
iOS Crash防护你看这个就够了(上)
👇👇关注后回复 “进群” ,拉你进程序员交流群👇👇
转自:掘金 茉莉儿
https://juejin.cn/post/6959014275184590855
0x1 为什么要做Crash防护
在产品开发过程中Crash率是一个很重要的指标,也是一个团队中几乎所有的部门都应该关注或者去参与提升的一个指标,他不仅代表着整个产品的质量,也是一个团队整体技术能力的体现。更低的Crash率不但能让产品获得更好的用户口碑,在整个流程中也能让团队成员获得更多的成长,加深对iOS系统底层的理解,为今后的开发带了更大的帮助。

0x2 为什么要写这篇文章
起因也是因为自己的项目踩了FB的SDK的坑:2020.7.10,FB后台下发数据错误,导致大量使用FB SDK的App发生启动Crash,影响用户之多,范围之大,再加上当时包括我们的大部分App也缺乏相关的防护或者是容错处理,Crash率瞬间飙升,重新发版又要走发布流程,只能依赖FB后台的修复,当时束手无策十分被动,所以决定自己做一套较为完整的Crash防护体系,来避免这样的场景再次发生。第二个目的就是,发生问题后我也第一之间查阅了网上的一些资料和其他团队的做法,发现大家的方式各有千秋,方法不同,效果不同,所以我也决定把市面上能找到的好的思路和方法再结合自己的一些想法和经验记录下来。最后也是因为知识是要沉淀、积累和分享的,也算是巩固和加深自己的理解吧。
0x3 怎么做
其实当时Crash的场景很简单,本来一个Dictionary参数FB后台却下发了个String类型的数据,这样一来解析时候必然会Crash,解决的话其实只要做一层参数安全校验即可。
