
10w字!前端知识体系+大厂面试笔记(工程化篇)
作者主页:
https://juejin.cn/user/2594503172831208
正文
工程化目的是为了提升团队的开发效率、提高项目的质量
例如大家所熟悉的构建工具、性能分析与优化、组件库等知识,都属于工程化的内容
这篇文章的内容,是我这几年对工程化的实践经验与收获总结
文中大部分的内容,主要是以 代码示例 + 分析总结 + 实践操作 来讲解的,始终围绕实用可操作性来说明,争取让小伙伴们更容易理解和运用
看十篇讲 webpack 的文章,可能不如手写一个 mini 版的 webpack 来的透彻
工程化是一个优秀工程师的必修课,也是一个重要的分水岭

前端工程化导图

构建工具
Webpack
Webpack是前端最常用的构建工具,重要程度无需多言
之前看过很多关于 Webpack 的文章,总是感觉云里雾里,现在换一种方式,我们一起来解密它,尝试打开这个盲盒
手写一个 mini 版的 Webpack
别担心
我们不需要去掌握具体的实现细节,而是通过这个案例,了解 webpack 的整体打包流程,明白这个过程中做了哪些事情,最终输出了什么结果即可
创建minipack.js
const fs = require('fs');
const path = require('path');
// babylon解析js语法,生产AST 语法树
// ast将js代码转化为一种JSON数据结构
const babylon = require('babylon');
// babel-traverse是一个对ast进行遍历的工具, 对ast进行替换
const traverse = require('babel-traverse').default;
// 将es6 es7 等高级的语法转化为es5的语法
const { transformFromAst } = require('babel-core');
// 每一个js文件,对应一个id
let ID = 0;
// filename参数为文件路径, 读取内容并提取它的依赖关系
function createAsset(filename) {
const content = fs.readFileSync(filename, 'utf-8');
// 获取该文件对应的ast 抽象语法树
const ast = babylon.parse(content, {
sourceType: 'module'
});
// dependencies保存所依赖的模块的相对路径
const dependencies = [];
// 通过查找import节点,找到该文件的依赖关系
// 因为项目中我们都是通过 import 引入其他文件的,找到了import节点,就找到这个文件引用了哪些文件
traverse(ast, {
ImportDeclaration: ({ node }) => {
// 查找import节点
dependencies.push(node.source.value);
}
});
// 通过递增计数器,为此模块分配唯一标识符, 用于缓存已解析过的文件
const id = ID++;
// 该`presets`选项是一组规则,告诉`babel`如何传输我们的代码.
// 用`babel-preset-env`将代码转换为浏览器可以运行的东西.
const { code } = transformFromAst(ast, null, {
presets: ['env']
});
// 返回此模块的相关信息
return {
id, // 文件id(唯一)
filename, // 文件路径
dependencies, // 文件的依赖关系
code // 文件的代码
};
}
// 我们将提取它的每一个依赖文件的依赖关系,循环下去:找到对应这个项目的`依赖图`
function createGraph(entry) {
// 得到入口文件的依赖关系
const mainAsset = createAsset(entry);
const queue = [mainAsset];
for (const asset of queue) {
asset.mapping = {};
// 获取这个模块所在的目录
const dirname = path.dirname(asset.filename);
asset.dependencies.forEach((relativePath) => {
// 通过将相对路径与父资源目录的路径连接,将相对路径转变为绝对路径
// 每个文件的绝对路径是固定、唯一的
const absolutePath = path.join(dirname, relativePath);
// 递归解析其中所引入的其他资源
const child = createAsset(absolutePath);
asset.mapping[relativePath] = child.id;
// 将`child`推入队列, 通过递归实现了这样它的依赖关系解析
queue.push(child);
});
}
// queue这就是最终的依赖关系图谱
return queue;
}
// 自定义实现了require 方法,找到导出变量的引用逻辑
function bundle(graph) {
let modules = '';
graph.forEach((mod) => {
modules += `${mod.id}: [
function (require, module, exports) { ${mod.code} },
${JSON.stringify(mod.mapping)},
],`;
});
const result = `
(function(modules) {
function require(id) {
const [fn, mapping] = modules[id];
function localRequire(name) {
return require(mapping[name]);
}
const module = { exports : {} };
fn(localRequire, module, module.exports);
return module.exports;
}
require(0);
})({${modules}})
`;
return result;
}
// ❤️ 项目的入口文件
const graph = createGraph('./example/entry.js');
const result = bundle(graph);
// ⬅️ 创建dist目录,将打包的内容写入main.js中
fs.mkdir('dist', (err) => {
if (!err)
fs.writeFile('dist/main.js', result, (err1) => {
if (!err1) console.log('打包成功');
});
});
注:mini版的Webpack未涉及 loader 和 plugin 等复杂功能,只是一个非常简化的例子
mini 版的 webpack 打包流程
1)从入口文件开始解析
2)查找入口文件引入了哪些 js 文件,找到依赖关系
3)递归遍历引入的其他 js,生成最终的依赖关系图谱
4)同时将 ES6 语法转化成 ES5
5)最终生成一个可以在浏览器加载执行的 js 文件
创建测试目录 example
在目录下创建以下 4 个文件
1)创建入口文件entry.js
import message from './message.js';
// 将message的内容显示到页面中
let p = document.createElement('p');
p.innerHTML = message;
document.body.appendChild(p);
2)创建message.js
import { name } from './name.js';
export default `hello ${name}!`;
3)创建name.js
export const name = 'Webpack';
4)创建index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Webpack App</title>
<meta name="viewport" content="width=device-width, initial-scale=1"></head>
<body>
<!-- 引入打包后的main.js -->
<script src="./dist/main.js"></script></body>
</html>
5) 执行打包
运行node minipack.js,dist 目录下生成 main.js
6) 浏览器打开 index.html
页面上显示hello Webpack!
mini-webpack 的 github 源码地址[1]
分析打包生成的文件
分析dist/main.js
文件内容
1)文件里是一个立即执行函数
2)该函数接收的参数是一个对象,该对象有 3 个属性0 代表entry.js;1 代表message.js;2 代表name.js
dist/main.js 代码
// 文件里是一个立即执行函数
(function(modules) {
function require(id) {
const [fn, mapping] = modules[id];
function localRequire(name) {
// ⬅️ 第四步 跳转到这里 此时mapping[name] = 1,继续执行require(1)
// ⬅️ 第六步 又跳转到这里 此时mapping[name] = 2,继续执行require(2)
return require(mapping[name]);
}
// 创建module对象
const module = { exports: {} };
// ⬅️ 第二步 执行fn
fn(localRequire, module, module.exports);
return module.exports;
}
// ⬅️ 第一步 执行require(0)
require(0);
})({
// 立即执行函数的参数是一个对象,该对象有3个属性
// 0 代表entry.js;
// 1 代表message.js
// 2 代表name.js
0: [
function(require, module, exports) {
'use strict';
// ⬅️ 第三步 跳转到这里 继续执行require('./message.js')
var _message = require('./message.js');
// ⬅️ 第九步 跳到这里 此时_message为 {default: 'hello Webpack!'}
var _message2 = _interopRequireDefault(_message);
function _interopRequireDefault(obj) {
return obj && obj.__esModule ? obj : { default: obj };
}
var p = document.createElement('p');
// ⬅️ 最后一步 将_message2.default: 'hello Webpack!'写到p标签中
p.innerHTML = _message2.default;
document.body.appendChild(p);
},
{ './message.js': 1 }
],
1: [
function(require, module, exports) {
'use strict';
Object.defineProperty(exports, '__esModule', {
value: true
});
// ⬅️ 第五步 跳转到这里 继续执行require('./name.js')
var _name = require('./name.js');
// ⬅️ 第八步 跳到这里 此时_name为{name: 'Webpack'}, 在exports对象上设置default属性,值为'hello Webpack!'
exports.default = 'hello ' + _name.name + '!';
},
{ './name.js': 2 }
],
2: [
function(require, module, exports) {
'use strict';
Object.defineProperty(exports, '__esModule', {
value: true
});
// ⬅️ 第七步 跳到这里 在传入的exports对象上添加name属性,值为'Webpack'
var name = (exports.name = 'Webpack');
},
{}
]
});
⬅️ 分析文件的执行过程
1)整体大致分为 10 步,第一步从require(0)开始执行,调用内置的自定义 require 函数,跳转到第二步,执行fn函数
2)执行第三步require('./message.js'),继续跳转到第四步 require(mapping['./message.js']), 最终转化为require(1)
3)继续执行require(1),获取modules[1],也就是执行message.js的内容
4)第五步require('./name.js'),最终转化为require(2),执行name.js的内容
5)通过递归调用,将代码中导出的属性,放到exports对象中,一层层导出到最外层
6)最终通过_message2.default获取导出的值,页面显示hello Webpack!
Webpack 的打包流程
总结一下 webpack 完整的打包流程
1)webpack 从项目的entry入口文件开始递归分析,调用所有配置的 loader对模块进行编译
因为 webpack 默认只能识别 js 代码,所以如 css 文件、.vue 结尾的文件,必须要通过对应的 loader 解析成 js 代码后,webpack 才能识别
2)利用babel(babylon)将 js 代码转化为ast抽象语法树,然后通过babel-traverse对 ast 进行遍历
3)遍历的目的找到文件的import引用节点
因为现在我们引入文件都是通过 import 的方式引入,所以找到了 import 节点,就找到了文件的依赖关系
4)同时每个模块生成一个唯一的 id,并将解析过的模块缓存起来,如果其他地方也引入该模块,就无需重新解析,最后根据依赖关系生成依赖图谱
5)递归遍历所有依赖图谱的模块,组装成一个个包含多个模块的 Chunk(块)
6)最后将生成的文件输出到 output 的目录中
热更新原理
什么是 webpack 热更新?
