一个入门级python爬虫教程详解

这篇文章主要介绍了一个入门级python爬虫教程详解,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
前言
本文目的:根据本人的习惯与理解,用最简洁的表述,介绍爬虫的定义、组成部分、爬取流程,并讲解示例代码。
基础
爬虫的定义:定向抓取互联网内容(大部分为网页)、并进行自动化数据处理的程序。主要用于对松散的海量信息进行收集和结构化处理,为数据分析和挖掘提供原材料。
今日t条就是一只巨大的“爬虫”。
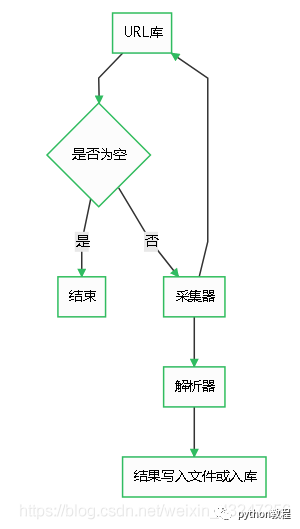
爬虫由URL库、采集器、解析器组成。
流程
如果待爬取的url库不为空,采集器会自动爬取相关内容,并将结果给到解析器,解析器提取目标内容后进行写入文件或入库等操作。
代码
第一步:写一个采集器
如下是一个比较简单的采集器函数。需要用到requests库。
首先,构造一个http的header,里面有浏览器和操作系统等信息。如果没有这个伪造的header,可能会被目标网站的WAF等防护设备识别为机器代码并干掉。
然后,用requests库的get方法获取url内容。如果http响应代码是200 ok,说明页面访问正常,将该函数返回值设置为文本形式的html代码内容。
如果响应代码不是200 ok,说明页面不能正常访问,将函数返回值设置为特殊字符串或代码。
第二步:解析器
解析器的作用是对采集器返回的html代码进行过滤筛选,提取需要的内容。
作为一个14年忠实用户,当然要用豆瓣举个栗子 _
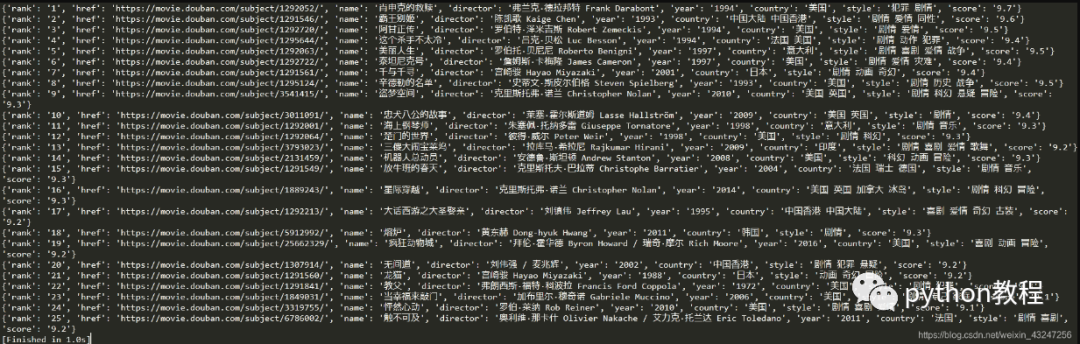
我们计划爬取豆瓣排名TOP250电影的8个参数:排名、电影url链接、电影名称、导演、上映年份、国家、影片类型、评分。整理成字典并写入文本文件。
待爬取的页面如下,每个页面包括25部电影,共计10个页面。
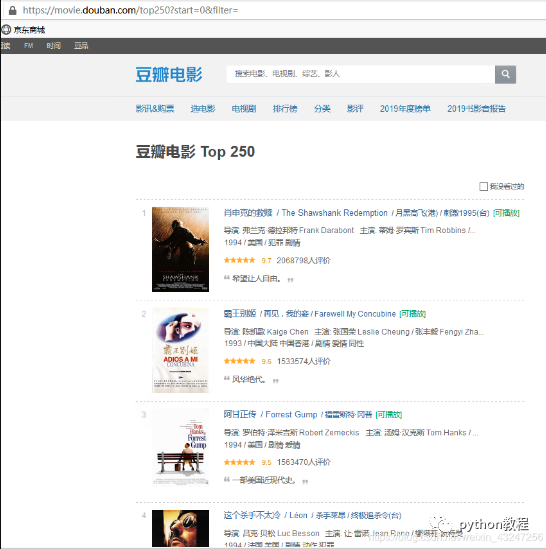
在这里,必须要表扬豆瓣的前端工程师们,html标签排版非常工整具有层次,非常便于信息提取。
下面是“肖申克的救赎”所对应的html代码:(需要提取的8个参数用红线标注)
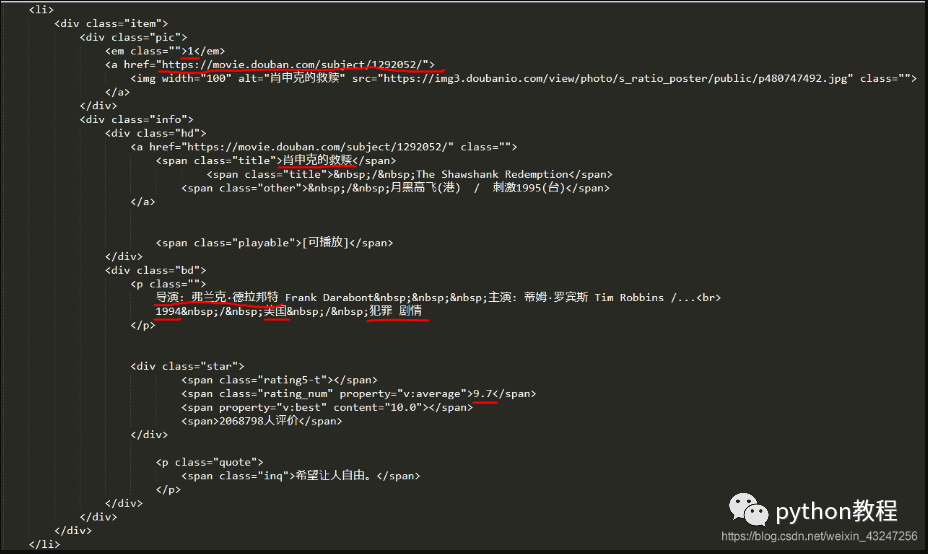
根据上面的html编写解析器函数,提取8个字段。该函数返回值是一个可迭代的序列。
我个人喜欢用re(正则表达式)提取内容。8个(.*?)分别对应需要提取的字段。