), 用于判定一个det bbox是否和gt bbox匹配上 (IoU > 0.7)。类别=Car, difficulty=1选择gt bboxes和det bboxes。gt bboxes: 选择 类别=Car,difficulty<=1的bboxes;det bboxes: 选择 预测类别=Car的bboxes。

本文仅做学术分享,如有侵权,请联系删文。
评论