开发过程中,代码发生变动后,webpack 会重新编译,编译后浏览器替换修改的模块,局部更新,无需刷新整个页面
好处:节省开发时间、提升开发体验
热更新原理
主要是通过websocket实现,建立本地服务和浏览器的双向通信。当代码变化,重新编译后,通知浏览器请求更新的模块,替换原有的模块
1) 通过webpack-dev-server开启server服务,本地 server 启动之后,再去启动 websocket 服务,建立本地服务和浏览器的双向通信
2) webpack 每次编译后,会生成一个Hash值,Hash 代表每一次编译的标识。本次输出的 Hash 值会编译新生成的文件标识,被作为下次热更新的标识
3)webpack监听文件变化(主要是通过文件的生成时间判断是否有变化),当文件变化后,重新编译
4)编译结束后,通知浏览器请求变化的资源,同时将新生成的 hash 值传给浏览器,用于下次热更新使用
5)浏览器拿到更新后的模块后,用新模块替换掉旧的模块,从而实现了局部刷新
轻松理解 webpack 热更新原理[2]
深入浅出 Webpack[3]
带你深度解锁 Webpack 系列(基础篇)[4]
Plugin
作用:扩展 webpack 功能
工作原理
webpack 通过内部的事件流机制保证了插件的有序性,底层是利用发布订阅模式,webpack 在运行过程中会广播事件,插件只需要监听它所关心的事件,在特定的时机对资源做处理
手写一个 Plugin 插件
// 自定义一个名为MyPlugin插件,该插件在打包完成后,在控制台输出"打包已完成"
class MyPlugin {
// 原型上需要定义apply 的方法
apply(compiler) {
// 通过compiler获取webpack内部的钩子
compiler.hooks.done.tap("My Plugin", (compilation, cb) => {
console.log("打包已完成");
// 分为同步和异步的钩子,异步钩子必须执行对应的回调
cb();
});
}
}
module.exports = MyPlugin;
在 vue 项目中使用自定义插件
1)在vue.config.js引入该插件
const MyPlugin = require('./MyPlugin.js')
2)在configureWebpack的 plugins 列表中注册该插件
module.exports = {
configureWebpack: {
plugins: [new MyPlugin()]
}
};
3)执行项目的打包命令
当项目打包成功后,会在控制台输出:打包已完成
Plugin 的组成部分
1)Plugin 的本质是一个 node 模块,这个模块导出一个 JavaScript 类
2)它的原型上需要定义一个apply 的方法
3)通过compiler获取 webpack 内部的钩子,获取 webpack 打包过程中的各个阶段
钩子分为同步和异步的钩子,异步钩子必须执行对应的回调
4)通过compilation操作 webpack 内部实例特定数据
5)功能完成后,执行 webpack 提供的 cb 回调
compiler 上暴露的一些常用的钩子简介
| 钩子 | 类型 | 调用时机 |
|---|---|---|
| run | AsyncSeriesHook | 在编译器开始读取记录前执行 |
| compile | SyncHook | 在一个新的 compilation 创建之前执行 |
| compilation | SyncHook | 在一次 compilation 创建后执行插件 |
| make | AsyncParallelHook | 完成一次编译之前执行 |
| emit | AsyncSeriesHook | 在生成文件到 output 目录之前执行,回调参数: compilation |
| afterEmit | AsyncSeriesHook | 在生成文件到 output 目录之后执行 |
| assetEmitted | AsyncSeriesHook | 生成文件的时候执行,提供访问产出文件信息的入口,回调参数:file,info |
| done | AsyncSeriesHook | 一次编译完成后执行,回调参数:stats |
常用的 Plugin 插件
| 插件名称 | 作用 |
|---|---|
| html-webpack-plugin | 生成 html 文件,引入公共的 js 和 css 资源 |
| webpack-bundle-analyzer | 对打包后的文件进行分析,生成资源分析图 |
| terser-webpack-plugin | 代码压缩,移除 console.log 打印等 |
| HappyPack Plugin | 开启多线程打包,提升打包速度 |
| Dllplugin | 动态链接库,将项目中依赖的三方模块抽离出来,单独打包 |
| DllReferencePlugin | 配合 Dllplugin,通过 manifest.json 映射到相关的依赖上去 |
| clean-webpack-plugin | 清理上一次项目生成的文件 |
| vue-skeleton-webpack-plugin | vue 项目实现骨架屏 |
揭秘 webpack-plugin[5]
Loader
Loader 作用
webpack 只能直接处理 js 格式的资源,任何非 js 文件都必须被对应的loader处理转换为 js 代码
手写一个 loader
一个简单的style-loader
// 作用:将css内容,通过style标签插入到页面中
// source为要处理的css源文件
function loader(source) {
let style = `
let style = document.createElement('style');
style.setAttribute("type", "text/css");
style.innerHTML = ${source};
document.head.appendChild(style)`;
return style;
}
module.exports = loader;
在 vue 项目中使用自定义 loader
1)在vue.config.js引入该 loader
const MyStyleLoader = require('./style-loader')
2)在configureWebpack中添加配置
module.exports = {
configureWebpack: {
module: {
rules: [
{
// 对main.css文件使用MyStyleLoader处理
test: /main.css/,
loader: MyStyleLoader
}
]
}
}
};
3)项目重新编译main.css样式已加载到页面中
loader 的组成部分
loader 的本质是一个 node模块,该模块导出一个函数,函数接收source(源文件),返回处理后的source
loader 执行顺序
相同优先级的 loader 链,执行顺序为:从右到左,从下到上
如use: ['loader1', 'loader2', 'loader3'],执行顺序为 loader3 → loader2 → loader1
常用的 loader
| 名称 | 作用 |
|---|---|
| style-loader | 用于将 css 编译完成的样式,挂载到页面 style 标签上 |
| css-loader | 用于识别 .css 文件, 须配合 style-loader 共同使用 |
| sass-loader/less-loader | css 预处理器 |
| postcss-loader | 用于补充 css 样式各种浏览器内核前缀 |
| url-loader | 处理图片类型资源,可以转 base64 |
| vue-loader | 用于编译 .vue 文件 |
| worker-loader | 通过内联 loader 的方式使用 web worker 功能 |
| style-resources-loader | 全局引用对应的 css,避免页面再分别引入 |
揭秘 webpack-loader[6]
Webpack5 模块联邦
webpack5 模块联邦(Module Federation) 使 JavaScript 应用,得以从另一个 JavaScript 应用中动态的加载代码,实现共享依赖,用于前端的微服务化
比如项目A和项目B,公用项目C组件,以往这种情况,可以将 C 组件发布到 npm 上,然后 A 和 B 再具体引入。当 C 组件发生变化后,需要重新发布到 npm 上,A 和 B 也需要重新下载安装
使用模块联邦后,可以在远程模块的 Webpack 配置中,将 C 组件模块暴露出去,项目 A 和项目 B 就可以远程进行依赖引用。当 C 组件发生变化后,A 和 B 无需重新引用
模块联邦利用 webpack5 内置的ModuleFederationPlugin插件,实现了项目中间相互引用的按需热插拔
Webpack ModuleFederationPlugin
重要参数说明
1)name 当前应用名称,需要全局唯一
2)remotes 可以将其他项目的 name 映射到当前项目中
3)exposes 表示导出的模块,只有在此申明的模块才可以作为远程依赖被使用
4)shared 是非常重要的参数,制定了这个参数,可以让远程加载的模块对应依赖,改为使用本地项目的依赖,如 React 或 ReactDOM
配置示例
new ModuleFederationPlugin({
name: "app_1",
library: { type: "var", name: "app_1" },
filename: "remoteEntry.js",
remotes: {
app_02: 'app_02',
app_03: 'app_03',
},
exposes: {
antd: './src/antd',
button: './src/button',
},
shared: ['react', 'react-dom'],
}),
精读《Webpack5 新特性 - 模块联邦》[7]
Webpack 5 模块联邦引发微前端的革命?[8]
Webpack 5 升级内容(二:模块联邦)[9]
Vite
Vite 被誉为下一代的构建工具
上手了几个项目后,果然名不虚传,热更新速度真的是快的飞起!
Vite 原理
1)Vite 利用浏览器支持原生的es module模块,开发时跳过打包的过程,提升编译效率
2)当通过 import 加载资源时,浏览器会发出 HTTP 请求对应的文件,Vite拦截到该请求,返回对应的模块文件
es module 简单示例
<script type="module">import { a } from './a.js'</script>
1)当声明一个 script 标签类型为 module 时,浏览器将对其内部的 import 引用发起 HTTP 请求,获取模块内容
2)浏览器将发起一个对 HOST/a.js 的 HTTP 请求,获取到内容之后再执行
Vite 的限制
Vite 主要对应的场景是开发模式(生产模式是用 rollup 打包)
Vite 热更新速度
Vite 热更新的速度不会随着模块增多而变慢
1)Webpack 的热更新原理:一旦某个依赖(比如上面的 a.js)改变,就将这个依赖所处的 整个module 更新,并将新的 module 发送给浏览器重新执行
试想如果依赖越来越多,就算只修改一个文件,热更新的速度会越来越慢
2)Vite 的热更新原理:如果 a.js 发生了改变,只会重新编译这个文件 a,而其余文件都无需重新编译
所以理论上 Vite 热更新的速度不会随着文件增加而变慢
手写 vite
推荐珠峰的从零手写 vite 视频[10]
vite 的实现流程
1)通过koa开启一个服务,获取请求的静态文件内容
2)通过es-module-lexer 解析 ast 拿到 import 的内容
3)判断 import 导入模块是否为三方模块,是的话,返回node_module下的模块, 如 import vue 返回 import './@modules/vue'
4)如果是.vue文件,vite 拦截对应的请求,读取.vue 文件内容进行编译,通过compileTemplate 编译模板,将template转化为render函数
5)通过 babel parse 对 js 进行编译,最终返回编译后的 js 文件
尤雨溪几年前开发的“玩具 vite”[11]
Vite 原理浅析[12]
Babel
AST 抽象语法树
这里先聊一下AST抽象语法树,因为AST是babel的核心
什么是 AST ?