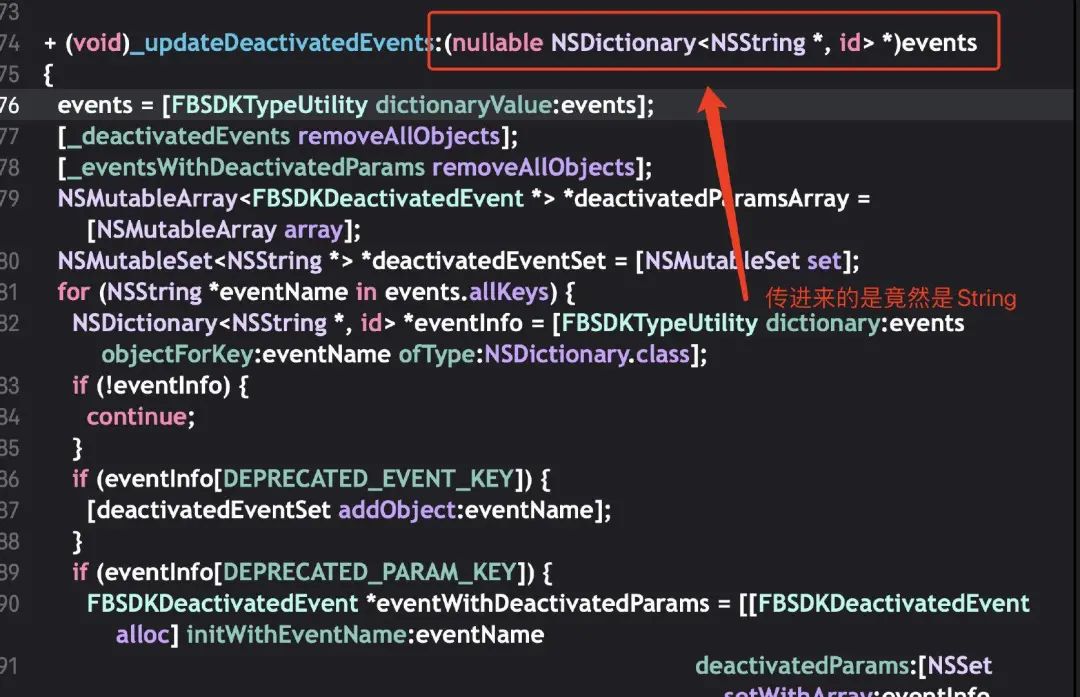

但是这么简单的问题,大部分App都没处理好,证明在流程上一定有大家注意不到的地方,暴露出来的只是冰山一角,我们机制一定存在着某种问题,或者存在可以优化的地方。
要想避免这种情况,就要先梳理出处理Crash的流程:
I:Crash处理流程

在iOS系统中基本可以总结出这四个步骤,
Crash防护 - 通过Hook等手段,对一些类似容器类进行入参校验等措施,来进来避免Crash的发生
Crash拦截 - 如果第一步防护失败,那么在Crash走到这一步就要进行拦截,要让我们发现异常
Crash上报 - 对防护的、捕获的Crash进行防护,生成有效的日志进行上报,尽可能的还原堆栈。
Crash后续流程 - Crash发生后如何做才能最大限度的保护用户体验,如何优雅的Crash
II:Crash防护
Crash防护方式主要分两种:针对非内存问题通常采用AOP方式,内存问题采用zombie对象的方式,


AOP:
iOS中AOP的相关知识网上线程的代码也很多,这里就不在赘述,但是在AOP这种频繁调用的场景中就需要注意的地方和坑点比较多。
AOP的影响范围问题:当时用了普通的方式对数组相关的方法进行了Hook,结果上线后发现大量的类似Crash。
[UIKeyboardLayoutStar release]: message sent to deallocated instance UIKeyboardLayoutStar

