用Python绘制人口分布经纬网
共
946字,需浏览
2分钟
·
2022-06-01 17:06
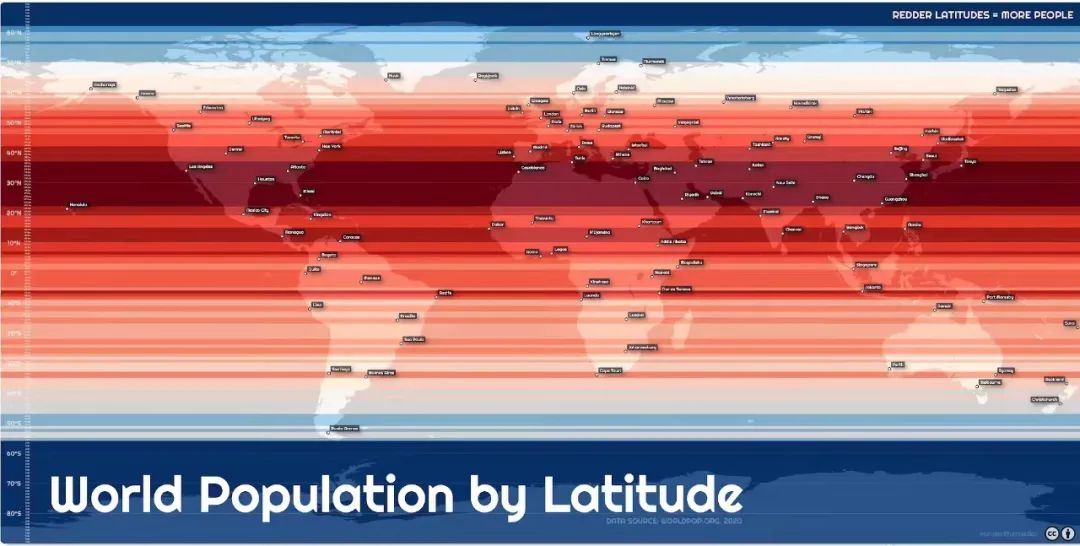
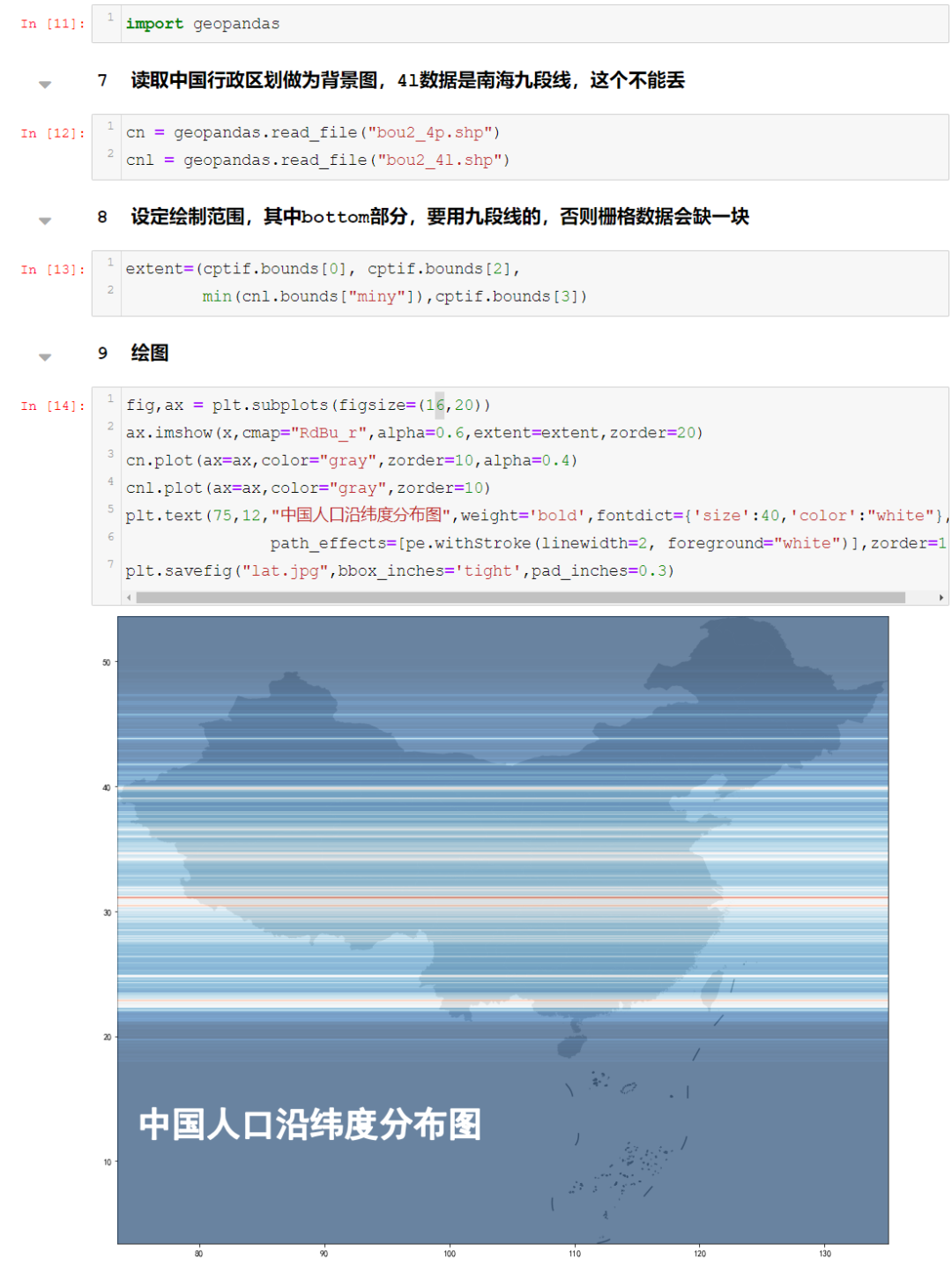
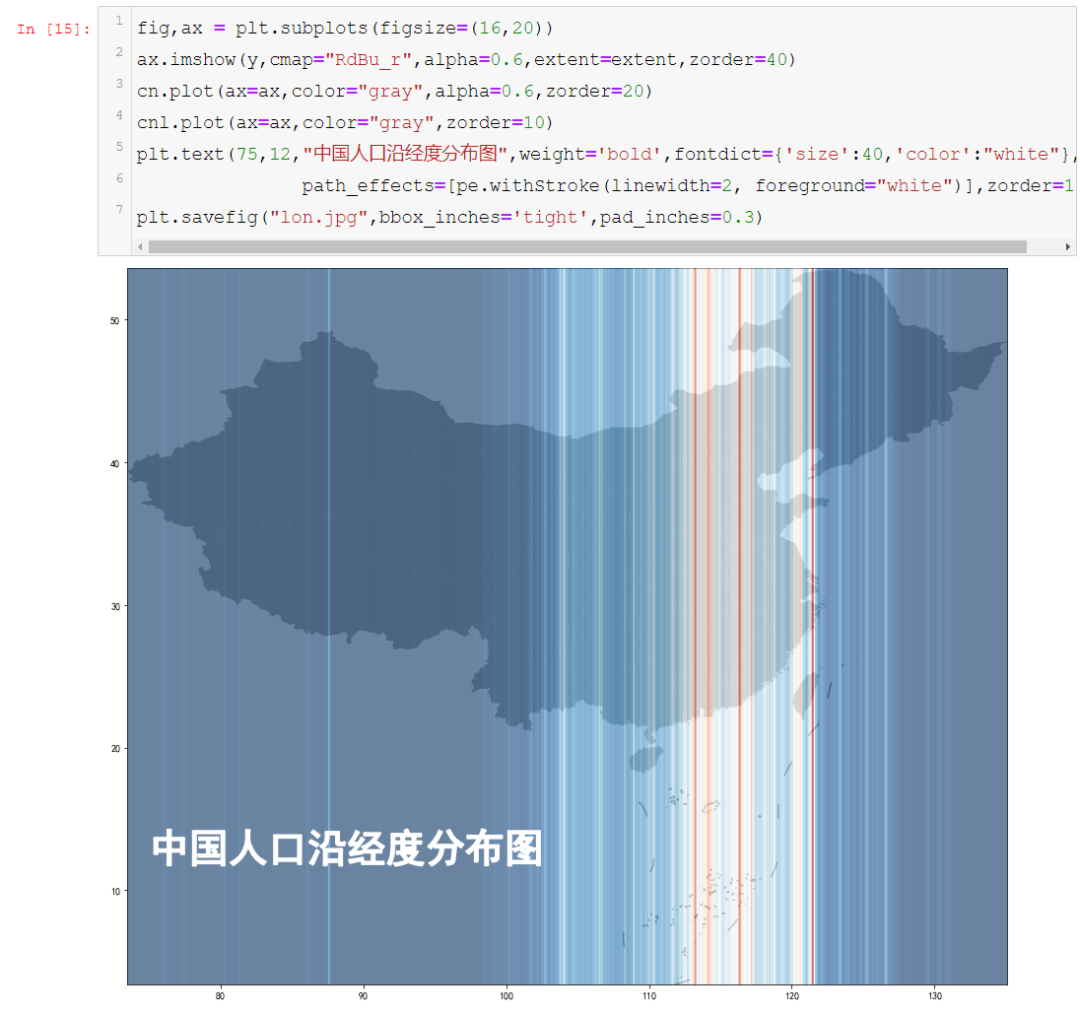