AST是源代码的抽象语法结构的树状表现形式
在 js 世界中,可以认为抽象语法树(AST)是最底层
一个简单的 AST 示例
let a = 1,转化成 AST 的结果
{
"type": "Program",
"start": 0,
"end": 9,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 9,
"declarations": [
{
"type": "VariableDeclarator",
"start": 4,
"end": 9,
"id": {
"type": "Identifier",
"start": 4,
"end": 5,
"name": "a"
},
"init": {
"type": "Literal",
"start": 8,
"end": 9,
"value": 1,
"raw": "1"
}
}
],
"kind": "let"
}
],
"sourceType": "module"
}
AST 抽象语法树的结构,可以通过AST 网站[13]在线输入代码查看
AST 抽象语法树——最基础的 javascript 重点知识,99%的人根本不了解[14]
Babel 基本原理与作用
Babel 是一个 JS 编译器,把我们的代码转成浏览器可以运行的代码
作用
babel 主要用于将新版本的代码转换为向后兼容的 js 语法(Polyfill 方式),以便能够运行在各版本的浏览器或其他环境中
基本原理
核心就是 AST (抽象语法树)
首先将源码转成抽象语法树,然后对语法树进行处理生成新的语法树,最后将新语法树生成新的 JS 代码
Babel 的流程
3 个阶段: parsing (解析)、transforming (转换)、generating (生成)
1)通过babylon将 js 转化成 ast (抽象语法树)
2)通过babel-traverse是一个对 ast 进行遍历,使用 babel 插件转化成新的 ast
3)通过babel-generator将 ast 生成新的 js 代码
配置和使用
1)单个软件包在 .babelrc 中配置
.babelrc {
// 预设: Babel 官方做了一些预设的插件集,称之为 Preset,我们只需要使用对应的 Preset 就可以了
"presets": [],
// babel和webpack类似,主要是通过plugin插件进行代码转化的,如果不配置插件,babel会将代码原样返回
"plugins": []
}
2)vue 中,在 babel.config.js 中配置
配置 babel-plugin-component 插件,按需引入 elementUI
module.exports = {
presets: ["@vue/app"],
// 配置babel-plugin-component插件
plugins: [
[
"component",
{
libraryName: "element-ui",
styleLibraryName: "theme-chalk"
}
]
]
};
3)配置browserslist
browserslist 用来控制要兼容浏览器版本,配置的范围越具体,就可以更精确控制Polyfill转化后的体积大小
"browserslist": [
// 全球超过1%人使用的浏览器
"> 1%",
// 所有浏览器兼容到最后两个版本根据CanIUse.com追踪的版本
"last 2 versions",
// chrome 版本大于70
"chrome >= 70"
// 排除部分版本
"not ie <= 8"
]
如何开发一个 babel 插件
Babel 插件的作用
Babel 插件担负着编译过程中的核心任务:转换 AST
babel 插件的基本格式
1)一个函数,参数是 babel,然后就是返回一个对象,key是visitor,然后里面的对象是一个箭头函数
2)函数有两个参数,path表示路径,state表示状态
3)CallExpression就是我们要访问的节点,path 参数表示当前节点的位置,包含的主要是当前节点(node)内容以及父节点(parent)内容
插件的简单格式示例
module.exports = function (babel) {
let t = babel.type
return {
visitor: {
CallExression: (path, state) => {
do soming
}}}}
一个最简单的插件: 将const a 转化为const b
创建 babelPluginAtoB.js
module.exports = function(babel) {
let t = babel.types;
return {
visitor: {
VariableDeclarator(path, state) {
// VariableDeclarator 是要找的节点类型
if (path.node.id.name == "a") {
// path.node.id.name = 'b' 是不行的,想改变某个值,就是用对应的ast来替换,所以我们要把id是a的ast换成b的ast
path.node.id = t.Identifier("b");
}
}
}
};
};
在.babelrc 中引入 babelPluginAtoB 插件
const babelPluginAtoB = require('./babelPluginAtoB.js');
{
"plugins": [
[babelPluginAtoB]
]
}
编写测试代码
let a = 1;
console.log(b);
// babel插件生效,没有报错,打印 1
Babel 入门教程[15]
Babel 中文文档[16]
不容错过的 Babel 知识[17]
快速写一个 babel 插件[18]
Gulp
gulp 是基于 node 流 实现的前端自动化开发的工具
适用场景
在前端开发工作中有很多“重复工作”,比如批量将Scss文件编译为CSS文件
这里主要聊一下,在开发的组件库中如何使用 gulp
Gulp 在组件库中的运用
以elementUI为例,下载elementUI 源码[19]
打开packages/theme-chalk/gulpfile.js
该文件的作用是将 scss 文件编译为 css 文件
'use strict';
// 引入gulp
// series创建任务列表,
// src创建一个流,读取文件
// dest 创建一个对象写入到文件系统的流
const { series, src, dest } = require('gulp');
// gulp-dart-sass编译scss文件
const sass = require('gulp-dart-sass');
// gulp-autoprefixer 给css样式添加前缀
const autoprefixer = require('gulp-autoprefixer');
// gulp-cssmin 压缩css
const cssmin = require('gulp-cssmin');
// 处理src目录下的所有scss文件,转化为css文件
function compile() {
return (
src('./src/*.scss')
.pipe(sass.sync().on('error', sass.logError))
.pipe(
// 给css样式添加前缀
autoprefixer({
overrideBrowserslist: ['ie > 9', 'last 2 versions'],
cascade: false
})
)
// 压缩css
.pipe(cssmin())
// 将编译好的css 输出到lib目录下
.pipe(dest('./lib'))
);
}
// 将src/fonts文件的字体文件 copy到 /lib/fonts目录下
function copyfont() {
return src('./src/fonts/**')
.pipe(cssmin())
.pipe(dest('./lib/fonts'));
}
// series创建任务列表
exports.build = series(compile, copyfont);
Gulp 给 elementUI 增加一键换肤功能
总体流程
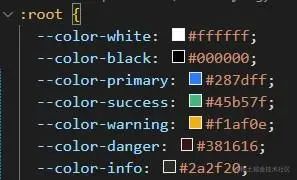
1)使用css var()定义颜色变量
2)创建主题theme.css文件,存储所有的颜色变量
3)使用gulp将theme.css合并到base.css中,解决按需引入的情况
4)使用gulp将index.css与base.css合并,解决全局引入的情况
步骤一:创建基础颜色变量theme.css文件
步骤二:修改packages/theme-chalk/src/common/var.scss文件
将该文件的中定义的 scss 变量,替换成 var()变量

步骤三:修改后的packages/theme-chalk/gulpfile.js
'use strict';
const {series, src, dest} = require('gulp');
const sass = require('gulp-dart-sass');
const autoprefixer = require('gulp-autoprefixer');
const cssmin = require('gulp-cssmin');
const concat = require('gulp-concat');
function compile() {
return src('./src/*.scss')
.pipe(sass.sync().on('error', sass.logError))
.pipe(autoprefixer({
overrideBrowserslist: ['ie > 9', 'last 2 versions'],
cascade: false
}))
.pipe(cssmin())
.pipe(dest('./lib'));
}
// 将 theme.css 和 lib/base.css合并成 最终的 base.css
function compile1() {
return src(['./src/theme.css', './lib/base.css'])
.pipe(concat('base.css'))
.pipe(dest('./lib'));
}
// 将 base.css、 index.css 合并成 最终的 index.css
function compile2() {
return src(['./lib/base.css', './lib/index.css'])
.pipe(concat('index.css'))
.pipe(dest('./lib'));
}
function copyfont() {
return src('./src/fonts/**')
.pipe(cssmin())
.pipe(dest('./lib/fonts'));
}
exports.build = series(compile, compile1, compile2, copyfont);
elementUI 多套主题下 按需引入和全局引入 的换肤方案[20]
脚手架
脚手架是开发中经常会使用的工具,比如vue-cli、create-react-app等,这些脚手架可以通过简单的命令,快速去搭建项目,让我们更专注于项目的开发
随着项目的增多、人员的扩展,大家开发的基础组件和公共方法也越来越多,希望把这些积累添加到脚手架中,当成项目模板留存下来
这样再创建项目时,就不用每次去其他项目中来回 copy
手写一个 mini 版的脚手架
下面我们一起,手写一个 mini 版的脚手架
通过这个案例来了解脚手架的工作流程,以及使用了哪些常用工具
新建文件夹my-build-cli,执行npm init -y

配置脚手架入口文件
1)创建bin目录,该目录下创建www.js
bin/www.js 内容
#! /usr/bin/env node
console.log('link 成功');
注:/usr/bin/env node 这行的意思是使用 node 来执行此文件
2)package.json中配置入口文件的路径
{
"name": "my-build-cli",
"version": "1.0.0",
"description": "",
"bin": "./bin/www.js", // 手动添加入口文件为 ./bin/www.js
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
3)项目目录结构
my-build-cli
├─ bin
│ └─ www.js
└─ package.json
npm link 到全局
在控制台输入npm link

测试是否连接成功
在控制台输入my-build-cli
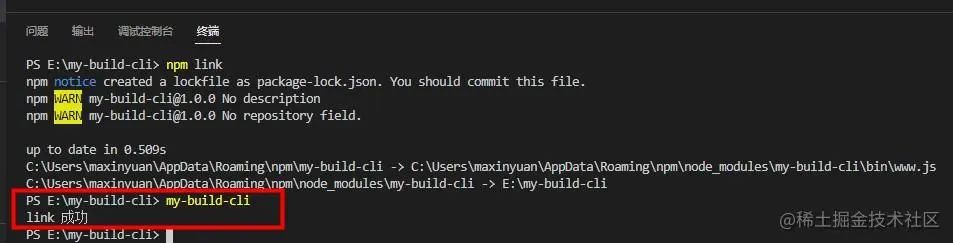
在控制台输出link 成功, 项目配置成功
安装脚手架所需的工具
一次性安装所需的工具
npm install commander inquirer download-git-repo util ora fs-extra axios
| 工具名称 | 作用 |
|---|---|
| commander | 自定义命令行工具 |
| inquirer | 命令行交互工具 |
| download-git-repo | 从 git 上下载项目模板工具 |
| util | download-git-repo 不支持异步调用,需要使用 util 插件的util.promisify进行转换 |
| ora | 命令行 loading 动效 |
| fs-extra | 提供文件操作方法 |
| axios | 发送接口,请求 git 上的模板列表 |
commander 自定义命令行工具
commander.js 是自定义命令行工具
这里用来创建create 命令,用户可以通过输入 my-cli creat appName 来创建项目
修改www.js
#! /usr/bin/env node
const program = require('commander');
program
// 创建create 命令,用户可以通过 my-cli creat appName 来创建项目
.command('create <app-name>')
// 命名的描述
.description('create a new project')
// create命令的选项
.option('-f, --force', 'overwrite target if it exist')
.action((name, options) => {
// 执行'./create.js',传入项目名称和 用户选项
require('./create')(name, options);
});
program.parse();
inquirer 命令行交互工具
inquirer.js 命令行交互工具,用来询问用户的操作,让用户输入指定的信息,或给出对应的选项让用户选择
此处 inquirer 的运用场景有 2 个
1)场景 1:当用户要创建的项目目录已存在时,提示用户是否要覆盖 or 取消
2)场景 2:让用户输入项目的author作者和项目description描述
创建create.js
bin/create.js
const path = require('path');
const fs = require('fs-extra');
const inquirer = require('inquirer');
const Generator = require('./generator');
module.exports = async function (name, options) {
// process.cwd获取当前的工作目录
const cwd = process.cwd();
// path.join拼接 要创建项目的目录
const targetAir = path.join(cwd, name);
// 如果该目录已存在
if (fs.existsSync(targetAir)) {
// 强制删除
if (options.force) {
await fs.remove(targetAir);
} else {
// 通过inquirer:询问用户是否确定要覆盖 or 取消
let { action } = await inquirer.prompt([
{
name: 'action',
type: 'list',
message: 'Target already exists',
choices: [
{
name: 'overwrite',
value: 'overwrite'
},
{
name: 'cancel',
value: false
}
]
}
]);
if (!action) {
return;
} else {
// 删除文件夹
await fs.remove(targetAir);
}
}
}
const args = require('./ask');
// 通过inquirer,让用户输入的项目内容:作者和描述
const ask = await inquirer.prompt(args);
// 创建项目
const generator = new Generator(name, targetAir, ask);
generator.create();
};
创建ask.js
配置 ask 选项,让用户输入作者和项目描述
bin/create.js
// 配置ask 选项
module.exports = [
{
type: 'input',
name: 'author',
message: 'author?'
},
{
type: 'input',
name: 'description',
message: 'description?'
