
2021最新爬虫教程.ppt



点击上方蓝字关注我们
爬虫框架就是一些爬虫项目的半成品,可以将些爬虫常用的功能写好。然后留下一些接口,在不同的爬虫项目当中,调用适合自己项目的接口,再编写少量的代码实现自己需要的功能。因为框架中已经实现了爬虫常用的功能,所以为开发人员节省了很多精力与时间。
Scrapy
Scrapy框架是一套比较成熟的Python爬虫框架,简单轻巧,并且非常方便。可以高效事的爬取 Web页面井从页面中提取结构化的数据。
重要的是Scrapy 是一套开源的框架,所以在使用时不需要担心收取费用的问题。
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。可以用它轻松的爬下来如亚马逊商品信息之类的数据。
Scrapy 的官网地址为:
https://scrapy.org/
Crawley
Crawley也是Python开发出的爬虫框架,该框架致力于改变人们从互联网中提取数据的方式Crawley的具体特性如下:
基于Eventlet构建的高速网络爬虫框架。
可以将数据存储在关系数据库中,例如,Postgres, Mysql. Oracle. Sqlite.
可以将爬取的数据导入为Json. XML格式。
支持非关系数据跨,例如,Mongodb 和Couchdb.
支持命令行工具。
可以使用喜欢的工具进行数据的提取,例如,XPath 或Pyquery工具。
支持使用Cookie登录或访问那些只有登录才可以访问的网页。
Crawley的官网地址:
http://project.crawley-cloud.com/PySpider
相对于Scrapy 框架而言,PySpider 框架是一支新秀。它采用Pyho语言编写,分布式架构,支持多 种数据库后端,强大的WebUl支持脚本编辑器、任务监视器、项目管理器以及结果查看器。PSpier 的具体特性如下:
Python 脚本控制,可以用任何你喜欢的html解析包(内置pyquery)。
Web界面编写调试脚本、起停脚本、监控执行状态、查看活动历史、获取结果产出。
支持MySQL、MongoDB、 Redis. SQLite、Elasticsearch, PostgreSQL与SQLAlchemy 。
支持RabbitMQ、Beanstalk、 Redis 和Kombu作为消息队列。
支持抓取JavaSeript的页面。
强大的调度控制,支持超时重爬及优先级设置。
专组件可替换,支持单机/分布式部署,支持Docker部署。
项目地址:
https://github.com/binux/pyspiderPortia
Portia是一个开源可视化爬虫工具,可让您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。

Newspaper
Newspaper可以用来提取新闻、文章和内容分析。使用多线程,支持10多种语言等。
Newspaper框架是Python爬虫框架中在GitHub上点赞排名第三的爬虫框架,适合抓取新闻网页。它的操作非常简单易学,即使对完全没了解过爬虫的初学者也非常的友好,简单学习就能轻易上手,因为使用它不需要考虑header、IP代理,也不需要考虑网页解析,网页源代码架构等问题。这个是它的优点,但也是它的缺点,不考虑这些会导致它访问网页时会有被直接拒绝的可能。
Newspaper功能如下:
多线程文章下载框架
新闻网址识别
从html中提取文本
从html中提取顶部图像
从html中提取所有图像
从文本中提取关键字
从文本中提取摘要
从文本中提取作者
Google趋势术语提取。
使用10种以上语言(英语,中文,德语,阿拉伯语......)