在通过一些其他场景可以判断出是因为HookNSMutableArr的相关方法,导致系统类的调用受到了影响。
通过Xcode调试发现,因为Hook的本质就是在原有的系统调用前插入一个用户自定义的函数进行方法交换,那么在某种极端情况下(比如多线程),传入该函数的变量被释放,这样一来再走到原本系统调用的时候正常释放时就会出现重复释放的情况。大概的流程为
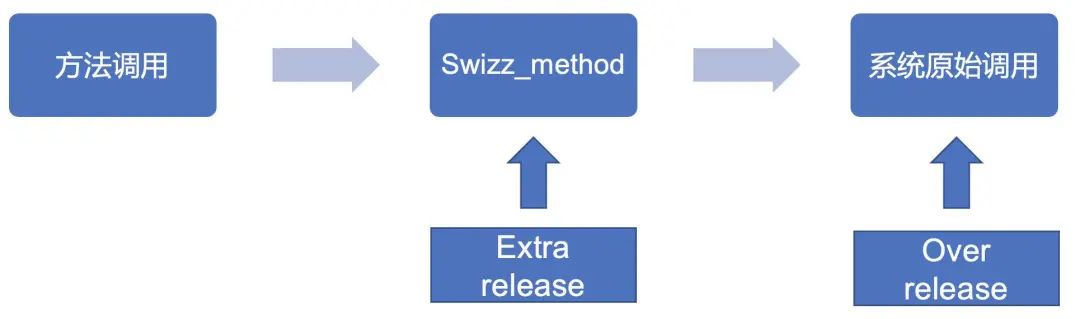
该场景在测试过程中很难复现,但是一旦到了线上,用户量覆盖够大后该问题就会显现出来。解决方式很简单,Hook尽量在MRC下进行,使用autorelease pool进行包装。保证内部变量在当前的runloop结束时候进行释放。
AOP的性能问题:上面说了AOP的原理是会多一层方法调用,那么再结合iOS的方法转发流程可想而知,AOP必定会造成性能的损耗,而且在Crash防护场景下频繁调用,性能问题一定不能忽略。
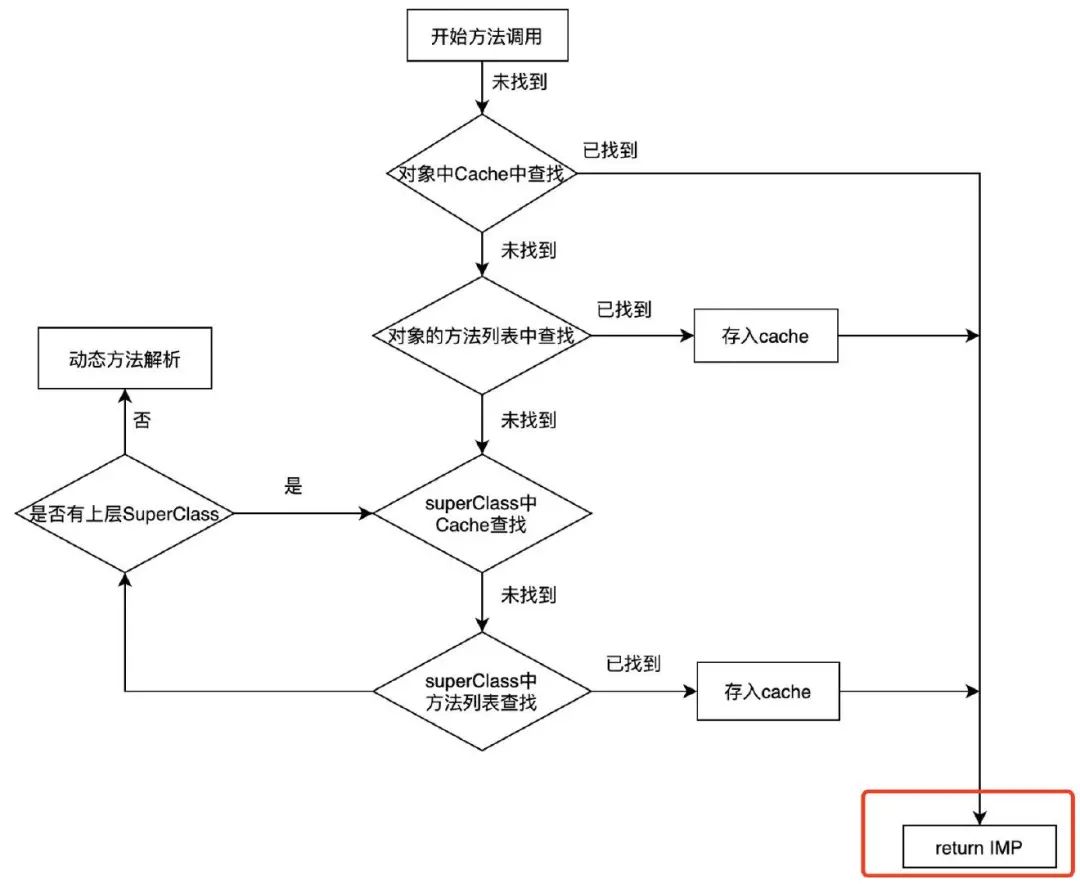
通过上图看出,方法调用流程最终会返回出对应的IMP指针供外部调用,作为动态语言,OC无法确定开发者会再什么时候插入或者交换哪个函数,所以必须通过这一套流程进行类似校验的逻辑。
使用过AOP的同学一定知道在AOP前会先做一层校验
+(void)hookClass:(Class)classObject isClassMetohd:(BOOL)classMethod fromSelector:(SEL)fromSelector toSelector:(SEL)toSelector
{
Class class = classObject;
