
如何正确读入文本数据不乱码(解决文本乱码问题)
大邓和他的Python
共 2688字,需浏览 6分钟
· 2022-11-22

乱码由来
相信大家使用Python读取txt、csv文件时,经常遇到UnicodeDecodeError错误,从字面意思看是 编码解码问题 。 关于编码解码相关知识推荐看B站柴知道制作的视频,了解
锟斤拷�⊠是怎样炼成的------中文显示"⼊"门指南【柴知道】
遇到乱码
在Python中,遇到文件读取乱码的可能性很大,例如
import pandas as pd
df = pd.read_csv('twitter_sentiment.csv')
df.head()
Run
c:\users\thunderhit\appdata\local\programs\python\python37-32\lib\site-packages\pandas\io\parsers.py in parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision)
...
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._tokenize_rows()
pandas\_libs\parsers.pyx in pandas._libs.parsers.raise_parser_error()
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbd in position 10717: illegal multibyte sequence
可以看到报错, 遇到 UnicodeDecodeError 问题
使用encoding参数
常见的解决办法是在函数内加入encoding参数,中文最常见的编码方式有gbk、gb2312、utf-8。
import pandas as pd
#这里依次试验gbk、gb2312、utf-8
df = pd.read_csv('twitter_sentiment.csv', encoding='utf-8')
df.head()
依然出现 UnicodeDecodeError 问题 。所以encoding遇到很不常见的编码方式。
获取encoding参数
先获取 twitter_sentiment.csv 文件的编码方式,再进行读取操作。
import chardet
#读取为二进制数据
binary_data = open('twitter_sentiment.csv', 'rb').read()
#传给chardet.detect,稍等片刻
chardet.detect(binary_data)
Run
{'encoding': 'Windows-1252', 'confidence': 0.7291192008535122, 'language': ''}
由此得知该文件的编码方式为 Windows-1252 , 重新更改即可成功读入数据
成功读取
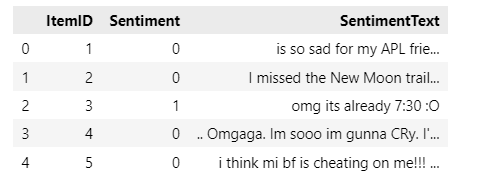
获取了正确的编码 encoding='Windows-1252', 就能正确的读入数据
import pandas as pd
#这里依次试验gbk、gb2312、utf-8
df = pd.read_csv('twitter_sentiment.csv', encoding='Windows-1252')
df.head()
Run
精选文章
27G数据集 | 使用Python对27G招股说明书进行文本分析
PNAS | 使用语义距离测量一个人的创新力(发散思维)得分
安装python包出现报错:Microsoft Visual 14.0 or greater is required. 怎么办?
R语言 | 使用posterdown包制作学术会议海报 R语言 | 使用ggsci包绘制sci风格图表
R语言 | 使用word2vec词向量模型
27G数据集 | 使用Python对27G招股说明书进行文本分析
PNAS | 使用语义距离测量一个人的创新力(发散思维)得分
安装python包出现报错:Microsoft Visual 14.0 or greater is required. 怎么办?
R语言 | 使用posterdown包制作学术会议海报 R语言 | 使用ggsci包绘制sci风格图表 R语言 | 使用word2vec词向量模型
R语言 | 将多个txt汇总到一个csv文件中
R语言 | 将多个txt汇总到一个csv文件中
评论
CVPR 2024|大视觉模型的开山之作!无需任何语言数据即可打造大视觉模型
↑ 点击蓝字 关注极市平台作者丨科技猛兽编辑丨极市平台极市导读 本文提出一种序列建模 (sequential modeling) 的方法,不使用任何语言数据,训练大视觉模型。>>加入极市CV技术交流群,走在计算机视觉的最前沿本文目录1 序列建模打造大视觉模型(来自 U
极市平台
1
偷偷告诉你如何一台电脑开多个微信!
大家好,我是轩辕。前几天在粉丝群里,有人问我是怎么在一台电脑上同时登录两个微信的?正好之前写过一篇文章,分析过原理,分享给没看过的小伙伴学习一下。手机端多开微信估计很多人都知道,像华为、小米等手机系统都对此做了支持,不过在运行Windows系统的电脑上怎么启动两个微信呢?其实很简单,你只需要写一个批
编程技术宇宙
0
测试新人,如何快速上手一个陌生的系统!
大家好,我是狂师!作为刚入行不久的测试新人,面对一个陌生的系统时,可能会感到有些手足无措。面对一个全新的系统系统,如何快速上手并展开有效的测试工作是一个重要的挑战。本文将探讨测试新人如何通过一系列步骤和策略,快速熟悉并掌握新系统的测试要点,从而提高测试效率和质量。本文旨在为测试新手提供一份指导,帮助
测试开发技术
0
光纤详解:光纤跳线如何分类,多向单模转换?
本文来自“光纤详解:光纤跳线如何分类,多向单模转换?”,光纤跳线作为光网络布线最基础的元件之一,被广泛应用于光纤链路的搭建中。如今,光纤制造商根据应用场景的不同推出众多类型的光纤跳线,如MPO/LC/SC/FC/ST光纤跳线,单工/双工光纤跳线,单模/多模光纤跳线等,它们之间各有特色,且不可替代。本
架构师技术联盟
0
如何计算数据中心的冷却需求?
今日分享 【导读】数据中心的冷却要求受多种因素影响,包括设备的热量输出、占地面积、设施设计和电气系统功率额定值等等……众所周知,环境因素会严重影响数据中心设备。过多的热量积聚会损坏服务器,可能导致其自动关闭。经常在高于可接受的温度下运行服务器会缩短其使用
数据中心运维管理
0
5000w+ 的大表如何拆?亿级别大表拆分实战复盘
前言笔者是在两年前接手公司的财务系统的开发和维护工作。在系统移交的初期,笔者和团队就发现,系统内有一张5000W+的大表。跟踪代码发现,该表是用于存储资金流水的表格,关联着众多功能点,同时也有众多的下游系统在使用这张表的数据。进一步的观察发现,这张表还在以每月600W+的数据持续增长,也就是说,不超
码农编程进阶笔记
0
如何做到无感刷新Token?
来源:juejin.cn/post/7316797749517631515为什么需要无感刷新Token?自动刷新token前端token续约疑问及思考图片为什么需要无感刷新Token?「最近浏览到一个文章里面的提问,是这样的:」当我在系统页面上做业务操作的时候会出现突然闪退的情况,然后跳转到登录页面
Java专栏
2
BigDecimal 为什么可以保证精度不丢失?
来源:juejin.cn/post/7348709938023940136👉 欢迎加入小哈的星球 ,你将获得: 专属的项目实战 / Java 学习路线 / 一对一提问 / 学习打卡 / 赠书福利全栈前后端分离博客项目 2.0 版本完结啦, 演示链接
小哈学Java
0