众所周知,深度学习框架 PyTorch 的前身是 Torch,从 Torch 发展到 PyTorch,创建团队都做了哪些努力,又遇到了哪些挑战呢?在近日结束的 JuliaCon 2021 活动中,PyTorch 创始人 Soumith Chintala 做了 Keynote 演讲,分享了一路走来的成长历程和经验教训。

PyTorch 是深度学习领域最受欢迎的框架之一,初始版本于 2016 年 9 月由 Adam Paszke、Sam Gross、Soumith Chintala 等人创建,并于 2017 年在 GitHub 上开源。PyTorch 很简洁、易于使用、支持动态计算图而且内存使用很高效,因此越来越受开发者的喜爱。7 月 28 日 - 30 日,JuliaCon 2021 线上活动顺利召开。在 7 月 30 日的 Single Track 活动环节,活动主办方邀请到了 FAIR 研究工程师、深度学习框架 PyTorch 创建者之一 Soumith Chintala。目前,他的研究兴趣集中于计算机视觉、机器人和机器学习系统。在他的 Keynote 演讲中,Soumith Chintala 回顾了自己从 Torch 发展至 PyTorch 的心路历程,以及对开源社区的看法。他从以下几个方面进行了阐述:
在正式进入到演讲主题之前,Soumith Chintala 阐述了他对开源项目的看法,表示大多数开源项目并不仅仅是从「我们需要拥有 1 万名用户」这种预期开始的。这种预期没有意义,开源之旅应该更纯粹并充满活力。在开源领域,我们一开始是基于个人兴趣来做事情的。通常来讲,只有当很多人都对某些想法和项目感兴趣并愿意付出时间时,它们才会自然地成长。此外,就开源项目的发展规律而言,大多数小型开源项目在经过足够的努力和参与后,都会考虑发展壮大。那时,项目参与者已经确定了他们的核心兴趣和理念,这也是技术和文化堆栈的基础。接下来,他们就会竭尽所能营销并扩展自己的开源项目。从 Torch 到 PyTorch 也遵循这一发展规律。当考虑一个项目时,它可能是以技术为中心的项目,比如对张量的理解,又比如以用户为中心(例如 Torch-7)的项目,它们传播的是易用性理念,而不关心什么技术或想法能让研究者更容易使用。我在 2010/2011 年开始与 Torch 合作,并在 Torch 社区交了许多朋友,理解了他们作为一个整体所代表的隐含原则,和政治一样,开源在关系和原则上的定义是相当模糊的。因此,多年来,我逐渐理解并欣赏到 Torch 是一款以用户为中心的产品,它具有即时模式、易于调试、不受影响等特性。Torch 的目标用户是一些熟悉编程的人,这些用户能够理解性能等问题,可以根据工作需要,他们能够编写一个 C 函数并快速地将其绑定进去。当我们编写 PyTorch 程序时,我意识到在一个有机的开源社区中,并不是每个人都支持相同的原则。我们在 Torch 社区中有一些非常重要的成员反对 Python,尽管我们以用户为中心的观点允许我们朝着这个方向前进。然后,我们必须做出决定是带他们一起发展还是把他们留下。这些都是困难的决定,因为没有正确的答案,只能领导者必须迅速做出的主观判断。在这种情况下应该思考什么时候保持固执,什么时候保持妥协。我的观点是,你必选在理念、原则上保持固执,但其他一切都是可以改变的。这一观点非常有用,随着时间的推移,PyTorch 带来并集成了 Caffe2 社区和 Chainer 社区,并与 Jax 和 Swift4TF 保持友好关系。PyTorch 社区变得越来越大,在这个社区中你可以得到更广阔的视角,随着时间的推移,这些视角会使项目变得越来越好。如果你坚持自己的核心原则,你就不会真的在你最初的愿景上妥协,只会让它变得更好。推动 Torch 社区发展是一个挑战,除此以外,面临的另一个挑战是 TensorFlow ,据了解 TensorFlow 拥有比 PyTorch 多 10 到 30 倍的开发人员。不过,TensorFlow 正在努力为所有人提供便利,这对 PyTorch 研究者来说是非常有益的。此外,TensorFlow 是一个自上而下计划的项目,需要大量的资源。所以,我们很自然地采取了完全相反的方法,主要是为了在现实的条件下生存和竞争。我们决定,除了 ML 研究人员,我们不关注任何人。这样,我们就可以集中精力,用更少的资源完成任务。我们有意缩小范围,因此承担了更多的垂直风险,但同时减少了水平风险。我们只是想确定我们的潜在市场。然而,一旦我们用 PyTorch 在该市场取得成功,我们的野心就变大了。随着我们的成长和成熟,我们渐进地扩大了范围和抱负,这接近于规模化。在这里,介绍一下需要承担的风险,以及它的影响。我们在 ML 研究市场上做了一个赌注:因此,有了这个赌注,我们需要一个非常广泛的 API 结合用户体验,以真正轻松地使用和扩展该 API。基于 ML 社区如何塑造它的未来,我们所做的这个赌注可能无法实现,原因有很多。在我的演讲中,你可以听到我对这个主题的更多看法,以及我对未来 ML 框架的看法。除了核心原则和范围外,我们还希望与客户建立反馈回路,这是产品开发的标准操作需求。然后,我们从不同维度对如何跟踪 PyTorch 进行了总结:它们是可度量的吗?