全球人口按纬度分布,很明显的可以看见北纬三十度附近,那是红彤彤的一片……看完之后,虾神突发奇想,就以中国而论是什么样子呢?如果按经度分布,又是什么样子呢?
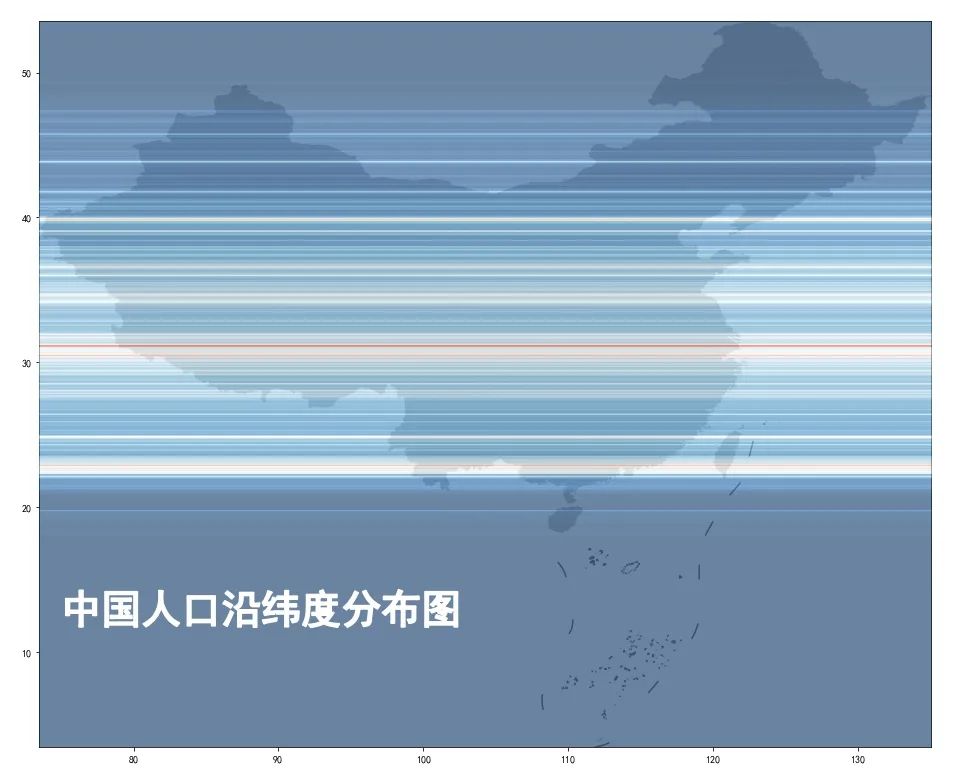
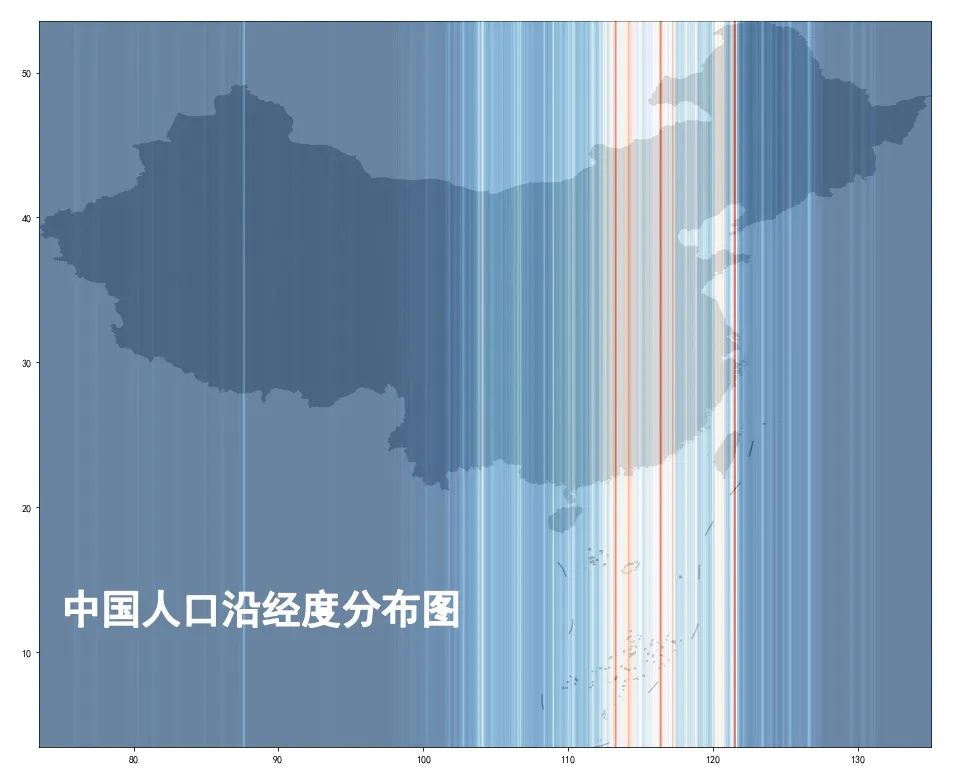
