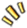如何快速判断一个用户是否访问过我们的 APP?
 背景
背景
牙哥所在部门是做广告系统的,所在小组主要做广告外投,即下图中 DSP 部分,当用户浏览媒体时,媒体通过 SSP 将曝光请求通过 ADX 发送给 DSP,DSP 通过 DMP 进行人群定向,对目标人群进行广告竞价,更好地为广告主带来收益
如何筛选优质流量是个难题,我们也在不断探索,现在想在程序入口让访问过我们 APP 的用户的这种流量(这种流量下面称作 RT 流量)优先通过筛选,但我们的程序入口 QPS 约 40w,且去重后的 RT 用户数是亿级别,假设 3 亿吧,用户信息是 32 位的字符串,如何快速判断一个用户是否访问过我们的 APP 呢?如果让你来设计,你打算怎么做?欢迎在留言区说出你的方案,和牙哥一起探讨
分析
判断一个对象是否存在一般可以采用哈希表的方式,检索的平均时间复杂度是 O(1),但是哈希表比较耗内存,3 亿个 32 字节的数据占用约 9G (32 byte * 3 亿/1024/1024/104)的内存,,所以这种方案不太适合我们的场景。
节省内存的方式有位图 BitMap 和布隆过滤器 BloomFilter 两种方式,其实 BloomFilter 是对 BitMap 的一种改进
先简单介绍下 BitMap
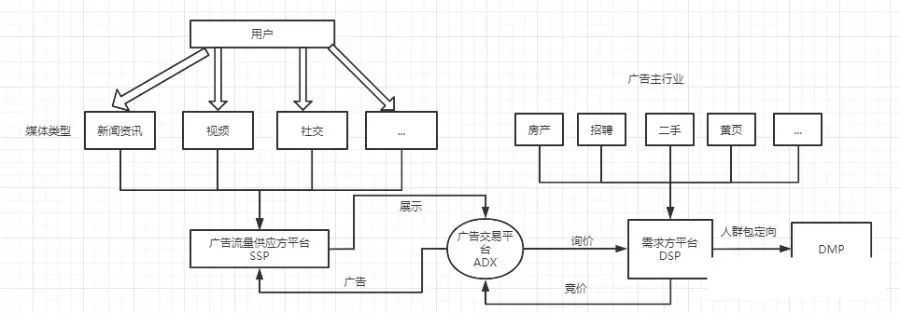
BitMap 是以 bit 为单位构建的数组,非常节省内存,假设用户的 ID 是 1,那么就把索引为 1 的 bit 数组置为 1,其余位置默认为 0,如下图所示
BitMap 通过数组下标来定位数据,Java 没有支持表示二进制数据的类型,可以通过 char 类型的数组通过或运算来达到目的,访问效率很快,检索的时间复杂度是 O(1)。但我们的数据不适合直接使用 BitMap ,原因如下:
BitMap 不适合数字范围过大,因为数组的长度必须大于 ID 的上限,如果数组范围是 3 亿,BitMap 的大小是 3 亿个二进制位,大约占用 36MB (3亿/8/1024/1024)左右的内存空间,注意这里假设 ID 是连续的,所以使用场景是是受限的
我们通过设备号来识别用户,并将设备号处理成 32 位的字符串,这显然不符合连续 ID 的假设,那想要使用 BitMap 该怎么做?
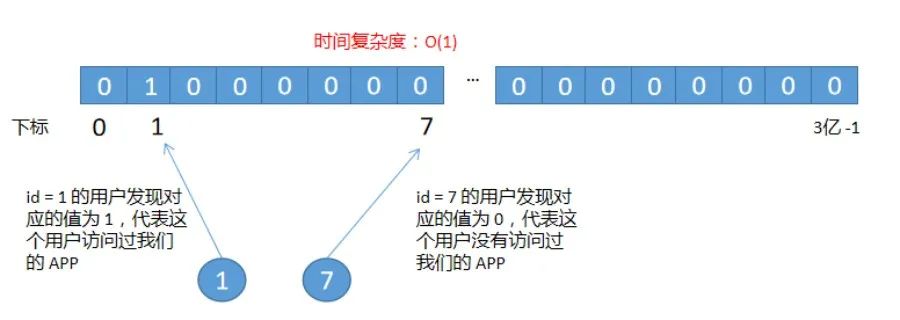
这就需要一个映射表来做支持,<设备号,ID>,映射表可以使用 Redis,在流量过来后,先根据设置号查询映射表拿到 ID,然后再从 BitMap 中判断用户是否存在,流程如下图所示:
现在我们再看下这个方案,既然已经在 Redis 中存储了映射信息了,那根据 ID 通过 BitMap 来判断是否存在貌似是多余的,因为如果映射表中存在,说明用户就存在呀,不需要再多做一个判断了,再改一版,直接把设备信息存到 Redis 中
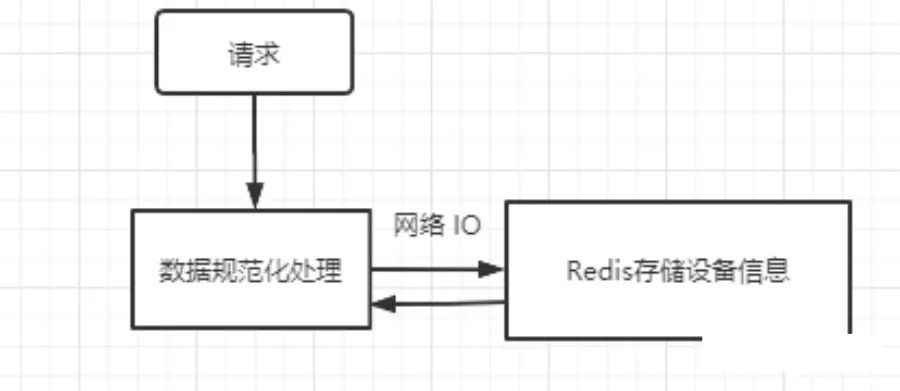
这种方案就是把占用的内存转移到了外部存储,这样 Redis 也占用内存呀,怎么办?