}
];
创建generator.js
generator.js的工作流程
1)通过接口获取git上的模板目录
2)通过inquirer让用户选择需要下载的项目
3)使用download-git-repo下载用户选择的项目模板
4)将用户创建时,将项目名称、作者名字、描述写入到项目模板的package.json文件中
bin/generator.js
const path = require('path');
const fs = require('fs-extra');
// 引入ora工具:命令行loading 动效
const ora = require('ora');
const inquirer = require('inquirer');
// 引入download-git-repo工具
const downloadGitRepo = require('download-git-repo');
// download-git-repo 默认不支持异步调用,需要使用util插件的util.promisify 进行转换
const util = require('util');
// 获取git项目列表
const { getRepolist } = require('./http');
async function wrapLoading(fn, message, ...args) {
const spinner = ora(message);
// 下载开始
spinner.start();
try {
const result = await fn(...args);
// 下载成功
spinner.succeed();
return result;
} catch (e) {
// 下载失败
spinner.fail('Request failed ……');
}
}
// 创建项目类
class Generator {
// name 项目名称
// target 创建项目的路径
// 用户输入的 作者和项目描述 信息
constructor(name, target, ask) {
this.name = name;
this.target = target;
this.ask = ask;
// download-git-repo 默认不支持异步调用,需要使用util插件的util.promisify 进行转换
this.downloadGitRepo = util.promisify(downloadGitRepo);
}
async getRepo() {
// 获取git仓库的项目列表
const repolist = await wrapLoading(getRepolist, 'waiting fetch template');
if (!repolist) return;
const repos = repolist.map((item) => item.name);
// 通过inquirer 让用户选择要下载的项目模板
const { repo } = await inquirer.prompt({
name: 'repo',
type: 'list',
choices: repos,
message: 'Please choose a template'
});
return repo;
}
// 下载用户选择的项目模板
async download(repo, tag) {
const requestUrl = `yuan-cli/${repo}`;
await wrapLoading(this.downloadGitRepo, 'waiting download template', requestUrl, path.resolve(process.cwd(), this.target));
}
// 文件入口,在create.js中 执行generator.create();
async create() {
const repo = await this.getRepo();
console.log('用户选择了', repo);
// 下载用户选择的项目模板
await this.download(repo);
// 下载完成后,获取项目里的package.json
// 将用户创建项目的填写的信息(项目名称、作者名字、描述),写入到package.json中
let targetPath = path.resolve(process.cwd(), this.target);
let jsonPath = path.join(targetPath, 'package.json');
if (fs.existsSync(jsonPath)) {
// 读取已下载模板中package.json的内容
const data = fs.readFileSync(jsonPath).toString();
let json = JSON.parse(data);
json.name = this.name;
// 让用户输入的内容 替换到 package.json中对应的字段
Object.keys(this.ask).forEach((item) => {
json[item] = this.ask[item];
});
//修改项目文件夹中 package.json 文件
fs.writeFileSync(jsonPath, JSON.stringify(json, null, '\t'), 'utf-8');
}
}
}
module.exports = Generator;
创建http.js
用来发送接口,获取 git 上的模板列表
bin/http.js
// 引入axios
const axios = require('axios');
axios.interceptors.response.use((res) => {
return res.data;
});
// 获取git上的项目列表
async function getRepolist() {
return axios.get('https://api.github.com/orgs/yuan-cli/repos');
}
module.exports = {
getRepolist
};
最终的目录结构

脚手架效果演示
脚手架发布到 npm 库
完善 package.json
1)配置main属性,指定包的入口 "main": "./bin/www.js"
2)增加files属性,files 用来描述当把 npm 包,作为依赖包安装的文件列表。当 npm 包发布时,files 指定的文件会被推送到 npm 服务器中
3)增加description、keywords等描述字段
{
"name": "my-2022-cli",
"version": "1.1.0",
"description": "一个mini版的脚手架",
"main": "./bin/www.js",
"bin": "./bin/www.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"files": [
"bin"
],
"keywords": [
"my-yuan-cli",
"自定义脚手架"
],
"author": "海阔天空",
"license": "ISC",
"dependencies": {
"axios": "^0.24.0",
"commander": "^8.3.0",
"download-git-repo": "^3.0.2",
"fs-extra": "^10.0.0",
"inquirer": "^8.2.0",
"ora": "^5.4.1",
"util": "^0.12.4"
}
}
增加 README.md 说明文档
## my-2022-cli
一个 mini 版的自定义脚手架
### 安装
npm install my-2022-cli -g
### 使用说明
1)通过 my-2022-cli create appName 创建项目
2)author? 输入项目作者
3)description? 输入项目描述
4)选择项目模块 appDemo or pcDemo
5)安装选择的模板
### 演示示例

发布成功后,在 npm 网站搜索my-2022-cli
自定义脚手架 github 源码地址[21]
my-2022-cli[22]
性能分析与优化
一百用户与一百万用户的网站有着本质区别
随着用户的增长,任何细节的优化都变得更为重要,网站的性能差异直接影响着用户的体验
试想,如果我们在网上购物,商城页面好几秒才打开,或图片加载不出来,购物的欲望瞬间消减,抬手就去其他竞品平台了
我曾经负责过几个大型项目的整体性能优化,尽量从实战的角度聊一聊自己所理解的性能问题
性能分析工具
好比去医院看病一样,得了什么病,通过检测化验后才知道。网站也是一样,需要借助性能分析工具来检测
Lighthouse 工具
Lighthouse是 Chrome 自带的性能分析工具,它能够生成一个有关页面性能的报告
通过报告我们可以知道需要采取哪些措施,来改进应用的性能和体验
并且 Lighthouse 可以对页面多方面的效果指标进行评测,并给出最佳实践的建议,以帮助开发者改进网站的质量
Lighthouse 拿到页面的“病情”报告
通过 Lighthouse 拿到网站的整体分析报告,通过报告来诊断“病情”
这里以https://juejin.cn[23]网站为例, 打开 Chrome 浏览器控制台,选择Lighthouse选项,点击Generate report
Lighthouse 能够生成一份该网站的报告,比如下图:

这里重点关注Performance性能评分
性能评分的分值区间是 0 到 100,如果出现 0 分,通常是在运行 Lighthouse 时发生了错误,满分 100 分代表了网站已经达到了 98 分位值的数据,而 50 分则对应 75 分位值的数据
小伙伴看看自己开发的项目得分是多少,处于什么样的水平
Lighthouse 给出 Opportunities 优化建议
Lighthouse 会针对当前网站,给出一些Opportunities优化建议
Opportunities 指的是优化机会,它提供了详细的建议和文档,来解释低分的原因,帮助我们具体进行实现和改进
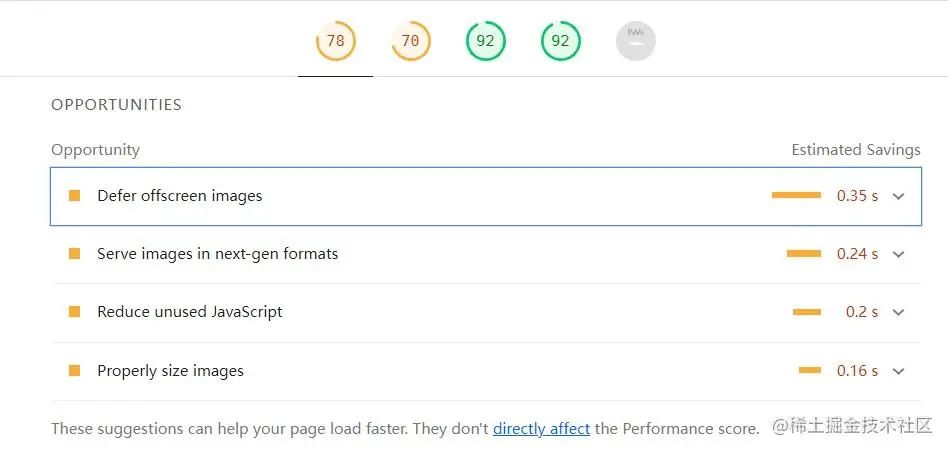
举一个我曾开发过的一个项目,以下是
Opportunities 给出优化建议列表
| 问题 | 建议 |
|---|---|
| Remove unused JavaScript | 去掉无用 js 代码 |
| Preload key requests | 首页资源 preload 预加载 |
| Remove unused CSS | 去掉无用 css 代码 |
| Serve images in next-gen formats | 使用新的图片格式,比如 webp 相对 png jpg 格式体积更小 |
| Efficiently encode images | 比如压缩图片大小 |
| Preconnect to required origins | 使用 preconnect or dns-prefetch DNS 预解析 |
Lighthouse 给出 Diagnostics 诊断问题列表
Diagnostics 指的是现在存在的问题,为进一步改善性能的验证和调整给出了指导

Diagnostics 诊断问题列表
| 问题 | 影响 |
|---|---|
| A long cache lifetime can speed up repeat visits to your page | 这些资源需要提供长的缓存期,现发现图片都是用的协商缓存,显然不合理 |
| Image elements do not have explicit width and height | 给图片设置具体的宽高,减少 cls 的值 |
| Avoid enormous network payloads | 资源太大增加网络负载 |
| Minimize main-thread work | 最小化主线程 这里会执行解析 Html、样式计算、布局、绘制、合成等动作 |
| Reduce JavaScript execution time | 减少非必要 js 资源的加载,减少必要 js 资源的大小 |
| Avoid large layout shifts | 避免大的布局变化,从中可以看到影响布局变化最大的元素 |
这些Opportunities建议和Diagnostics诊断问题是非常具体且有效的(亲测),开发者可以根据这些建议,一条条去修改或优化
Lighthouse 列出 Performance 各指标得分
Performance 列出了FCP、SP、LCP、TTI、TBI、CLS 六个指标的用时和得分情况
下文会聊一聊这些指标的用法与作用

性能测评工具 lighthouse 的使用[24]
Web-vitals 官方标准
web-vitals[25]是 Google 给出的定义是 一个良好网站的基本指标
过去要衡量一个网站的好坏,需要使用的指标太多了,现在我们可以将重点聚焦于 Web Vitals 指标的表现即可
官方指标标准
| 指标 | 作用 | 标准 |
|---|---|---|
| FCP(First Contentful Paint) | 首次内容绘制时间 | 标准 ≤1s |
| LCP(Largest Contentful Paint) | 最大内容绘制时间 | 标准 ≤2 秒 |
| FID(first input delay) | 首次输入延迟,标准是用户触发后,到浏览器响应时间 | 标准 ≤100ms |
| CLS(Cumulative Layout Shift) | 累积布局偏移 | 标准 ≤0.1 |
| TTFB(Time to First Byte) | 页面发出请求,到接收第一个字节所花费的毫秒数(首字节时间) | 标准<= 100 毫秒 |
我们将 Lighthouse 中 Performance 列出的指标表现,与官方指标标准做对比,可以发现页面哪些指标超出了范围
Performance 工具
通过 Lighthouse 我们知道了页面整体的性能得分,但是页面打开慢或者卡顿的瓶颈在哪里?
具体是加载资源慢、dom渲染慢、还是js执行慢呢?
