
比起35岁程序员,无知犯错的年轻一代是否更应该被原谅?
程序员犯了一个无知的错误,应该被原谅吗?近期,这个话题被广泛讨论。而引起这个话题的原因便是 PlanetScale 犯的一个“小错误”。
1 学会数据库索引技术原理,需要花费 5000 美元
软件工程师 Brian Anglin 所在的团队计划在 Superwall 开发一个 SDK,其中的一项工作是需要跟踪客户所有的服务对象,即最终用户。团队预先估算了数据量:假设与 5 家公司合作,每家公司的日均下载量约为 5000 次,那么单日下载量就在 25000 次左右,单月之内用户数量为 75 万。
Anglin 所在公司使用的是便是 PlanetScale 的无服务器数据库产品。他们为用户分配了一个随机 ID,为了可以在明确用户身份之前就开始进行跟踪,Anglin 团队设置了两个表:ApplicationUser 与 ApplicationUserAlias,其中 ApplicationUserAlias 与 ApplicationUser 属于多对一的关系。
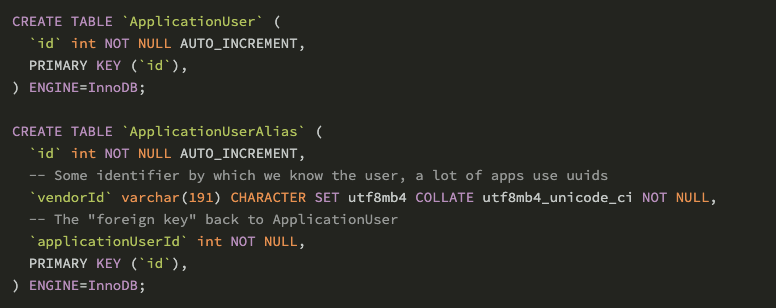
但有个问题是,PlantScale 的 Vitess 不支持 foreign key,这导致了系统无法自动创建索引。为了查找用户的所有别名,Anglin 团队运行了以下查询:

如果仅通过 applicationUserId 查找,操作成本是极低的。但是,PlanetScale 的计费模式以“读取的行”为基础,而 Anglin 将其理解为“返回的行”,他认为最多只会返回 100 个 ApplicationUserAlias 行,按每读取 1000 万行收费 1.5 美元来算,100 行的成本基本可以忽略不计。
但实际上,PlanetScale 对“读取行”的定义是“在查询或对您的 PlanetScale 数据库进行任何类型的突变期间,检索或检查的行数。”这里的关键词是“检查”。团队查找 100 个别名的简单查询实际上是检查了整个 users 表,而这个表在服务上线短短一个月内就已经超过了 100 万行。这不仅使查询速度变慢,更重要的是每一项执行此查询的请求都会花掉 0.15 美元。
“从统计数据来看,我们每小时大约会向端点发出 280 项请求,折合每天 1000 美元左右,跟 PlanetScale 提供的计费结果基本匹配。”Anglin 表示。
解决办法也不复杂,只要手动创建原本由 MySQL 自动创建的索引就可以了。但工作人员并没有意识到问题,直至“天价账单”的出现。

