
计算机视觉与机器学习等领域不平衡数据处理综述
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
目录
机器学习——不平衡数据(上采样和下采样) 计算机视觉——不平衡数据(图像数据增强) NLP——不平衡数据(Google交易和分类权重)
1. 机器学习——不平衡数据
https://datahack.analyticsvidhya.com/contest/practice-problem-loan-prediction-iii/
https://github.com/NandhiniN85/Class-Imbalancing
#import imblearn library
from imblearn.over_sampling import SMOTENC
oversample = SMOTENC(categorical_features=[0,1,2,3,4,9,10], random_state = 100)
X, y = oversample.fit_resample(X, y)
from sklearn.utils import resample
maxcount = 332
train_nonnull_resampled = train_nonnull[0:0]
for grp in train_nonnull['Loan_Status'].unique():
GrpDF = train_nonnull[train_nonnull['Loan_Status'] == grp]
resampled = resample(GrpDF, replace=True, n_samples=int(maxcount), random_state=123)
train_nonnull_resampled = train_nonnull_resampled.append(resampled)
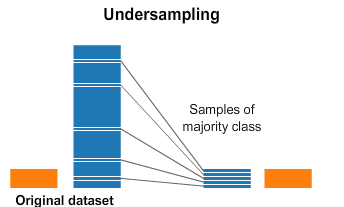
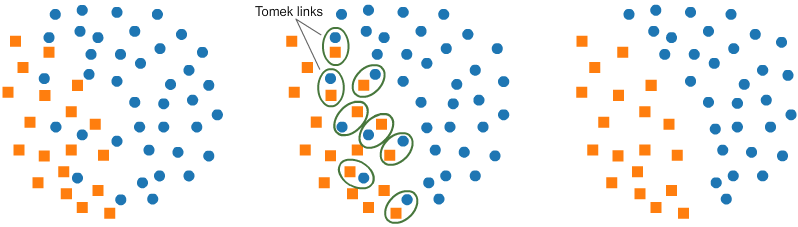
from imblearn.under_sampling import TomekLinks
undersample = TomekLinks()
X, y = undersample.fit_resample(X, y)
2. 计算机视觉——不平衡数据
https://datahack.analyticsvidhya.com/contest/janatahack-computer-vision-hackathon/#ProblemStatement

from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
img = load_img('images/0.jpg')
x = img_to_array(img)
x = x.reshape((1,) + x.shape)
print(x.shape)
# the .flow() command below generates batches of randomly transformed images
# and saves the results to the `preview/` directory
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='preview', save_prefix='vehichle', save_format='jpeg'):
i += 1
if i > 19:
break # otherwise the generator would loop indefinitely
https://github.com/NandhiniN85/Class-Imbalancing/blob/main/Computer%20Vision%20-%20Data%20Imbalanced.ipynb
https://keras.io/api/preprocessing/image/
3. NLP——不平衡数据
https://github.com/NandhiniN85/Class-Imbalancing/blob/main/NLP%20-%20Class%20Imbalanced.ipynb
from googletrans import Translatortranslator = Translator()
def German_translation(x): print(x) german_translation = translator.translate(x, dest='de') return german_translation.text
def English_translation(x): print(x)
english_translation = translator.translate(x, dest='en') return english_translation.text
x = German_translation("warning for using windows disk space")
English_translation(x)
import numpy as np
from tensorflow import keras
from sklearn.utils.class_weight import compute_class_weight
y_integers = np.argmax(raw_y_train, axis=1)
class_weights = compute_class_weight('balanced', np.unique(y_integers), y_integers)
d_class_weights = dict(enumerate(class_weights))
history = model.fit(input_final, raw_y_train, batch_size=32, class_weight = d_class_weights, epochs=8,callbacks=[checkpoint,reduceLoss],validation_data =(val_final, raw_y_val), verbose=1)
# fit the training dataset on the classifier
SVM = svm.SVC(C=1.0, kernel='linear', degree=3, gamma='auto', class_weight='balanced', random_state=100)
https://github.com/NandhiniN85/Class-Imbalancing/blob/main/English_raw200_model_execution.ipynb
结论
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看
评论