Method fromMethod = class_getInstanceMethod(class, fromSelector);
Method toMethod = class_getInstanceMethod(class, toSelector);
// 添加前进行检测
if (classMethod) {
class = object_getClass(classObject);
fromMethod = class_getClassMethod(class, fromSelector);
toMethod = class_getClassMethod(class, toSelector);
}
if(class_addMethod(class, fromSelector, method_getImplementation(toMethod), method_getTypeEncoding(toMethod))) {
class_replaceMethod(class, toSelector, method_getImplementation(fromMethod), method_getTypeEncoding(fromMethod));
} else {
method_exchangeImplementations(fromMethod, toMethod);
}
}
所以在方法我们在上面代码中的toSelector中 当我们需要调用回原方法时直接调用对应的函数指针即可

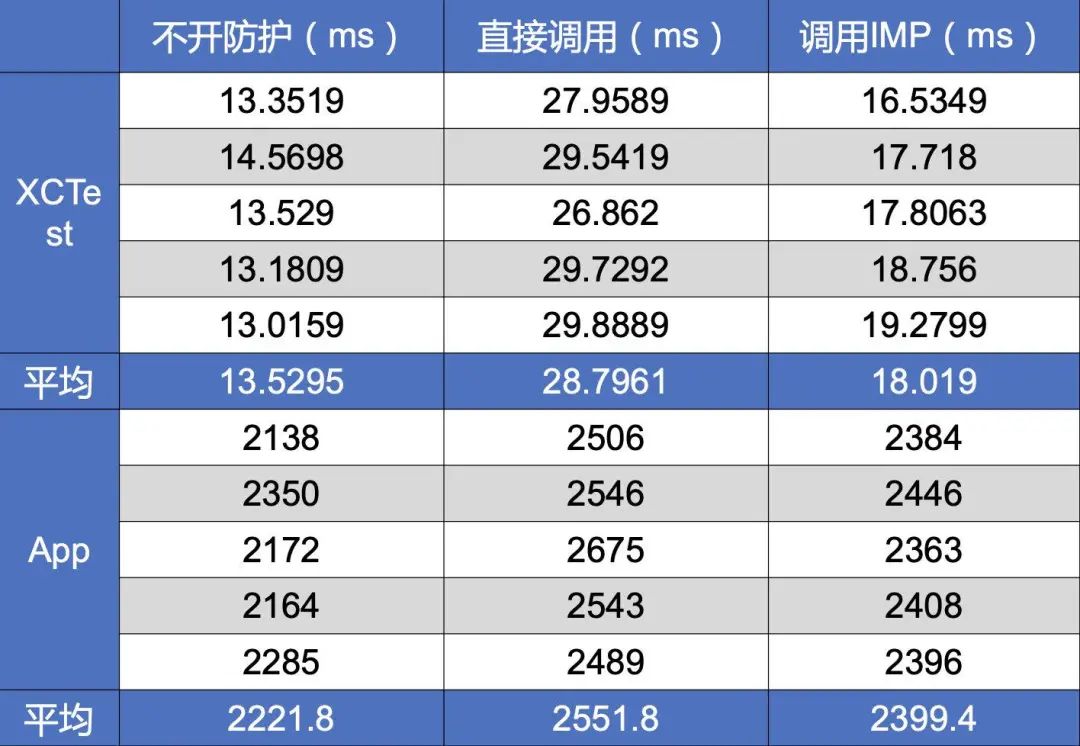