chrome 浏览器提供的performance是常用来查看网页性能的工具,通过该工具,我们可以知道页面在浏览器运行时的性能表现
Performance 寻找性能瓶颈
打开 Chrome 浏览器控制台,选择Performance选项,点击左侧reload图标
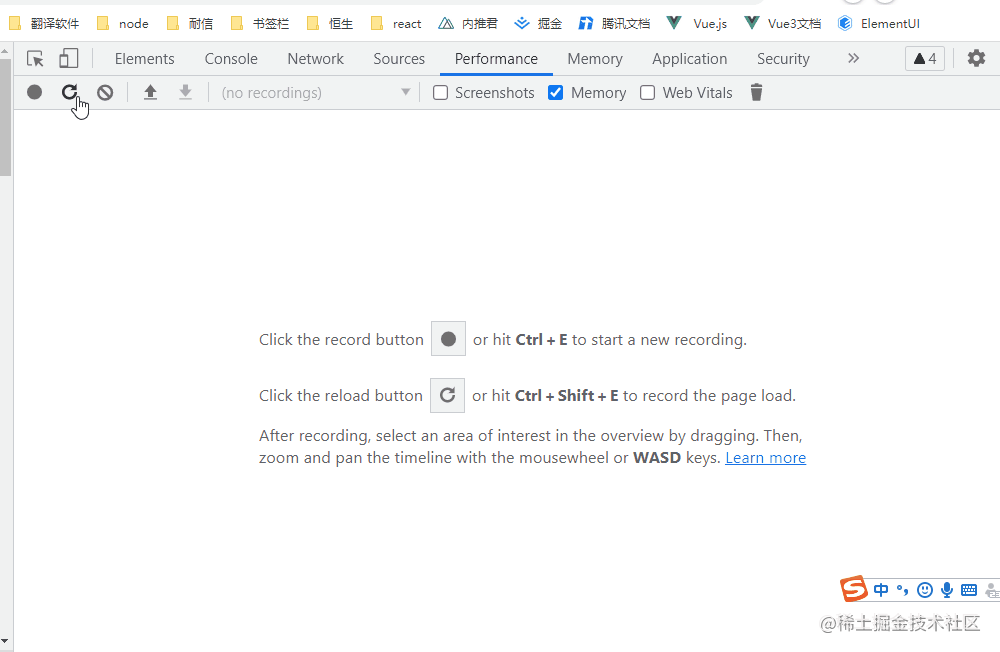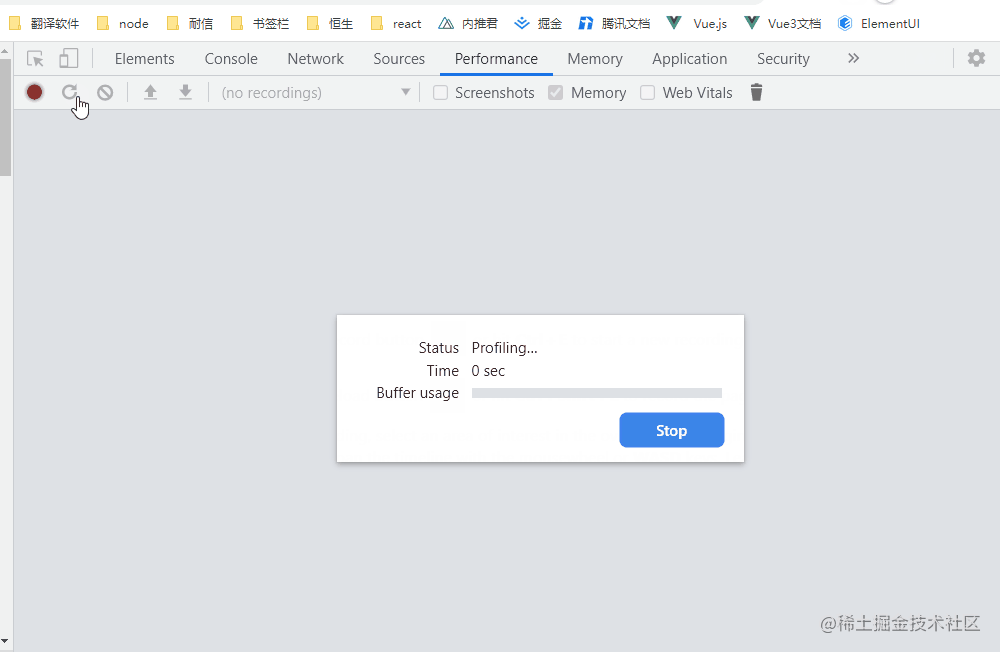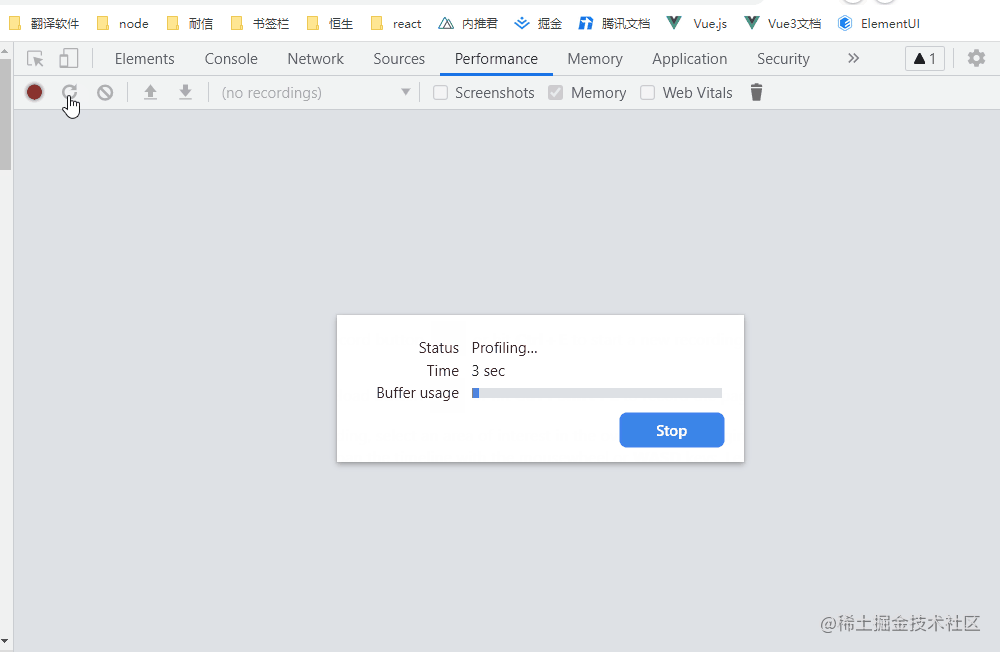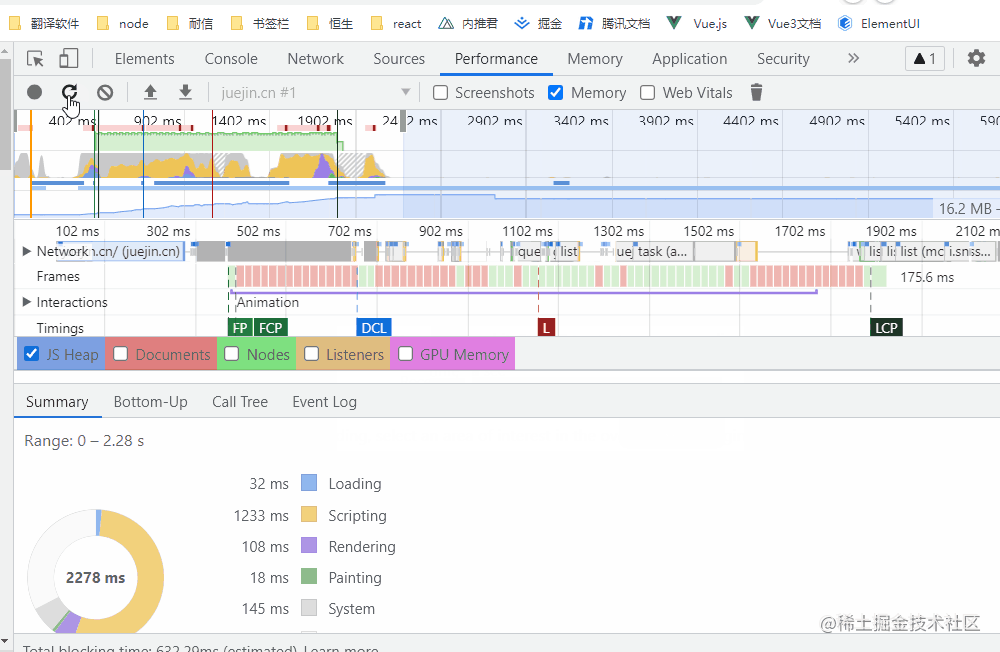
Performance 面板可以记录和分析页面在运行时的所有活动,大致分为以下 4 个区域
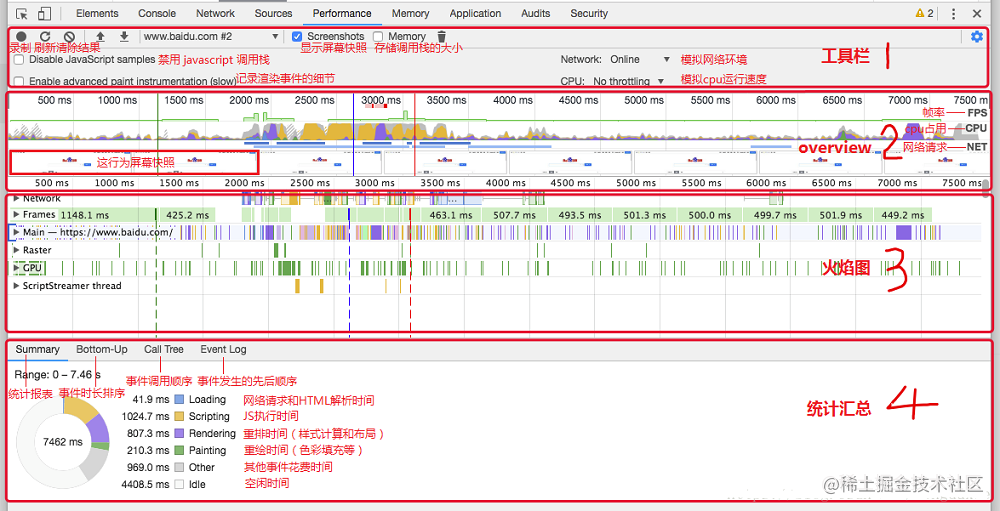
Performance 各区域功能介绍
1)FPS
FPS(Frames Per Second),表示每秒传输帧数,是用来分析页面是否卡顿的一个主要性能指标
如下图所示,绿色的长条越高,说明FPS越高,用户体验越好
如果发现了一个红色的长条,那么就说明这些帧存在严重问题,可能会造成页面卡顿

2)NET
NET 记录资源的等待、下载、执行时间,每条彩色横杠表示一种资源
横杠越长,检索资源所需的时间越长。每个横杠的浅色部分表示等待时间(从请求资源到第一个字节下载完成的时间)
Network 的颜色说明:白色表示等待的颜色、浅黄色表示请求的时间、深黄色表示下载的时间
在这里,我们可以看到所有资源的加载过程,有两个地方重点关注:
1)资源等待的时间是否过长(标准 ≤100ms)
2)资源文件体积是否过大,造成加载很慢(就要考虑如何拆分该资源)

3)火焰图
火焰图(Flame Chart)用来可视化 CPU 堆栈信息记录
 1)Network: 表示加载了哪些资源
1)Network: 表示加载了哪些资源
2)Frames:表示每幅帧的运行情况
3)Timings: 记录页面中关键指标的时间
4)Main:表示主线程(重点,下文会详细介绍)
5)GPU:表示 GPU 占用情况
4)统计汇总
Summary: 表示各指标时间占用统计报表
1)Loading: 加载时间
2)Scripting: js计算时间
3)Rendering: 渲染时间
4)Painting: 绘制时间
5)Other: 其他时间
6)Idle: 浏览器闲置时间
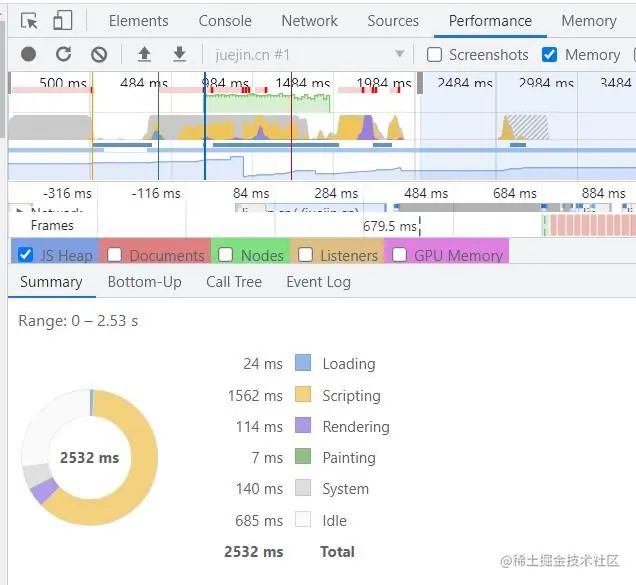
Performance Main 性能瓶颈的突破口
Main 表示主线程,主要负责
1)Javascript 的计算与执行
2)CSS 样式计算
3)Layout 布局计算
4)将页面元素绘制成位图(paint),也就是光栅化(Raster)
展开 Main,可以发现很多红色三角(long task),这些执行时间超过 50ms就属于长任务,会造成页面卡顿,严重时会造成页面卡死
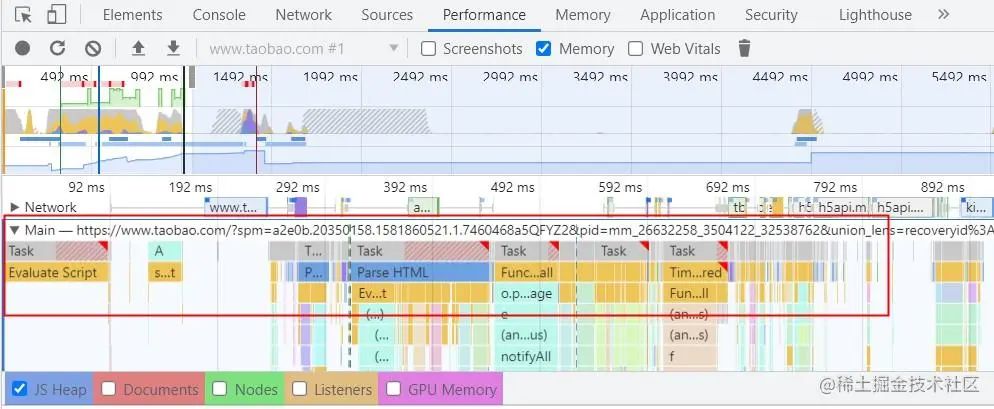
展开其中一个红色三角,Devtools 在Summary面板里展示了更多关于这个事件的信息
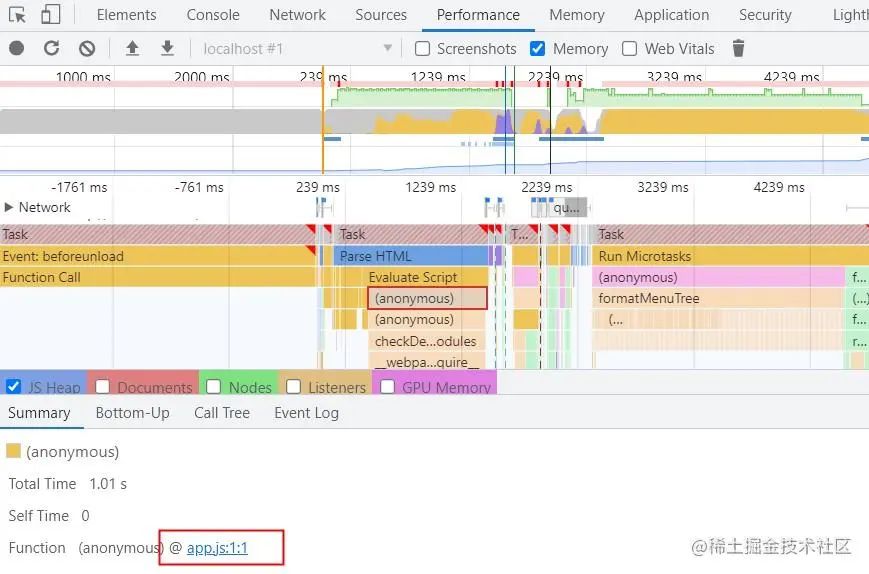
在 summary 面板里点击app.js链接,Devtools 可以跳转到需要优化的代码处

下面我们需要结合自己的代码逻辑,去判断这块代码为什么执行时间超长?
