PyTorch为何如此受欢迎?创始人Soumith亲述「成长秘籍」
点击左上方蓝字添加"星标",重磅干货,第一时间送达

转载自 | 机器之心

理念原则
范围 & 风险
度量指标
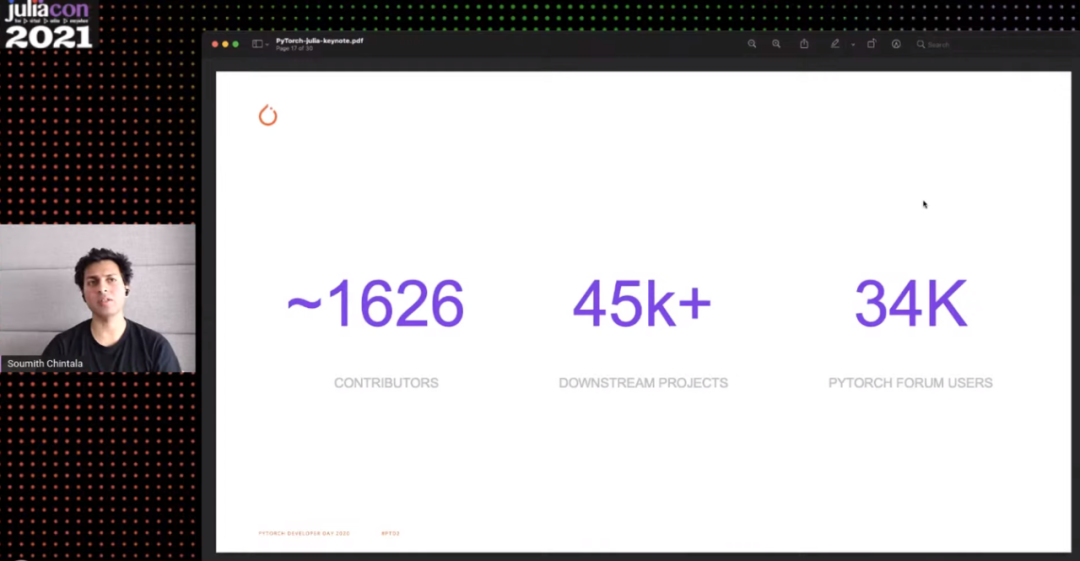
项目的扩展
他们在未来几年所做的建模将需要更多的灵活性和可调试性;
ML 研究市场将继续在更先进的模型架构上进行创新,它将成为未来的主流。
它们是可度量的吗?
是否可以很好的进行度量?
你应该度量吗?
如何处理不可度量的区域?
END
整理不易,点赞三连↓
评论
 下载APP
下载APP点击左上方蓝字添加"星标",重磅干货,第一时间送达
转载自 | 机器之心
理念原则
范围 & 风险
度量指标
项目的扩展
他们在未来几年所做的建模将需要更多的灵活性和可调试性;
ML 研究市场将继续在更先进的模型架构上进行创新,它将成为未来的主流。
它们是可度量的吗?
是否可以很好的进行度量?
你应该度量吗?
如何处理不可度量的区域?
END
整理不易,点赞三连↓