最终我对直接调用IMP的方法做了测试,分别是Demo中和App中的某一个场景,测试数据如下,对比结果还是较为明显。这也就是为什么Swift或者一些其他静态语言比OC快的原因。
Zombie:
使用僵尸对象来解决内存问题一直是苹果主推的方式,Xcode也有相关设置,在Debug下打开相应开关,但是一旦把该功能放到线上做防护或监控就要考虑很多的问题。
zombie入口问题:换句话说就是在哪个地方生成zombie对象,看了一些相关的SDK都是采用Dealloc作为入口函数,不是不行,只是不是最优。原因有两点:
综上两点我最终选择在Free函数中生成僵尸对象

1:苹果已经不建议在ARC下主动调用dealloc,目前只能采用performSelector或者其他动态调用的方式。
2:容易漏掉
Objc_destructInstance,所有的成员变量、属性都会在这个函数中释放,如果漏掉这个函数就会生成一个并不干净的僵尸对象,内存占用过高,白白浪费内存空间。
zombie内存阈值问题:僵尸对象会占用内存空间,然而在线上环境操作内存一定要小心且一定要有一套完整的逻辑,当超过某一个内存阈值后需要及时清空僵尸对象。内存阈值的确定便成了关键,这里会遇到两个问题:
我们的底线是在加入zombie后不能触发memorywarning,所以我先对大部分机型做了memorywarning阈值测试:
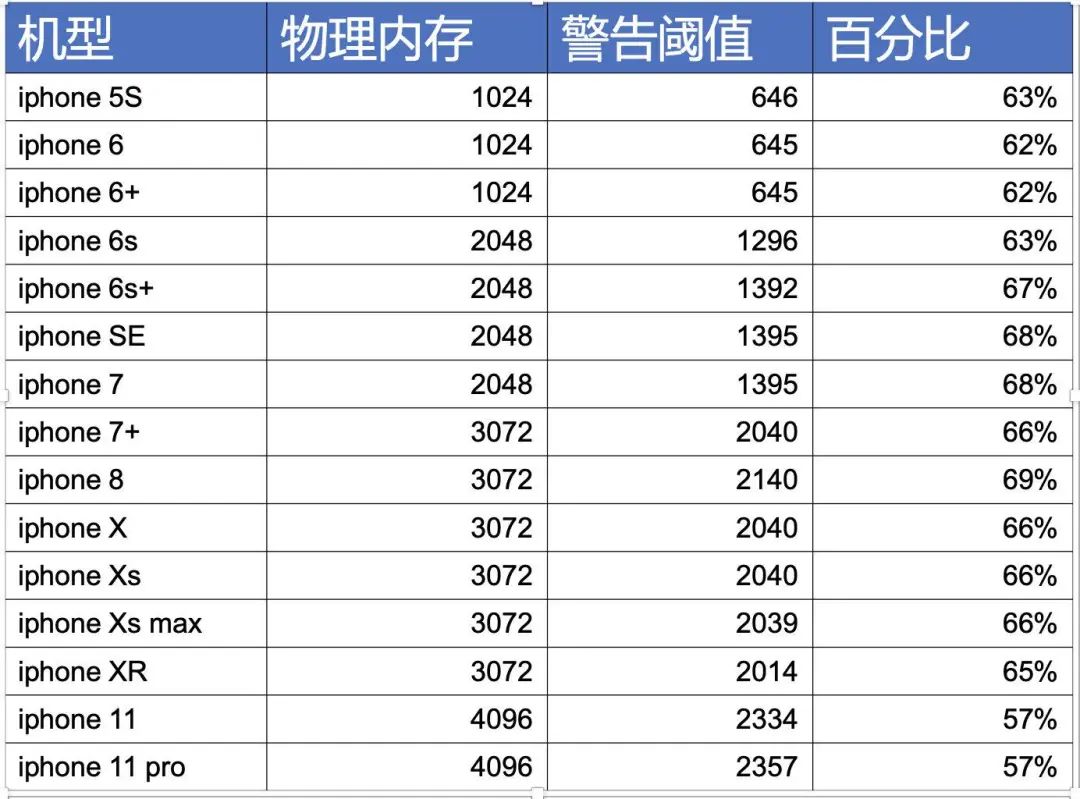
从上图可以看出当App占用内存达到总内存的 57%~69%时候会触发内存警告,而且由于iphone中有一部分内存是系统保留内存并不会给到开发者,所以我们可用的也就50%左右,我总结出如下公式:
公式1:不能触发内存警告
Y = 0.5 * deviceMem – currentAppMem
公式2: 僵尸对象的内存占用再大也不会超过App本身的内存
Y = min ( ( 0.5 * deviceMem – currentAppMem ) , currentAppMem)
上面两个公式看似完美,但是还是有优化的地方,因为并不是APP中所有的变量都有可能成为僵尸对象,可能只是其中的某一部分需要被监控, 所以得到最终的内存阈值计算公式:
Y = min ( ( 0.5 * deviceMem – currentAppMem ) , currentAppMem / N )
因为app占用内存随时在变,所以可以加一个定时器每隔一定时间去更新该值。
上面公式的 N 还有一个好处就是我们可以后台动态下发,根据线上内存引起Crash量,如果Crash量大,那可能就需要更大的内存阈值去保存僵尸对象,就可以把N调小,反正调大,这样就可以无视机型的差异根据Crash的情况进行远程配置。
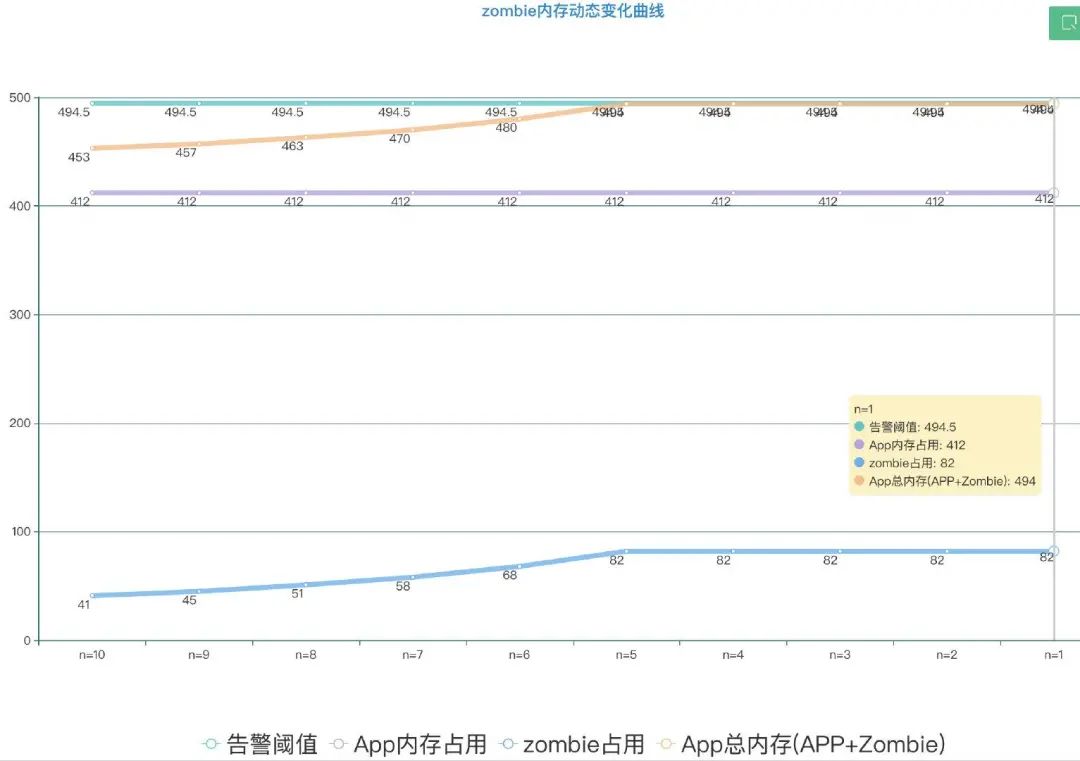
通过如图的线上数据可以看出 随着N的减小,zombie的内存阈值在增加,但是并不会超过内存警告阈值,确保了内存健康。
下图表示了不同的N值对应不同的捕获野指针问题的数量,各自App可以根据自己的业务情况进行调整。
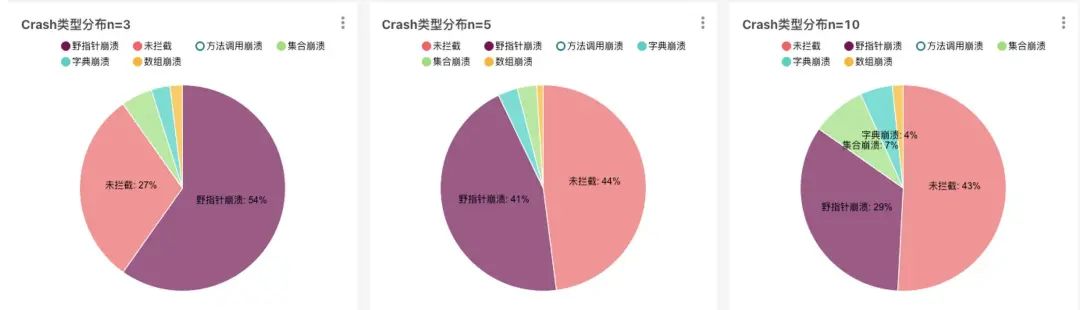
1:内存问题一定会和机型强相关,如何根据不同的机型调整不同的阈值?
2:如何做到根据线上情况灵活动态调整?