如何去解决或优化这些long task,从而解决去页面的性能瓶颈
全新 Chrome Devtool Performance 使用指南[26]
手把手带你入门前端工程化——超详细教程[27]
Chrome Devtool — Performance[28]
性能监控
项目发布生产后,用户使用时的性能如何,页面整体的打开速度是多少、白屏时间多少,FP、FCP、LCP、FID、CLS 等指标,要设置多大的阀值呢,才能满足TP50、TP90、TP99的要求呢?
TP 指标: 总次数 * 指标数 = 对应 TP 指标的值。
设置每个指标的阀值,比如 FP 指标,设置阀值为 1s,要求 Tp95,即 95%的 FP 指标,要在 1s 以下,剩余 5%的指标超过 1s
TP50 相对较低,TP90 则比较高,TP99,TP999 则对性能要求很高
这里就需要性能监控,采集到用户的页面数据
性能指标的计算
常用的两种方式:
方式一:通过 web-vitals 官方库进行计算
import {onLCP, onFID, onCLS} from 'web-vitals';
onCLS(console.log);
onFID(console.log);
onLCP(console.log);
方式二:通过performance api进行计算
下面聊一下 performance api 来计算各种指标
打开任意网页,在控制台中输入 performance 回车,可以看到一系列的参数,
performance.timing
重点看下performance.timing,记录了页面的各个关键时间点
| 时间 | 作用 |
|---|---|
navigationStart | (可以理解为该页面的起始时间)同一个浏览器上下文的上一个文档卸载结束时的时间戳,如果没有上一个文档,这个值会和 fetchStart 相同 |
| unloadEventStart | unload 事件抛出时的时间戳,如果没有上一个文档,这个值会是 0 |
| unloadEventEnd | unload 事件处理完成的时间戳,如果没有上一个文档,这个值会是 0 |
| redirectStart | 第一个 HTTP 重定向开始时的时间戳,没有重定向或者重定向中的不同源,这个值会是 0 |
| redirectEnd | 最后一个 HTTP 重定向开始时的时间戳,没有重定向或者重定向中的不同源,这个值会是 0 |
| fetchStart | 浏览器准备好使用 HTTP 请求来获取文档的时间戳。发送在检查缓存之前 |
| domainLookupStart | 域名查询开始的时间戳,如果使用了持续连接或者缓存,则与 fetchStart 一致 |
| domainLookupEnd | 域名查询结束的时间戳,如果使用了持续连接或者缓存,则与 fetchStart 一致 |
| connectStart | HTTP 请求开始向服务器发送时的时间戳,如果使用了持续连接,则与 fetchStart 一致 |
| connectEnd | 浏览器与服务器之间连接建立(所有握手和认证过程全部结束)的时间戳,如果使用了持续连接,则与 fetchStart 一致 |
| secureConnectionStart | 浏览器与服务器开始安全连接握手时的时间戳,如果当前网页不需要安全连接,这个值会是 0 |
requestStart | 浏览器向服务器发出 HTTP 请求的时间戳 |
responseStart | 浏览器从服务器收到(或从本地缓存读取)第一个字节时的时间戳 |
| responseEnd | 浏览器从服务器收到(或从本地缓存读取)最后一个字节时(如果在此之前 HTTP 连接已经关闭,则返回关闭时)的时间戳 |
domLoading | 当前网页 DOM 结构开始解析时的时间戳 |
| domInteractive | 当前网页 DOM 结构解析完成,开始加载内嵌资源时的时间戳 |
| domContentLoadedEventStart | 需要被执行的脚本已经被解析的时间戳 |
| domContentLoadedEventEnd | 需要立即执行的脚本已经被执行的时间戳 |
domComplete | 当前文档解析完成的时间戳 |
| loadEventStart | load 事件被发送时的时间戳,如果这个事件还未被发送,它的值将会是 0 |
loadEventEnd | load 事件结束时的时间戳,如果这个事件还未被发送,它的值将会是 0 |
白屏时间 FP
白屏时间 FP(First Paint)指的是从用户输入 url 的时刻开始计算,一直到页面有内容展示出来的时间节点,标准≤2s
这个过程包括 dns 查询、建立 tcp 连接、发送 http 请求、返回 html 文档、html 文档解析
const entryHandler = (list) => {
for (const entry of list.getEntries()) {
if (entry.name === 'first-paint') {
observer.disconnect()}
// 其中startTime 就是白屏时间
let FP = entry.startTime)
}
}
const observer = new PerformanceObserver(entryHandler)
// buffered 属性表示是否观察缓存数据,也就是说观察代码添加时机比事件触发时机晚也没关系。
observer.observe({ type: 'paint', buffered: true })
首次内容绘制时间 FCP
FCP(First Contentful Paint) 表示页面任一部分渲染完成的时间,标准≤1s
// 计算方式:
const entryHandler = (list) => {
for (const entry of list.getEntries()) {
if (entry.name === 'first-contentful-paint') {
observer.disconnect()
}
// 计算首次内容绘制时间
let FCP = entry.startTime
}
}
const observer = new PerformanceObserver(entryHandler)
observer.observe({ type: 'paint', buffered: true })
最大内容绘制时间 LCP
LCP(Largest Contentful Paint)表示最大内容绘制时间,标准≤2 秒
// 计算方式:
const entryHandler = (list) => {
if (observer) {
observer.disconnect()
}
for (const entry of list.getEntries()) {
// 最大内容绘制时间
let LCP = entry.startTime
}
}
const observer = new PerformanceObserver(entryHandler)
observer.observe({ type: 'largest-contentful-paint', buffered: true })
累积布局偏移值 CLS
CLS(Cumulative Layout Shift) 表示累积布局偏移,标准≤0.1
// cls为累积布局偏移值
let cls = 0;
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
if (!entry.hadRecentInput) {
cls += entry.value;
}
}
}).observe({type: 'layout-shift', buffered: true});
首字节时间 TTFB
平常所说的TTFB,默认指导航请求的TTFB
导航请求:在浏览器切换页面时创建,从导航开始到该请求返回 HTML
window.onload = function () {
// 首字节时间
let TTFB = responseStart - navigationStart;
};
首次输入延迟 FID
FID(first input delay)首次输入延迟,标准是用户触发后,浏览器的响应时间, 标准≤100ms
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
// 计算首次输入延迟时间
const FID = entry.processingStart - entry.startTime;
}
}).observe({ type: 'first-input', buffered: true });
FID 推荐使用 web-vitals 库,因为官方兼容了很多场景
首页加载时间
window.onload = function () {
// 首页加载时间
// domComplete 是document的readyState = complete(完成)的状态
let firstScreenTime = performance.timing.domComplete - performance.timing.navigationStart;
};
首屏加载时间
首屏加载时间和首页加载时间不一样,首屏指的是用户看到屏幕内页面渲染完成的时间
比如首页很长需要好几屏展示,这种情况下屏幕以外的元素不考虑在内
计算首屏加载时间流程
1)利用MutationObserver监听document对象,每当 dom 变化时触发该事件
2)判断监听的 dom 是否在首屏内,如果在首屏内,将该 dom 放到指定的数组中,记录下当前 dom 变化的时间点
3)在 MutationObserver 的 callback 函数中,通过防抖函数,监听document.readyState状态的变化
4)当document.readyState === 'complete',停止定时器和 取消对 document 的监听
5)遍历存放 dom 的数组,找出最后变化节点的时间,用该时间点减去performance.timing.navigationStart 得出首屏的加载时间
定义 performance.js
// firstScreenPaint为首屏加载时间的变量
let firstScreenPaint = 0;
// 页面是否渲染完成
let isOnLoaded = false;
let timer;
let observer;
// 定时器循环监听dom的变化,当document.readyState === 'complete'时,停止监听
function checkDOMChange(callback) {
cancelAnimationFrame(timer);
timer = requestAnimationFrame(() => {
if (document.readyState === 'complete') {
isOnLoaded = true;
}
if (isOnLoaded) {
// 取消监听
observer && observer.disconnect();
// document.readyState === 'complete'时,计算首屏渲染时间
firstScreenPaint = getRenderTime();
entries = null;
// 执行用户传入的callback函数
callback && callback(firstScreenPaint);
} else {
checkDOMChange();
}
});
}
function getRenderTime() {
let startTime = 0;
entries.forEach((entry) => {
if (entry.startTime > startTime) {
startTime = entry.startTime;
}
});
// performance.timing.navigationStart 页面的起始时间
return startTime - performance.timing.navigationStart;
}
const viewportWidth = window.innerWidth;
const viewportHeight = window.innerHeight;
// dom 对象是否在屏幕内
function isInScreen(dom) {
const rectInfo = dom.getBoundingClientRect();
if (rectInfo.left < viewportWidth && rectInfo.top < viewportHeight) {
return true;
}
return false;
}
let entries = [];
// 外部通过callback 拿到首屏加载时间
export default function observeFirstScreenPaint(callback) {
const ignoreDOMList = ['STYLE', 'SCRIPT', 'LINK'];
observer = new window.MutationObserver((mutationList) => {
checkDOMChange(callback);
const entry = { children: [] };
for (const mutation of mutationList) {
if (mutation.addedNodes.length && isInScreen(mutation.target)) {
for (const node of mutation.addedNodes) {
// 忽略掉以上标签的变化
if (node.nodeType === 1 && !ignoreDOMList.includes(node.tagName) && isInScreen(node)) {
entry.children.push(node);
}
}
}
}
if (entry.children.length) {
entries.push(entry);
entry.startTime = new Date().getTime();
}
});
observer.observe(document, {
childList: true, // 监听添加或删除子节点
subtree: true, // 监听整个子树
characterData: true, // 监听元素的文本是否变化
attributes: true // 监听元素的属性是否变化
});
}
外部引入使用
import observeFirstScreenPaint from './performance';
// 通过回调函数,拿到首屏加载时间
observeFirstScreenPaint((data) => {
console.log(data, '首屏加载时间');
});
DOM 渲染时间和 window.onload 时间
DOM 的渲染的时间和 window.onload 执行的时间不是一回事
DOM 渲染的时间
DOM渲染的时间 = performance.timing.domComplete - performance.timing.domLoading
window.onload 要晚于 DOM 的渲染,window.onload 是页面中所有的资源都加载后才执行(包括图片的加载)
window.onload 的时间
window.onload的时间 = performance.timing.loadEventEnd
计算资源的缓存命中率
缓存命中率:从缓存中得到数据的请求数与所有请求数的比率
理想状态是缓存命中率越高越好,缓存命中率越高说明网站的缓存策略越有效,用户打开页面的速度也会相应提高
如何判断该资源是否命中缓存?
