
看起来满是 bug 的排序代码,居然是对的

转自:量子位 公众号( QbitAI )
程序 bug 也能负负得正吗?
还真可以。

比如程序员们再熟悉不过的排序算法,通过两个“bug”居然能歪打正着,实在令人匪夷所思。
请看这位程序员写的数组升序排序代码:
for i = 1 to n do
for j = 1 to n do
if A[i] < A[j] then
swap A[i] and A[j]
最近这串代码在 Hacker News 论坛上突然火了起来,引来大批程序员围观。
乍一看这段代码,你的反应会是什么?会不会觉得这个程序员水平太差了,连基本的冒泡算法都写不好:
不等号方向错了,第二层循环指数 j 的范围也弄错了。
总之,这段代码“绝对不可能正确”。

但如果你真的运行一下会发现,结果还真的是按照升序排列的。
我们再来看一下正确的冒泡算法代码是怎样的:
for i = 1 to n do
for j = i + 1 to n do
if A[i] > A[j] then
swap A[i] and A[j]
后者不同之处是 j = i + 1 且 A[i] > A[j],两段程序大相径庭。
然而我要告诉你一个不可思议的事实,其实第一串代码是对的,而且可以严格证明。
那么它是如何实现正确排序的?
为何能歪打正着
仔细一想,其实很容易理解。因为该算法比冒泡排序多一半交换操作,正好可以将降序编程升序。
不过,作者还是给出了严格的证明。
我们定义 Pᵢ 是经过 i 次(1 ≤ i ≤ n)外循环后得到的数组。
如果算法正确,那么前 i 项已经是升序排列,即 A[1] ≤ A[2] ≤ . . . ≤ A[i]。
证明该算法正确,实际上就是证明 Pₙ 对于任何 n 都成立。
根据数学归纳法,我们只要证明 P₁ 成立,假设 Pᵢ 成立,接着再证明 Pi+1 也成立,命题即可得证。
P₁ 显然是正确的,而且这一步和普通的冒泡算法降序没有区别,经过第 1 次外循环,A[1] 就是整个数组的最大元素。
接着我们假设 Pᵢ 成立,然后证明 Pi+1 成立。
我们先定义一个序数 k:
首先假设 A[k](k 介于 1~i 之间)满足 A[k]>A[i+1] 最小的一个数,那么 A[k−1]≤A[i+1](k≠1)。
如果 A[i+1]≥A[i],那么这样的 k 不存在,我们就令 k=i+1。
考虑以下三种情况:
1、1 ≤ j ≤ k−1
由于 A[i+1]>A[j],没有任何元素交换发生。
2、 k ≤ j ≤ i (如果 k=i+1,则不存在此步骤)
由于 A[j]>A[i+1],所以每次比较后都会有元素交换发生。
我们使用 A[ ] 和 A′[ ] 来表示交换前和交换后的元素,所以
A′[i+1] = A[k],A′[k]=A[i+1]
经过一系列交换,最大元素最终被放到了 A[i+1] 位置上,原来的 A[i+1] 变成了最大元素,A[k] 被插入了大小介于原来 A[k] 和 A[k-1] 之间的元素。
3、i+1 ≤ j ≤ n
由于最大元素已经交换到前 i+1 个元素中,此过程也没有任何元素交换。
最后,Pₙ 就是升序排序算法执行完以后的结果。
由于内外两组循环没有任何范围差别,因此这可以说是“最简单”的排序算法了。
从代码上来看,它很像冒泡算法,但从证明过程中可以看出,这实际上是一种插入算法。

算法复杂度
显然,该算法总会进行 n² 次比较,接下来计算算法的交换次数。
可以证明交换其次最多为 I+2(n-1),最少为 n-1。
其中 I 为初始数字的逆序数,最大为 n(n-1)/2
因此整个算法的复杂度为 O(n²)。
从证明过程中可以看出,除了 i=1 的循环以外,其余循环里 j=i-1 之后的部分完全无效,因此可以将这部分省略,得到简化后的算法。
for i = 2 to n do
for j = 1 to i − 1 do
if A[i] < A[j] then
swap A[i] and A[j]
该算法减少了比较和交换次数,不过算法复杂度依然是 O(n²)。
网友:这个算法我以前见过
比最容易理解的冒泡算法还要简单,这个排序算法在 Hacker News 上很快引起了网友的围观。
不少人觉得它“很眼熟”。
有位网友表示,自己曾在奥林匹克数学竞赛中看到一个同学用了一种非常奇怪的排序算法,它可以运行但是效率很低,更像是一种插入排序。
如果我没记错的话,他用的就是这种算法。

事实上,关于这种算法的讨论已久,从 2014 年开始就不断有人发帖,这次作者将论文上传到 arXiv 后又引起了广泛热议。
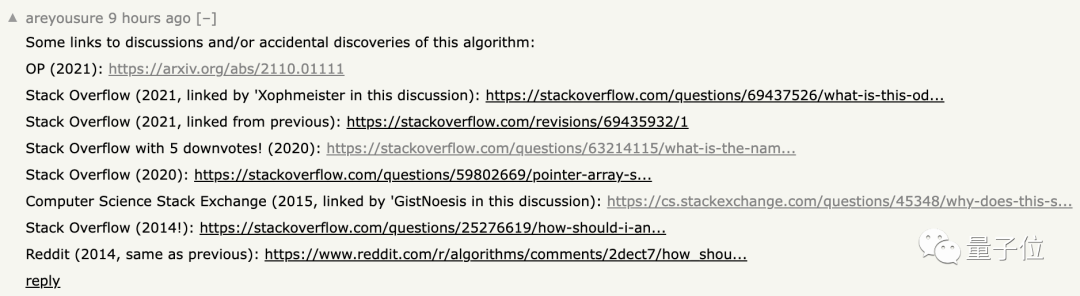
甚至还有乌龙事件发生。
有位网友扫了一眼论文就以为这个算法和自己 10 年前提出的一样。
留言网友的算法:

乍一看两种算法的代码确实很像,原理上的确有些相似。
都是看起来像冒泡排序,但其实更贴近选择排序。
不过很快有人指出真相:这种算法中 j=i+1 to n,并且是当 A[i] > A[j] 时交换。
而作者提出的算法中 j=1 to n,A[i] < A[j] 时交换。
两种算法相比,网友此前提出的更容易被理解为什么可以运行。

当然也有歪楼的,有人就调侃自己刚学编程时写过这个算法。
我百分百确定,在我刚开始学编程、并想要找到最短的排序方法时就写过它。


不过说到实际应用上,这种算法需要的计算时间太长了。
有人就认为,这种算法此前被发现过很多次,但是那些人根本没打算用它。

也有人提出:这种排序没有睡眠排序简单。

睡眠排序就是构造 n 个线程,让线程和排序的 n 个数对应。
例如对于 [4,2,3,5,9] 这样一组数字,就创建 5 个线程,每个线程睡眠 4s,2s,3s,5s,9s。这些线程睡醒之后,就把自己对应的数报出来即可。这样等所有线程都醒来,排序就结束了。
但和作者提出的算法一样,睡眠排序由于多线程的问题,在真正实现上也有困难。
此外,这位网友也表示自己看到过这种算法:
我确定我此前看到过这种算法,它没有名字吗?
很快就有人提议说——
如果它没有名字的话,我建议称之为“面试排序”。


E N D

各位伙伴们好,詹帅本帅搭建了一个个人博客和小程序,汇集各种干货和资源,也方便大家阅读,感兴趣的小伙伴请移步小程序体验一下哦!(欢迎提建议)
推荐阅读
推荐阅读