是否可以很好的进行度量?
你应该度量吗?
如何处理不可度量的区域?
在我们的 Torch 时代,我们学到了很多关于人们如何喜欢度量事物。例如微基准、GitHub star 量、特征对比表等。当人们在社区发布了一些这样的度量和比较之后,我们不赞同其中的一些测量。但是我们从 Torch 中得到经验是过早地度量会对产品造成负面影响。尽管我们并没有把度量 Torch 的博客文章写给竞争对手,但我们一直在努力优化这些度量结果,并对它们做出反应,而不是专注于其他更重要的用户优先事项。所以,当我们编写 PyTorch 时,需要明白两件事:第一,我们的核心竞争力不是像速度或其他数据那样可以度量的东西,而是我们需要向流畅的用户体验迈进,将灵活性、API 设计和可调试性作为首要任务;其次,我们相信,如果我们不对 PyTorch 的外部度量做出反应,我们就可以专注于我们所关心的东西,即使这会造成短期的变动。因此,在 PyTorch 的发展过程中,我们从未对速度基准或者 GitHub star 量等不相关的度量指标做出回应。作为 PyTorch 的创建者,我们从未提交至 MLPerf 等行业基准。这是经过深思熟虑的,我们对此做法感到满意。在做 PyTorch 相关的演讲时,常碰到有人问:「与 X 相比,PyTorch 的速度有多快?」即使我知道 PyTorch 在给定用例上能够达到相同甚至更快的速度,但我只会这样回答:「PyTorch 更灵活,试试吧。」这使得我们专注于自己的核心竞争力。我们勉强依赖的指标是开发者是否在使用 PyTorch 以及竞品框架的使用情况。我们倚重的指标不是 GitHub star 量或者微基准上的性能等,而是 PyTorch 实际编写代码的体验。所以,我们采用的度量指标有 GitHub 的全局代码搜索和 arXiv 引用等,这种做法更准确地获知开发者是否使用 PyTorch。我们勉强依赖的指标是开发者是否在使用 PyTorch 以及它与我们的竞争对手的相对使用。不是衡量书签(如 github 星)或微基准性能的指标——而是实际在其中编写代码。因此,我们使用了 Github 的全局代码搜索(用于导入 torch 和其他东西)和 arxiv 引用等指标,它们可以更准确地描述是否有人真正使用过我们,没有歧义。然而,问题在于这些是滞后的指标。我们根本不能依靠它们来了解社区的即时需求,因为交付周期很长,大约为 6 个月。我们也没有使用指标来尝试近似用户对其整体体验以及可调试性和 API 易用性等方面的感受,但确实从主观上衡量了这些方法…在较小的范围内,我所做的基本上是阅读社区产生的全部信息,比如 GitHub 问题、论坛帖子、slack 消息、twitter 帖子以及 reddit 和 hackernews 评论等。这些都是非常有用的信号,虽然也充斥着很多不和谐的声音,但也可以从中了解用户的一些想法。这些指标帮助我们很好地确定了优先级,并且我认为这是从主观层面塑造自身产品的好方法。除了我之外,几乎所有的核心开发者都花了很多时间与用户进行互动,因此我们从非常模糊和主观的视角达成了大量的共同理解。然而,这种方法并没有超出一个点。