zombie更新策略问题:目前大家的做法都是在加入新的zombie对象时候检查是否超过阈值,达到阈值后删掉之前的zombie对象再加入新的对象,这样的清理逻辑是依赖于新zombie对象的加入,如果没有新对象的加入那么缓存空间也不会有变化,zombie空间一旦生成就无法删掉,无法做到缓存的自清理,等于App无故增大了内存占用。
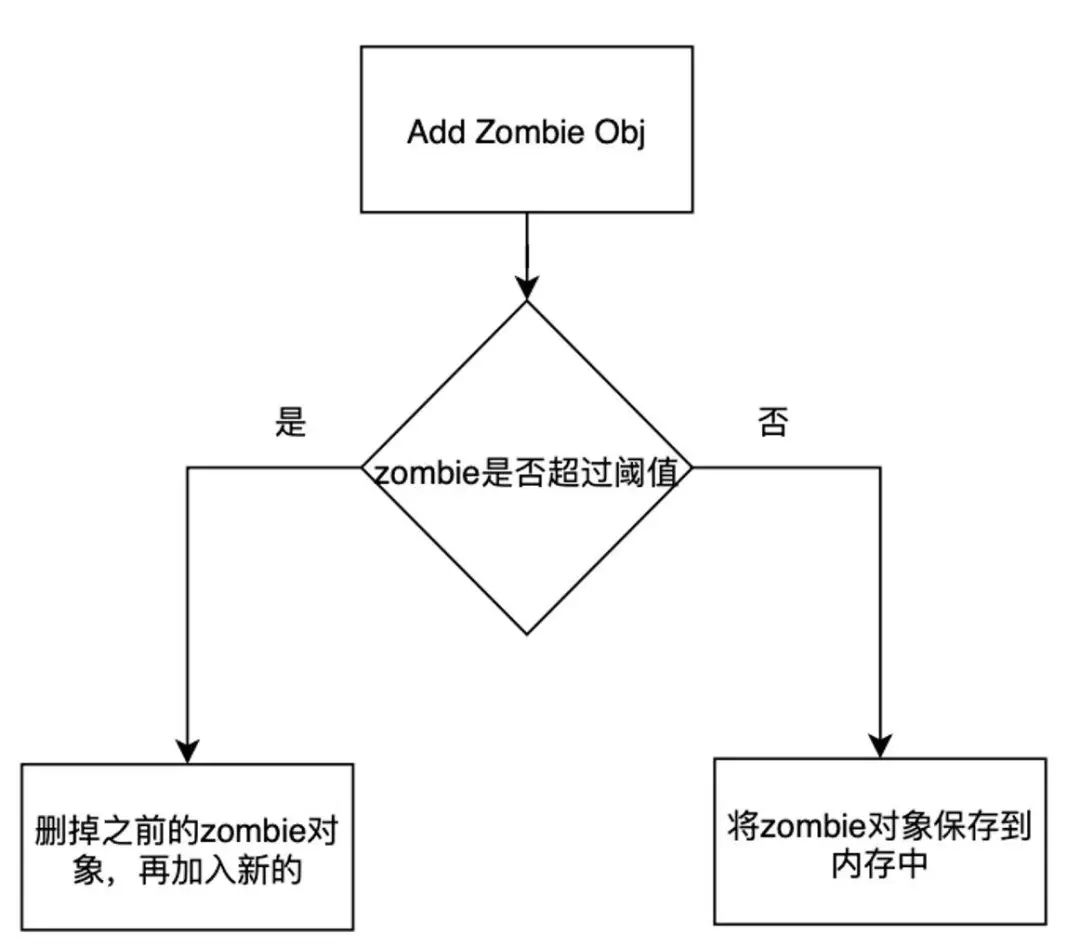
同样借鉴LRU最近最久未使用的逻辑,每隔30s会检测下缓存情况,超过30s还未被使用的zombie对象将被删除,30s是一个经验值,通过大量测试发现,内存问题一般会发生在对象被销毁的30s内,超过30s再出现的概率及小。这样可以做到缓存自清理的逻辑。