1)通过performance.getEntries()找到所有资源的信息
2)在这些资源对象中有一个transferSize 字段,它表示获取资源的大小,包括响应头字段和响应数据的大小
3)如果这个值为 0,说明是从缓存中直接读取的(强制缓存)
4)如果这个值不为 0,但是encodedBodySize 字段为 0,说明它走的是协商缓存(encodedBodySize 表示请求响应数据 body 的大小)
function isCache(entry) {
// 直接从缓存读取或 304
return entry.transferSize === 0 || (entry.transferSize !== 0 && entry.encodedBodySize === 0);
}
将所有命中缓存的数据 / 总数据 就能得出缓存命中率
性能数据上报
上报方式
一般使用图片打点的方式,通过动态创建 img 标签的方式,new 出像素为1x1 px的gif Image(gif 体积最小)对象就能发起请求,可以跨域、不需要等待服务器返回数据
上报时机
可以利用requestIdleCallback,浏览器空闲的时候上报,好处是:不阻塞其他流程的进行
如果浏览器不支持该requestIdleCallback,就使用setTimeout上报
// 优先使用requestIdleCallback
if (window.requestIdleCallback) {
window.requestIdleCallback(
() => {
// 获取浏览器的剩余空闲时间
console.log(deadline.timeRemaining());
report(data); // 上报数据
},
// timeout设置为1000,如果在1000ms内没有执行该后调,在下次空闲时间时,callback会强制执行
{ timeout: 1000 }
);
} else {
setTimeout(() => {
report(data); // 上报数据
});
}
内存分析与优化
性能分析很火,但内存分析相比就低调很多了
举一个我之前遇到的情况,客户电脑配置低,打开公司开发的页面,经常出现页面崩溃
调查原因,就是因为页面内存占用太大,客户打开几个页面后,内存直接拉满,也是经过这件事,我开始重视内存分析与优化
下面,聊一聊内存这块有哪些知识
Memory 工具
Memory 工具,通过内存快照的方式,分析当前页面的内存使用情况
Memory 工具使用流程
1)打开 chrome 浏览器控制台,选择Memory工具
2)点击左侧start按钮,刷新页面,开始录制的JS堆动态分配时间线,会生成页面加载过程内存变化的柱状统计图(蓝色表示未回收,灰色表示已回收)
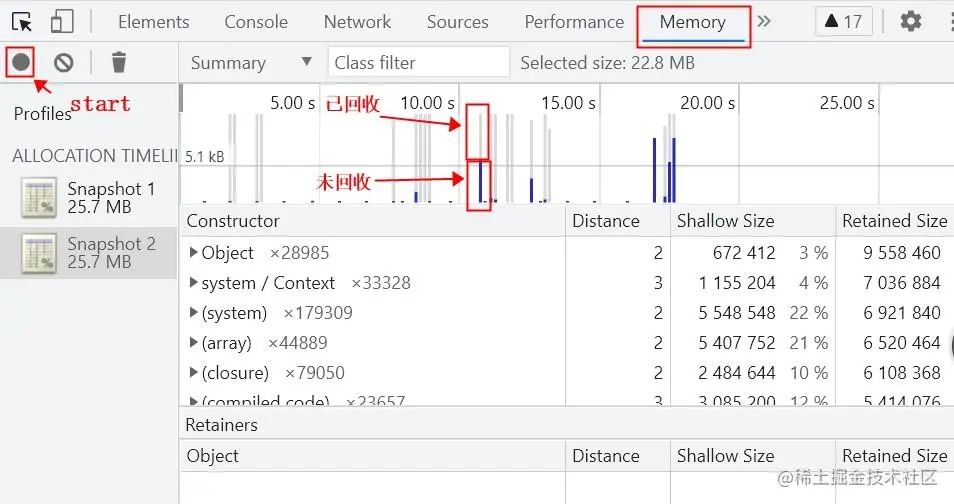
Memory 工具中的关键项
关键项
Constructor:对象的类名;
Distance:对象到根的引用层级;
Objects Count:对象的数量;
Shallow Size: 对象本身占用的内存,不包括引用的对象所占内存;
Retained Size: 对象所占总内存,包含引用的其他对象所占内存;
Retainers:对象的引用层级关系
通过一段测试代码来了解 Memory 工具各关键性的关系
// 测试代码
class Jane {}
class Tom {
constructor () { this.jane = new Jane();}
}
Array(1000000).fill('').map(() => new Tom())
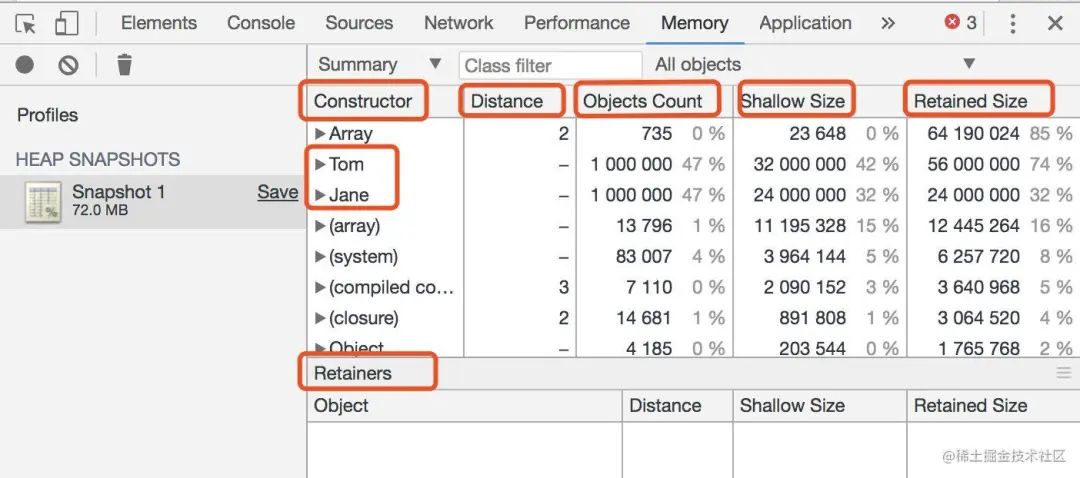
shallow size 和 retained size 的区别,以用红框里的 Tom 和 Jane 更直观的展示
Tom 的 shallow 占了 32M,retained 占用了 56M,这是因为 retained 包括了引用的指针对应的内存大小,即 tom.jane 所占用的内存
所以 Tom 的 retained 总和比 shallow 多出来的 24M,正好跟 Jane 占用的 24M 相同
retained size 可以理解为当回收掉该对象时可以释放的内存大小,在内存调优中具有重要参考意义
内存分析的关键点
找到内存最高的节点,分析这些时刻执行了哪些代码,发生了什么操作,尽可能去优化它们
1)从柱状图中找到最高的点,重点分析该时间内造成内存变大的原因
2)按照Retainers size(总内存大小)排序,点击展开内存最高的哪一项,点击展开构造函数,可以看到所有构造函数相关的对象实例
3)选中构造函数,底部会显示对应源码文件,点击源码文件,可以跳转到具体的代码,这样我们就知道是哪里的代码造成内存过大
4)结合具体的代码逻辑,来判断这块内存变大的原因,重点是如何去优化它们,降低内存的使用大小
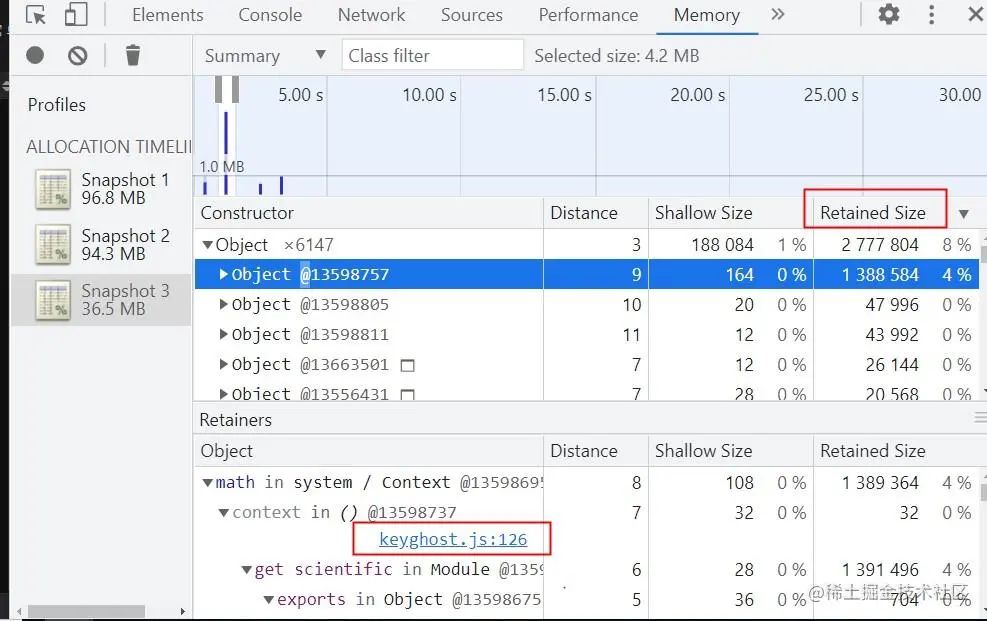
点击keyghost.js可以跳转到具体的源码
内存泄露的情况
1)意外的全局变量, 挂载到 window 上全局变量
2)遗忘的定时器,定时器没有清除
3)闭包不当的使用
内存分析总结
1)利用 Memory 工具,了解页面整体的内存使用情况
2)通过 JS 堆动态分配时间线,找到内存最高的时刻
3)按照 Retainers size(总内存大小)排序,点击展开内存最高的前几项,分析由于哪个函数操作导致了内存过大,甚至是内存泄露
4)结合具体的代码,去解决或优化内存变大的情况
chrome 内存泄露(一)、内存泄漏分析工具[29]
chrome 内存泄露(二)、内存泄漏实例[30]
JavaScript 进阶-常见内存泄露及如何避免[31]
项目优化总结
优化的本质:响应更快,展示更快
更详细的说,是指在用户输入 url,到页面完整展示出来的过程中,通过各种优化策略和方法,让页面加载更快;在用户使用过程中,让用户的操作响应更及时,有更好的用户体验
经典:雅虎军规
很多前端优化准则都是围绕着这个展开
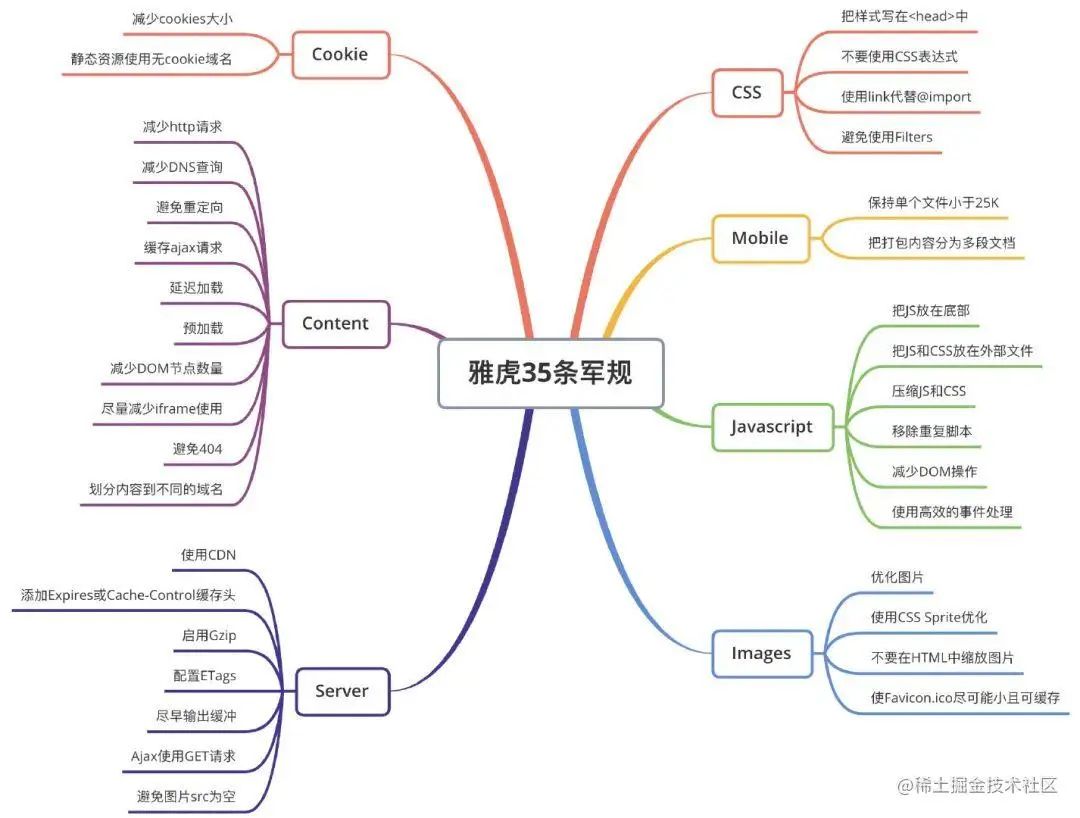
优化建议
结合我曾经负责优化的项目实践,在下面总结了一些经验与方法,提供给大家参考
1、分析打包后的文件
可以使用webpack-bundle-analyzer[32]插件(vue 项目可以使用--report)生成资源分析图
我们要清楚的知道项目中使用了哪些三方依赖,以及依赖的作用。特别对于体积大的依赖,分析是否能优化
比如:组件库如elementUI的按需引入、Swiper轮播图组件打包后的体积约 200k,看是否能替换成体积更小的插件、momentjs去掉无用的语言包等

2、合理处理公共资源
如果项目支持 CDN,可以配置externals,将Vue、Vue-router、Vuex、echarts等公共资源,通过 CDN 的方式引入,不打到项目里边
如果项目不支持 CDN,可以使用DllPlugin动态链接库,将业务代码和公共资源代码相分离,公共资源单独打包,给这些公共资源设置强缓存(公共资源基本不会变),这样以后可以只打包业务代码,提升打包速度
3、首屏必要资源 preload 预加载 和 DNS 预解析
preload 预加载
<link rel="preload" href="/path/style.css" as="style"><link rel="preload" href="/path/home.js" as="script">
preload 预加载是告诉浏览器页面必定需要的资源,浏览器会优先加载这些资源;使用 link 标签创建(vue 项目打包后,会将首页所用到的资源都加上 preload)
注意:preload 只是预加载资源,但不会执行,还需要引入具体的文件后才会执行 <script src='/path/home.js'>
DNS 预解析
DNS Prefetch 是一种 DNS 预解析技术,当你浏览网页时,浏览器会在加载网页时,对网页中的域名进行解析缓存