随着项目的扩展,我认为在 PyTorch 推出的两年时间里,自己每天的工作已经达到了人体极限。我要在 twitter、Reddit 和 Hacenews 上浏览 500 条左右的 GitHub 通知、50 篇左右的论坛帖子、大量的 slack 活动和很多其他的参与。我觉得自己每天工作 15 个小时,每时每刻都筋疲力尽,但实际上并没有做太多事情。因此,我想直接将这些繁琐的工作交给其他更尽力且做得更好的人,这样我就解脱了。之后,我的同事 Edward Yang 拥有我没有的超能力,他接管了整个工作流程,并打算先进行观察,然后再创建了一个更好的扩展流程。2021 年 1 月,他撰写了一篇精彩的博客文章《The PyTorch Ppen Source Process》。我从他做这些事情中学到了一点,即当你达到一定的规模,就无法顾全所有事情,必须有明确的优先级。博客地址:http://blog.ezyang.com/2021/01/pytorch-open-source-process/在项目规模上需要考虑的另外一件事情是进行垂直整合还是水平整合。在 PyTorch 项目上,我们集成了 distributed、jit 和 quantization 包,这些包需要更深的垂直集成,因为它们与前端设计具有很深的交集。我们还将 torchvision 或 torchserve 等包分支到了各自的 GitHub 库中,因为它们不需要很多的端到端思考。最后想谈一谈生态系统的问题。从 PyTorch 开始,我们希望开发者使用 PyTorch 并向该项目做出贡献,由此发展社区。在整个过程中,我们竭力避免任何形式的激励措施。因此,在很长一段时间里,我们没有提供任何奖品、奖金或其他经济奖励措施来鼓励研究者使用 PyTorch。我们的观点是,一旦引入经济激励措施,就会以一种不可逆转的方式塑造社区文化。截止 2020 年底,PyTorch 项目的贡献者大约 1626 人、下游项目 45k + 个,PyTorch 论坛用户达到了 34k。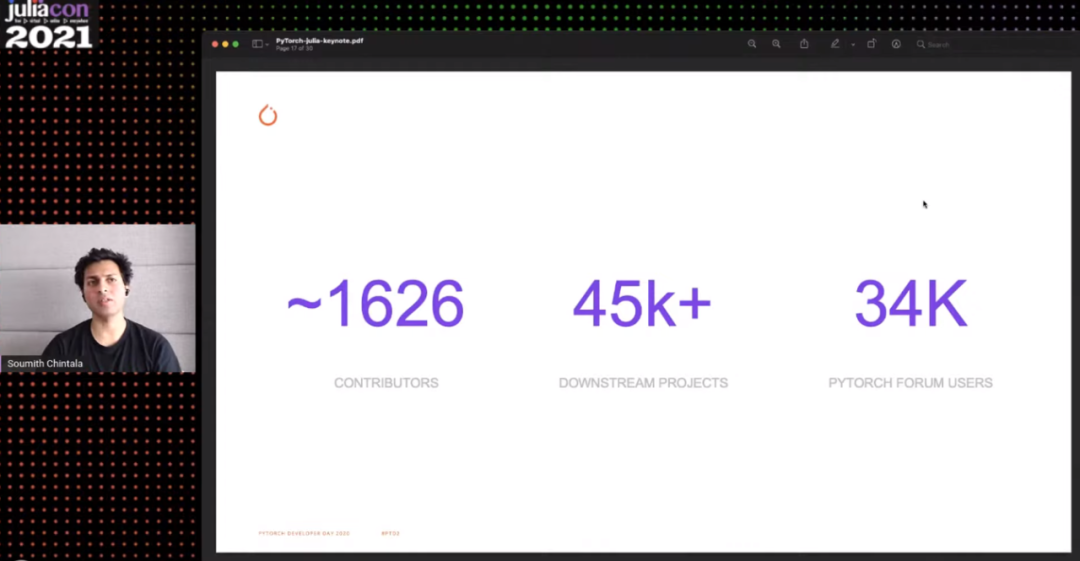
即使是现在,即使我们的项目有了更多预算,但是除了每年一两次的黑客马拉松比赛,我们并不会在这方面投入太多。我们非常关心的另一个激励因素是为其他人提供更大的发展空间,而不是自己包办一切。我们会着力帮助社区成长,并首先填补一些空白,只有当没人能够满足一些需求时,我们才会介入并自上而下投入时间和精力解决问题。https://soumith.ch/posts/2021/02/growing-opensource/往期精彩:
Swin-UNet:基于纯 Transformer 结构的语义分割网络
Swin Transformer:基于Shifted Windows的层次化视觉Transformer设计
TransUNet:基于 Transformer 和 CNN 的混合编码网络
SETR:基于视觉 Transformer 的语义分割模型
ViT:视觉Transformer backbone网络ViT论文与代码详解
【原创首发】机器学习公式推导与代码实现30讲.pdf
【原创首发】深度学习语义分割理论与实战指南.pdf