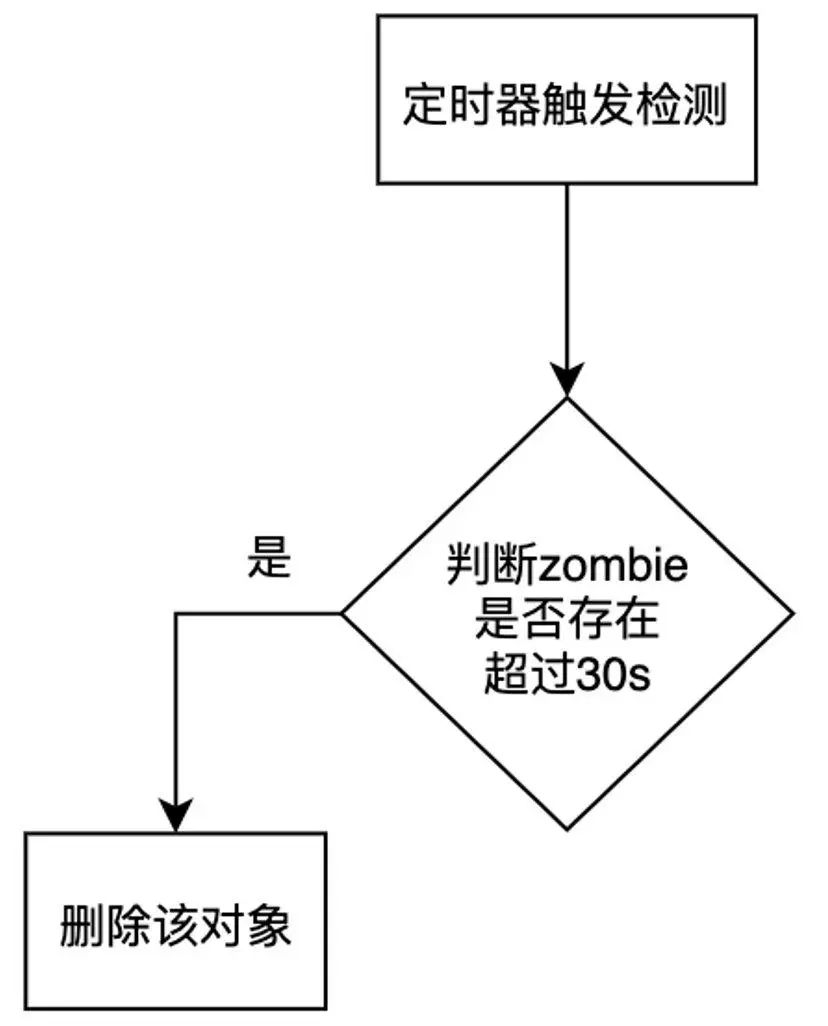
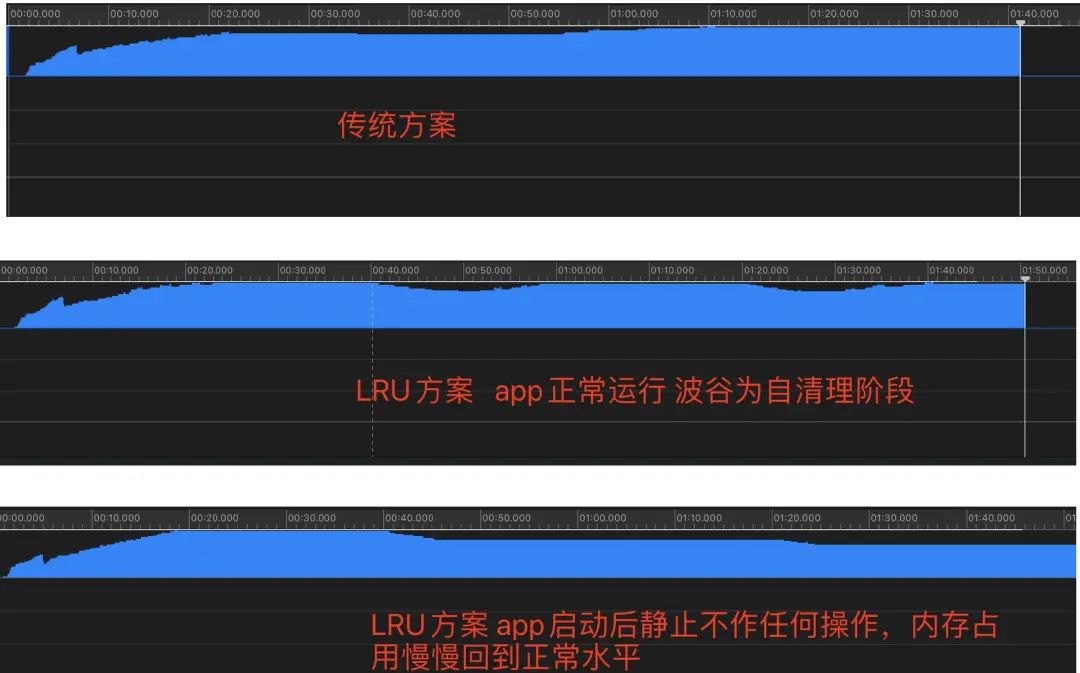
通过Instrument测试发现该zombie逻辑并不会对App本身的内存造成太大的影响。
转自:掘金 茉莉儿
https://juejin.cn/post/6959014275184590855
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击👆卡片,关注后回复【
面试题】即可获取