首先是数据:2020全球人口1平方公里的栅格数据,大家可以到下面去下载:https://www.worldpop.org/geodata/summary?id=24777
然后我在ArcGIS里面,截取了中国范围的数据,如下所示:可以看见,中国大部分地区还是无人区(平方公里小于50人),而1000人一下的区域,也占到绝大多数,密度比较高的几个地方,比如长三角、京津冀、珠三角: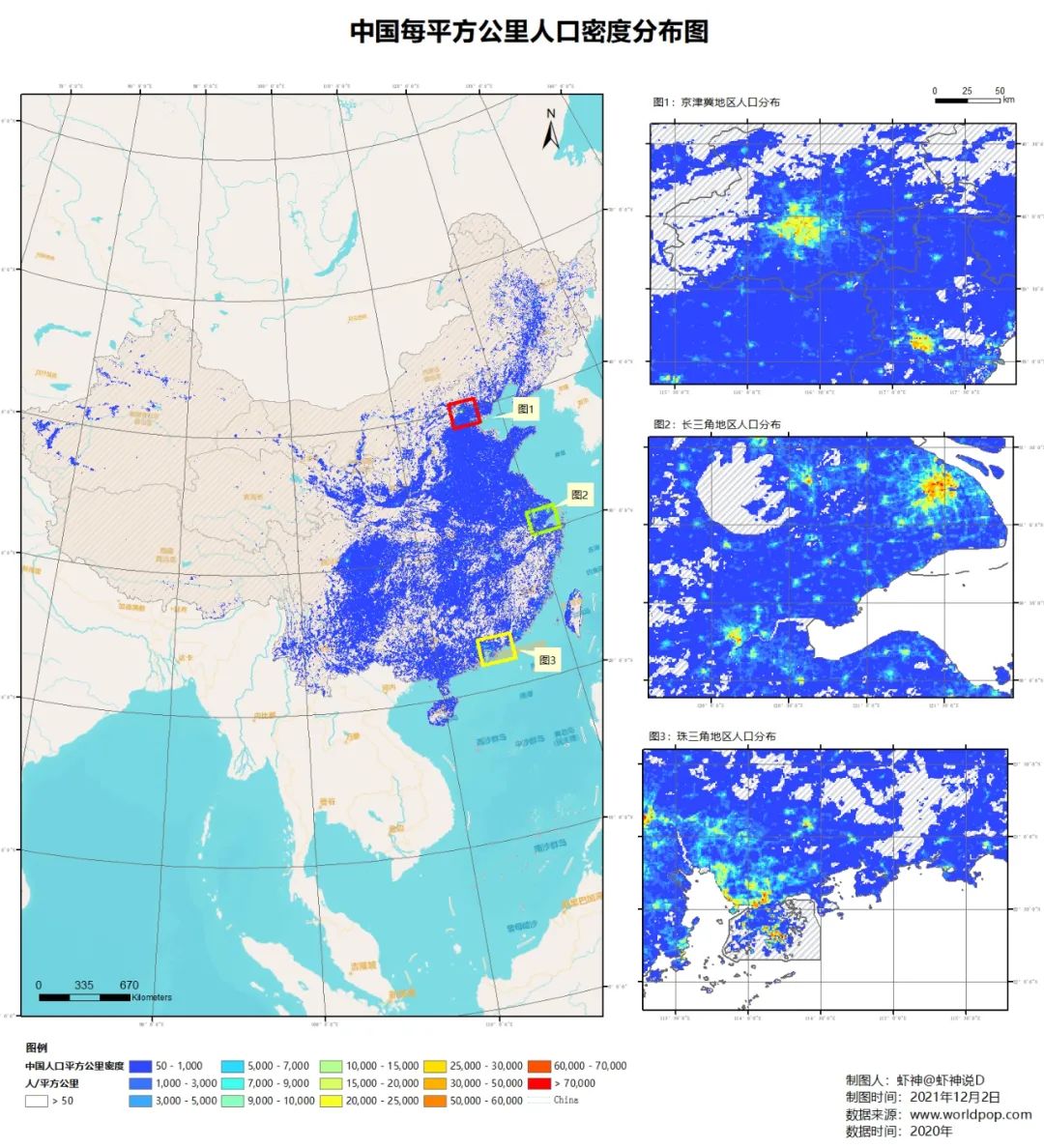
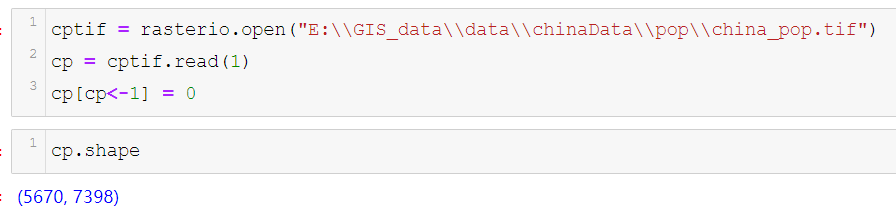
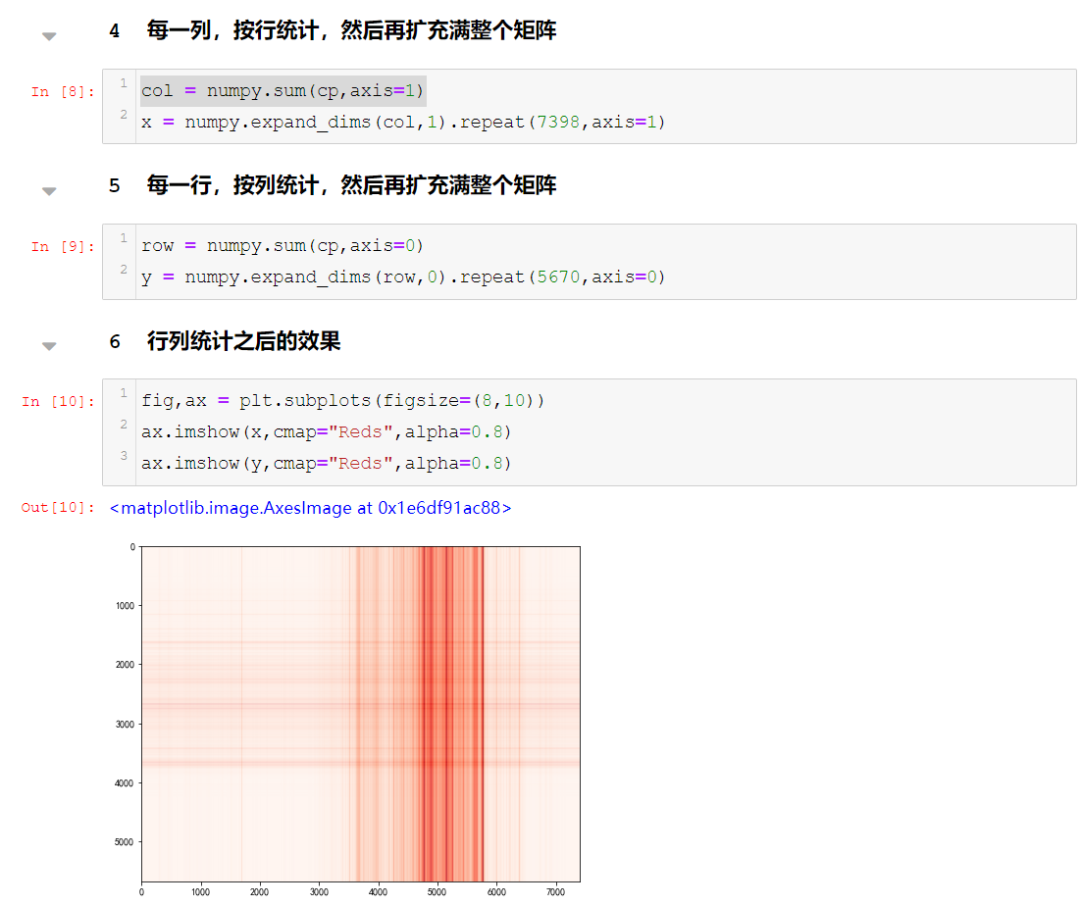
整个中国范围内的数据,一共是5670行,7398列。