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。
与Scrapy不同的是Beautiful Soup并不是一个框架,而是一个模块;与Scrapy相比,bs4中间多了一道解析的过程(Scrapy是URL返回什么数据,程序就接受什么数据进行过滤),bs4则在接收数据和进行过滤之间多了一个解析的过程,根据解析器的不同,最终处理的数据也有所不同,加上这一步骤的优点是可以根据输入数据的不同进行针对性的解析;同一选择lxml解析器;
Beautiful Soup的查找数据的方法更加灵活方便,不但可以通过标签查找,还可以通过标签属性来查找,而且bs4还可以配合第三方的解析器,可以针对性的对网页进行解析,使得bs4威力更加强大,方便。
Grab爬虫框架
Grab是一个用于构建Web刮板的Python框架。借助Grab,您可以构建各种复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网络请求和处理接收到的内容,例如与HTML文档的DOM树进行交互。
Cola爬虫框架
Cola是一个分布式的爬虫框架,对于用户来说,只需编写几个特定的函数,而无需关注分布式运行的细节。任务会自动分配到多台机器上,整个过程对用户是透明的。
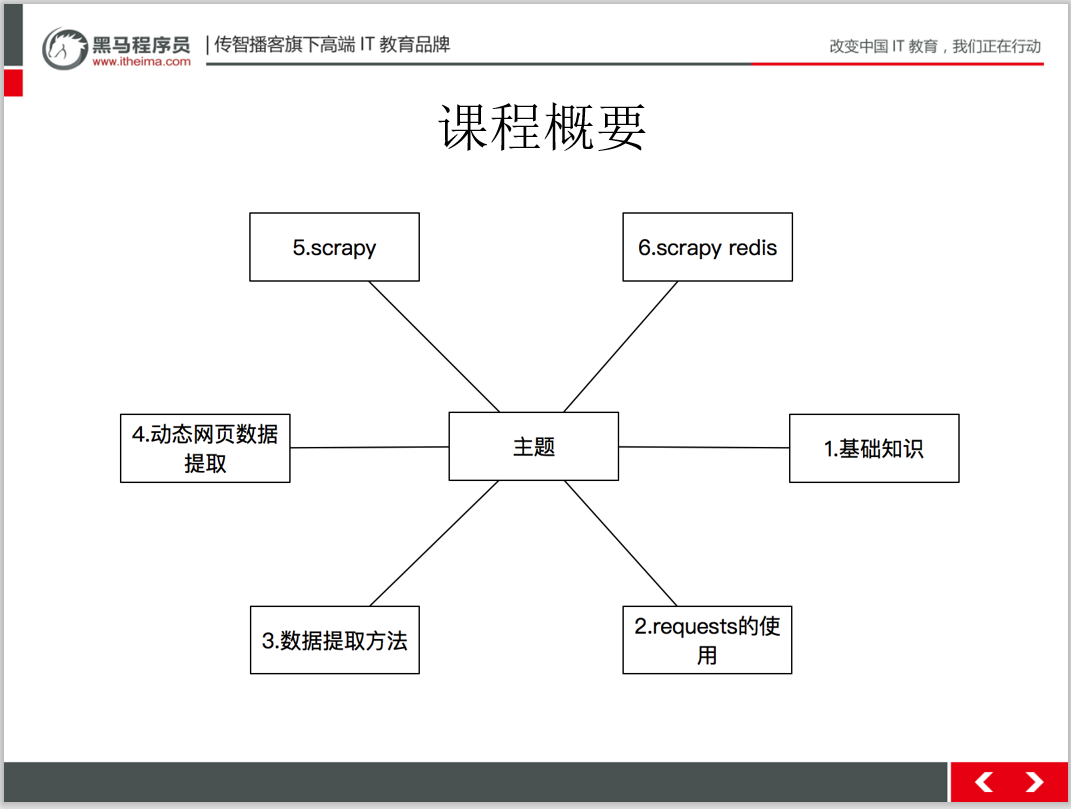
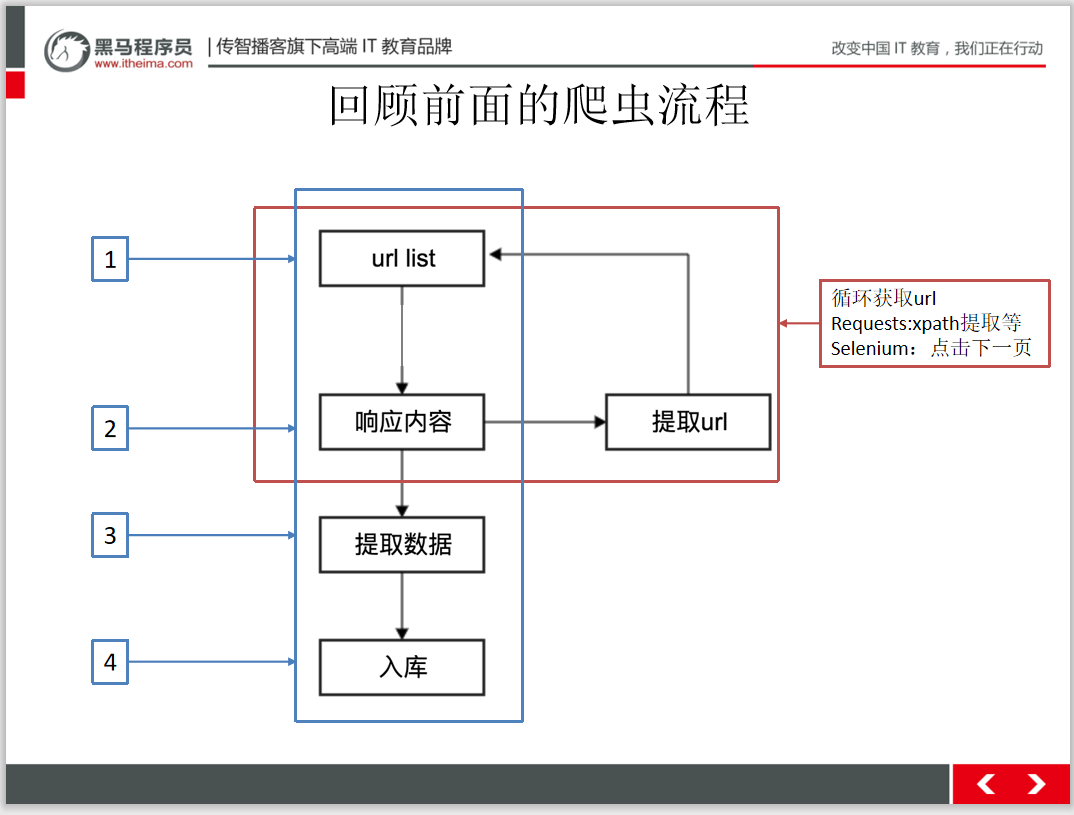
文末福利:
2021最新黑马程序员爬虫教程!
从最简答的html语法到进阶的scrap爬虫框架。新年福利。送送送!