这样在你单击当前网页中的连接时就无需进行DNS 的解析,减少用户等待时间,提高用户体验
使用dns-prefetch,如<link rel="dns-prefetch" href="//img1.taobao.com">
很多大型的网站,都会用N 个CDN 域名来做图片、静态文件等资源访问。解析单个域名同样的地点加上高并发难免有点堵塞,通过多个 CDN 域名来分担高并发下的堵塞
4、首屏不必要资源延迟加载
方式一: defer 或 async
使用 script 标签的defer或async属性,这两种方式都是异步加载 js,不会阻塞 DOM 的渲染
async 是无顺序的加载,而 defer 是有顺序的加载
1)使用 defer 可以用来控制 js 文件的加载顺序
比如 jq 和 Bootstrap,因为 Bootstrap 中的 js 插件依赖于 jqery,所以必须先引入 jQuery,再引入 Bootstrap js 文件
2)如果你的脚本并不关心页面中的 DOM 元素(文档是否解析完毕),并且也不会产生其他脚本需要的数据,可以使用 async,如添加统计、埋点等资源
方式二:依赖动态引入
项目依赖的资源,推荐在各自的页面中动态引入,不要全部都放到 index.html 中
比如echart.js,只有 A 页面使用,可以在 A 页面的钩子函数中动态加载,在onload事件中进行 echart 初始化
资源动态加载的代码示例
// url 要加载的资源
// isMustLoad 是否强制加载
cont asyncLoadJs = (url, isMustLoad = false) => {
return new Promise((resolve, reject) => {
if (!isMustLoad) {
let srcArr = document.getElementsByTagName("script");
let hasLoaded = false;
let aTemp = [];
for (let i = 0; i < srcArr.length; i++) {
// 判断当前js是否加载上
if (srcArr[i].src) {
aTemp.push(srcArr[i].src);
}
}
hasLoaded = aTemp.indexOf(url) > -1;
if (hasLoaded) {
resolve();
return;
}
}
let script = document.createElement("script");
script.type = "text/javascript";
script.src = url;
document.body.appendChild(script);
// 资源加载成功的回调
script.onload = () => {
resolve();
};
script.onerror = () => {
// reject();
};
});
}
方式三:import()
使用import() 动态加载路由和组件,对资源进行拆分,只有使用的时候才进行动态加载
// 路由懒加载
const Home = () => import(/* webpackChunkName: "home" */ '../views/home/index.vue')
const routes = [ { path: '/', name: 'home', component: Home} ]
// 组件懒加载
// 在visible属性为true时,动态去加载demoComponent组件
<demoComponent v-if="visible == true" />
components: {
demoComponent: () => import(/* webpackChunkName: "demoComponent" */ './demoComponent.vue')
},
5、合理利用缓存
html 资源设置协商缓存,其他 js、css、图片等资源设置强缓存
当用户再次打开页面时,html 先和服务器校验,如果该资源未变化,服务器返回 304,直接使用缓存的文件;若返回 200,则返回最新的 html 资源
6、网络方面的优化
1)开启服务器 Gzip 压缩,减少请求内容的体积,对文本类能压缩 60%以上
2)使用 HTTP2,接口解析速度快、多路复用、首部压缩等
3)减少 HTTP 请求,使用 url-loader,limit 限制图片大小,小图片转 base64
7、代码层面的优化
1)前端长列表渲染优化,分页 + 虚拟列表,长列表渲染的性能效率与用户体验成正比
2)图片的懒加载、图片的动态裁剪
特点是手机端项目,图片几乎不需要原图,使用七牛或阿里云的动态裁剪功能,可以将原本几M的大小裁剪成几k
3)动画的优化,动画可以使用绝对定位,让其脱离文档流,修改动画不造成主界面的影响
使用 GPU 硬件加速包括:transform 不为none、opacity、filter、will-change
4)函数的节流和防抖,减少接口的请求次数
5)使用骨架屏优化用户等待体验,可以根据不同路由配置不同的骨架
vue 项目推荐使用vue-skeleton-webpack-plugin,骨架屏原理将<div id="app"></div> 中的内容替换掉
6)大数据的渲染,如果数据不会变化,vue 项目可以使用Object.freeze()
Object.freeze()方法可以冻结一个对象,Vue 正常情况下,会将 data 中定义的是对象变成响应式,但如果判断对象的自身属性不可修改,就直接返回改对象,省去了递归遍历对象的时间与内存消耗
7)定时器和绑定的事件,在页面销毁时卸载
8、webpack 优化
提升构建速度或优化代码体积,推荐以下两篇文章
Webpack 优化——将你的构建效率提速翻倍[33]
带你深度解锁 Webpack 系列(优化篇)[34]
性能分析总结
1)先用 Lighthouse 得到当前页面的性能得分,了解页面的整体情况,重点关注 Opportunities 优化建议和 Diagnostics 诊断问题列表
2)通过 Performance 工具了解页面加载的整个过程,分析到底是资源加载慢、dom 渲染慢、还是 js 执行慢,找到具体的性能瓶颈在哪里,重点关注长任务(long task)
3)利用 Memory 工具,了解页面整体的内存使用情况,通过 JS 堆动态分配时间线,找到内存最高的时刻。结合具体的代码,去解决或优化内存变大的问题
前端监控
没有监控的项目,就是在“裸奔”
需要通过监控才能真正了解项目的整体情况,各项指标要通过大量的数据采集、数据分析,变得更有意义
监控的好处:事前预警和事后分析
事前预警:设置一个阈值,当监控的数据达到阈值时,通过各种渠道通知管理员和开发,提前避免可能会造成的宕机或崩溃
事后分析:通过监控日志文件,分析故障原因和故障发生点。从而做出修改,防止这种情况再次发生
我们可以使用市面上现有的工具,也可以自建 sentry 监控,关键在于通过这些数据,能看到这些冰冷数据背后的故事
组件库
组件库是开发项目时必备的工具,因为现在各个大厂提供的组件库都太好用了,反而让大家轻视了组件库的重要性
现在开发一个新项目,如果要求不能用现成的组件库,我估计要瞬间懵逼,无从下手了,不知不觉中,我已经患上严重的组件库依赖症
如果让我只能说出一种,快速提升编程技能的方法,我一定会推荐去看看组件库源码
因为组件库源码中,都是最经典的案例,是集大成的杰作
相比于前端框架源码的晦涩,组件库源码更容易上手,里边很多经典场景的写法,我们都可以借鉴,然后运用到实际的项目中
比如最常用的弹框组件,里边的流程控制、层级控制、组件间事件派发与广播、递归查找组件等设计,相当惊艳,真没想到一个小小的弹框组件,也是内有乾坤
推荐一下我正在写的ElementUI 源码-打造自己的组件库[35]文章,经典的东西永远是经典
总结
工程化,是一个非常容易出彩的方向,是展现一个侠者内功是否深厚的窗口
文中大部分知识点,只是入门级教程,也是我以后需要持续努力的方向