首先对数据进行统计,分布图的统计方式是以行列进行累加,然后用累加的值做为这个一行(列)的值,所以很简单的分行列累加就行。但是,如何去累加就需要说到说到了,一般来说,写习惯了传统算法的同学,想到的第一反应肯定按行列就行循环累加……
这样的迭代方式,把行统计完,需要7.5s……好吧,也不算太慢。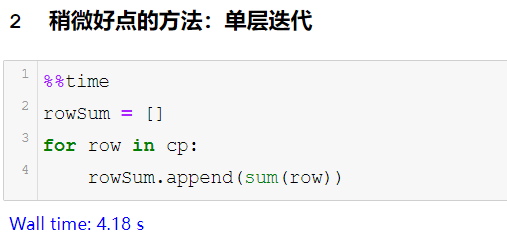
少一层迭代,取出每一行,然后用sum函数已处理,速度差不多提升了一倍。
直接用numpy的sum包,执行仅需要26.8毫秒。。。效率比最慢的方式,快接近300倍!!所以,写Python的时候,最关键的地方,在于调包,正如人类对工具的使用能力,决定了人类成为地球的霸主:Python调包的能力,决定了Python的效率。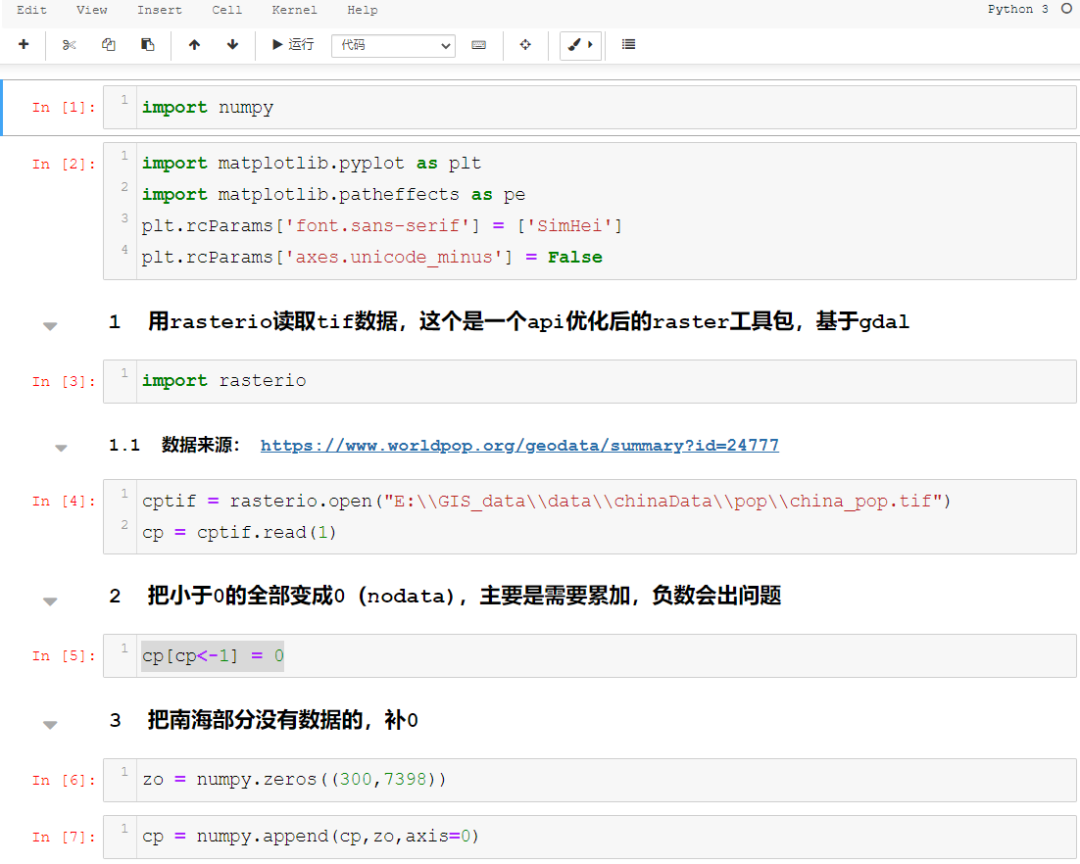

加入知识星球【我们谈论数据科学】
500+小伙伴一起学习!
· 推荐阅读 ·
盘点2021最佳数据可视化作品
一行代码实现地址信息解析
新一代Python包管理工具来了
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报
 下载APP
下载APP