2 “无知”程序员写出的可怕 schema
如今,PlanetScale 目前已经修正了这个问题,Anglin 团队的月度查询成本又回归了较为合理的 150 美元/月水平。但这件事已经在不少论坛上引发了热议,尤其是扩展到了对基础能力不够的初级程序员身上。
“我觉得索引是一个非常基本的数据库知识,这也应该是你该具备的常识。此外,知道 ForeignKeys 通常将索引应用于列也是我的基本认识。对你的遭遇感到抱歉,但也恭喜你学到了一课,其实你可以通过谷歌搜索 MySql ForeignKeys 获得这些的知识,并为自己省去这些麻烦。”有网友说道。
程序员“rachelbythebay”也专门撰写了一篇文章来指责一些无知的程序员。
“这是个人人能写文章、能表达自己观点的时代。哪怕我们的水平再差,提出的是一套缓慢、臃肿、任何有经验的人一看就知道完全荒谬的 SQL 数据库使用方案,恐怕也会有人直接照搬,同时还庆幸自己省掉了不少麻烦事。”rachelbythebay 表示。如果是那个程序员把大量原始字符串(也就是 varchar)塞进 schema,而且还对 foreign key 关系毫无概念,问题最终会恶化到何种地步?
rachelbythebay 用自己的亲身经历表明了无知会对系统造成多大的损害。
2002 年时,“rachelbythebay”所在公司为了减缓和阻断众多垃圾邮件的传播速度设计了一套系统。虽然团队可以能拿到开放代理主机的列表,但正常发送邮件的合法组织也被莫名其妙地添加进了黑名单。
经过排查发现,原来每行都包含有原始字符串,所以数据库的匹配检查负担特别重。旧系统将 IP 地址、HELP 字符串、FROM 地址以及 TO 地址整合在单一表内,并在第一次收到特定元组(「四元组」)时返回 4xx“临时故障”错误。能够正确执行 SMTP 的真实邮件服务器会在稍后重试,一般间隔是 15 分钟到 1 个小时之间。如果对方确实重试而且间隔时间合理,那么下一次就会被允许通过。
虽然听起来可行,但这背后还隐藏了一个很大的问题。团队用的是纯标准版 MySQL,所以这份表中的各行的显示形式如下:
id | ip | helo | m_from | m_to | time | ...
这些内容都是字符串(也就是数据库中的 varchar),所以这个四元组表中的每一行都如下所示:
1 | ip1 | blahblah | evil@spammer.somewhere | victim1@our.domain | ...
2 | ip2 | foobar | another@evil.spammer | victim2@our.domain | ...
3 | ip3 | MAILSERV | legit@person | user@our.domain | ...
4 | ip4 | foobar | another@evil.spammer | victim1@our.domain | ...
所以,整个匹配过程相当于:
SELECT whatever FROM quads WHERE ip='ip1' AND HELO='thing_they_sent_us' AND m_from='whatever' AND m_to='some_user'
这个恐怖的数据库 schema 一旦开始运行,就会不断对表中各行执行字符串比较。它需要读取表中的各个行,再将查询中的字符与当前行内找到的字符进行比较。虽然只要某列不匹配就会被中止,但整个过程仍然缓慢、令人头痛。
“当初负责设计和编程的家伙把活儿搞砸了,而且问题一直持续了几个月。最终我不得不翻查日志记录,看看系统到底是怎么熬过那段时光的。”rachelbythebay 写道。
rachelbythebay 感叹道,每个人都要经历青涩的阶段,迫切需要他人给予引导、说明或者参考。但这与残酷的现实形成了鲜明的对比:一边是刚过 35 岁就丢掉工作、不知道接下来该干什么的老鸟,另一边则是无知无畏、什么都敢往 schema 里塞的新人……这个世界到底怎么了?
3 初级程序员应该被指责吗?
rachelbythebay 表达了初级程序员莽撞无知的指责,但在他的帖子下边,很多人表达了反对。
“即使是具有 Rachel 经验水平的人仍然不了解数据库优化的所有细节,初级程序员需要被更有经验的工程师指导,而非被一味批评。”有网友说道。
有一句话在开发人员圈子广为流传:“初级开发人员的标志就是需要在中级和高级开发人员的指导下完成工作。”每个开发人员都是从初级到中级、再到高级的一个过程,但在很多资深开发者眼里,高级开发人员是各项能力的综合体现,而非仅仅写代码的能力。
有开发者指出,编写优秀软件的挑战不是要做到每个细节的完美,而是培养判断力并专注在真正重要的细节上。对初级程序员的不屑一顾和傲慢会让他们害怕犯错,进而使他们的发展停滞不前。
印度 IT 项目经理 Ravi Shankar Rajan 认为,高级开发人员所为人称道的是专业性,而不是具备多少年经验,也不是从来不犯错。从初级程序员到高级开发人员,需要培养各种技能,单纯的经验积累也不意味着会成为高级开发人员。
Rajan 给初级程序员提出了以下三个建议:
克服邓宁 - 克鲁格效应,即不要高估自己。初级程序员和高级程序员的区别在于初级程序员认为自己什么都懂,而高级程序员则知道自己还有很多东西要学。 优秀的高级程序员清楚地知道什么时候不应该做什么。关键不在于规避风险,而在于谨慎选择正确的战场。 抱有疯狂的好奇心。好奇心是一种可以越用就会变得越好的工具,这也是人们对优秀高级程序员的期望。
在很多人看来,初级、高级程序员是一个年龄划分,但实际上,更多的是对能力的划分。“学会学习”和“尊重以前的东西”是与开发一样重要的技能。
相关链接:
https://briananglin.me/posts/spending-5k-to-learn-how-database-indexes-work/
http://rachelbythebay.com/w/2021/11/06/sql/

疯了!成千上万网友正利用共享文档相亲!(附文档地址)

HTTP请求合并之后是不是会非常快?