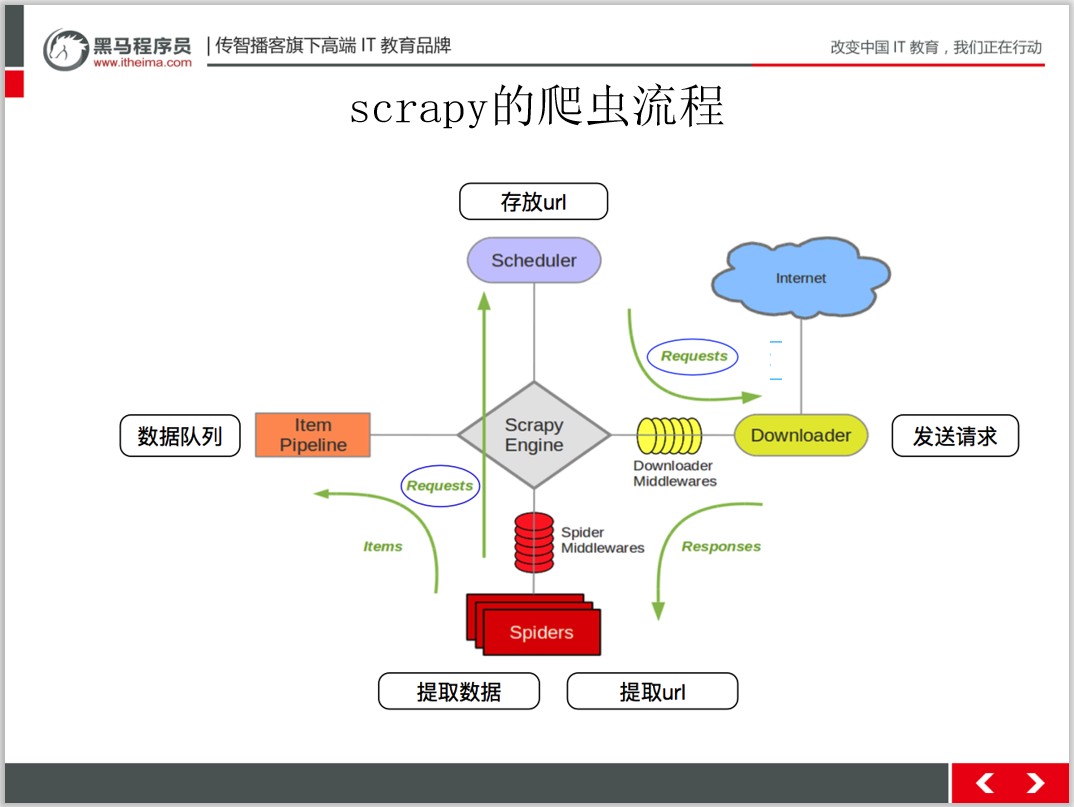
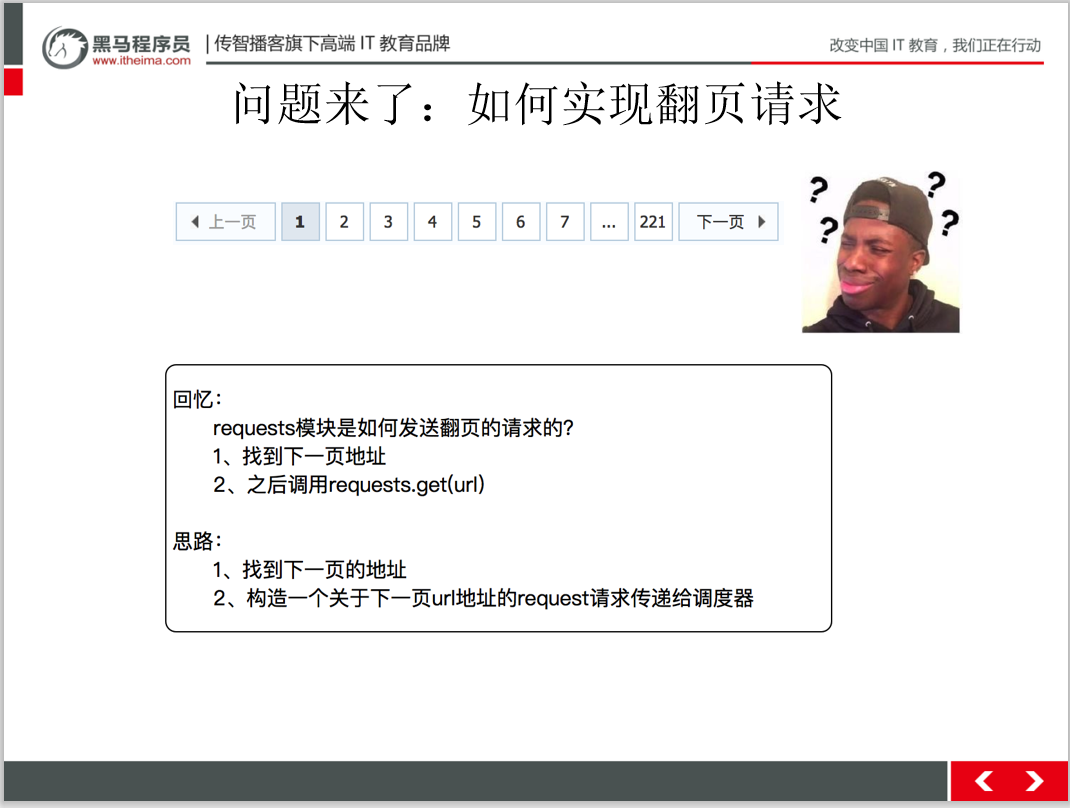
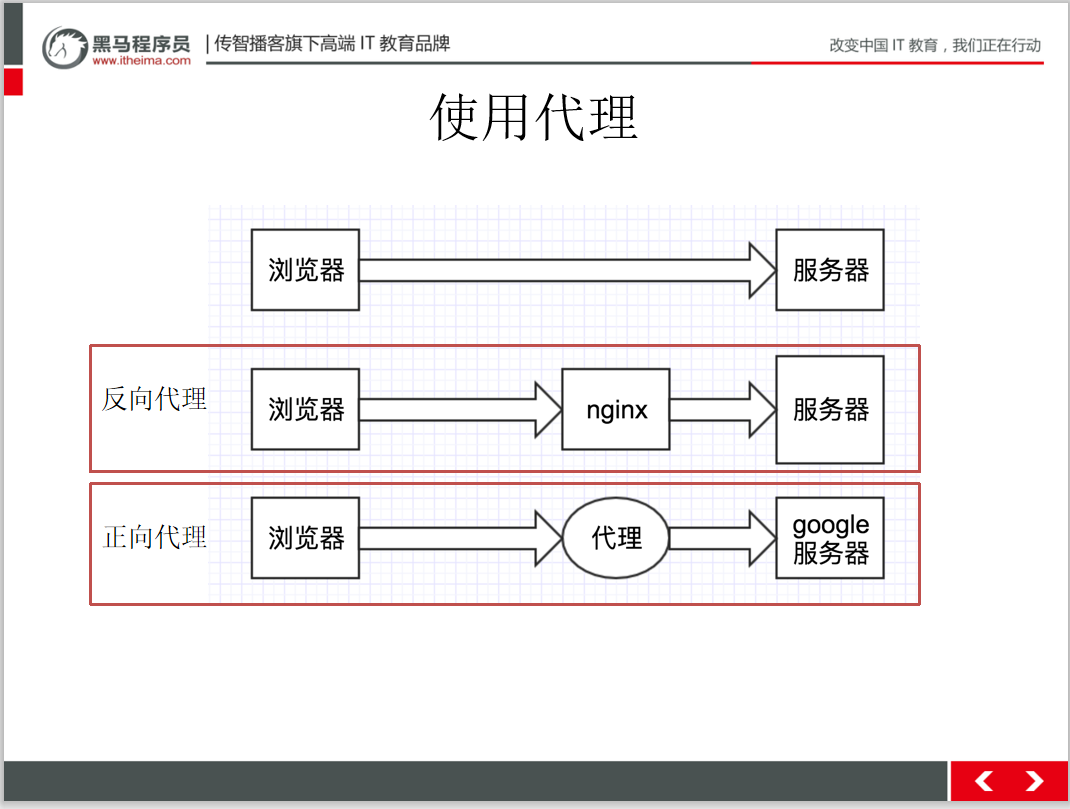
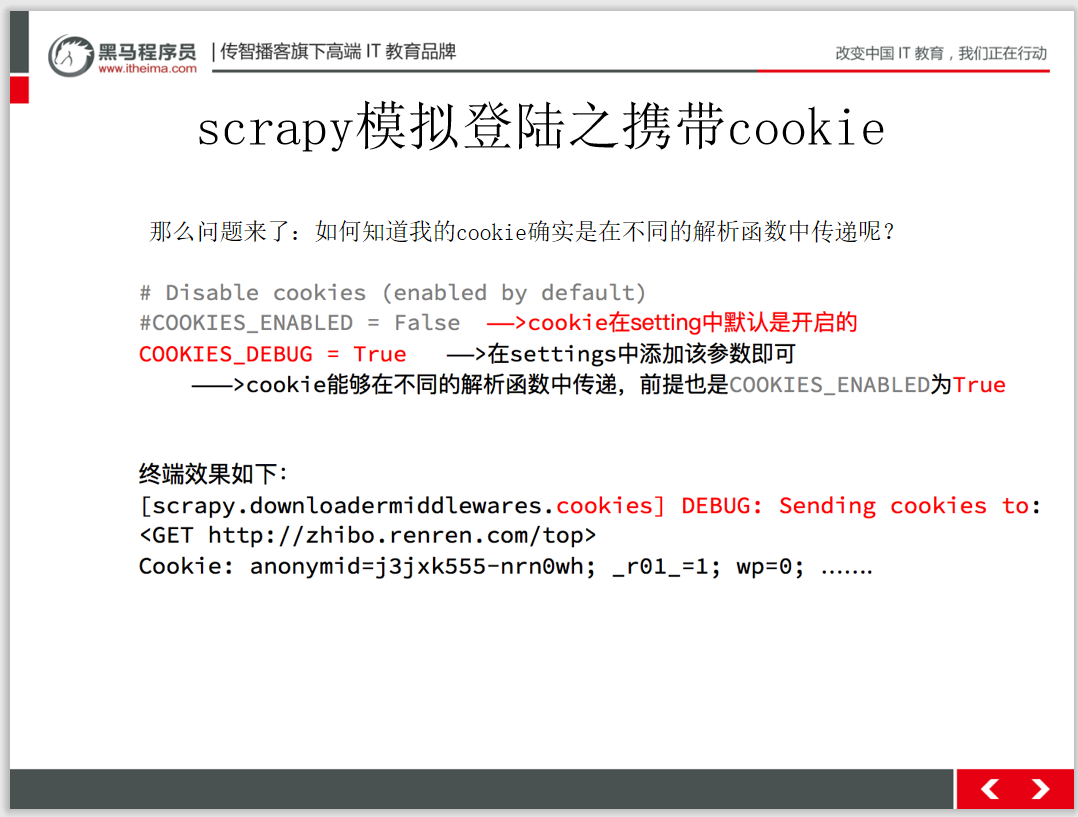
扫码回复‘爬虫教程’ 送你黑马程序员最新爬虫教程
扫描二维码
获取更多精彩
python学前班
福利仅此一天,欢迎扫码关注获取。后续福利更大!

点个在看你最好看