Redis 也是支持布隆过滤器的,不直接存储设备信息,改为用布隆过滤器(布隆过滤器原理后面聊)来存,可以节省内存
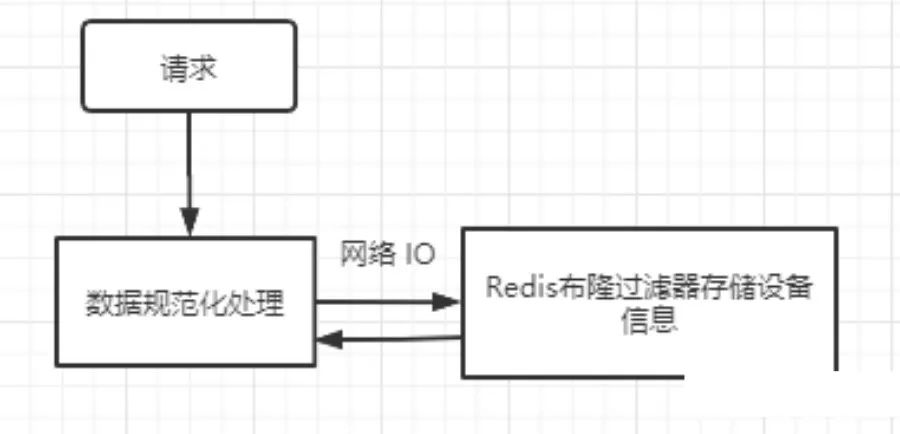
这种方案貌似可以解决我们的问题了,但是多了一次网络 IO,,我们的系统对响应时间要求高,所以带有网络IO的方式,也不太适合。那我们直接把网络 IO 去掉,直接在内存中使用布隆过滤器呢?
布隆过滤器原理
BloomFilter 是对 BitMap 的一种优化,我们知道数组占用空间 = 数组元素个数 * 每个元素大小,而 BitMap 已经将每个元素的大小压缩到最小单位 1 个 bit,还想继续优化只能减少数组元素的个数了。在前面分析 BitMap 时,我们知道它对 ID 的范围有限制,如果想减少数组元素的个数,可以通过哈希函数将大于数组长度的 ID 转换为小于数组长度的下标,这种方案还有一个优点就是不再限制 ID 是正整数,可以是字符串(这点非常重要),刚好我们的数据符合这个场景。
但是这样会存在冲突,假设 x 和 y 经过哈希函数计算后定位到同一个位置,那就不能判定到底是 x 还是 y 访问过我们的 APP 了
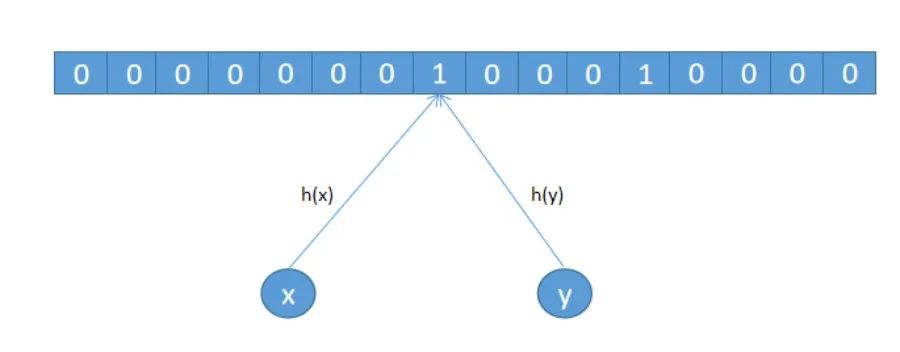
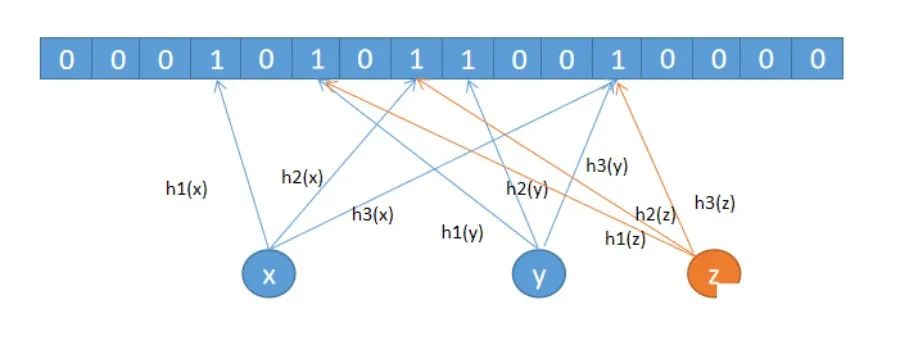
散列表解决哈希冲突有两种常用方法:开放寻址法和链表法,链表法你应该知道,HashMap 就是用的这种方案。开放寻址法中有个优化方案叫”双散列“,说白了就是用多个哈希函数来解决哈希冲突问题。布隆过滤器就是利用的这种多个哈希函数来解决哈希冲突的。如下图所示,使用了 3 个哈希哈数,会计算 3 个下标,会把下标对应的位置置为 1,这也是布隆过滤器和 BitMap 的最大区别,即在 bit 数组中用多个位来表示对象,而不是用 1 个位来表示,从而来降低冲突
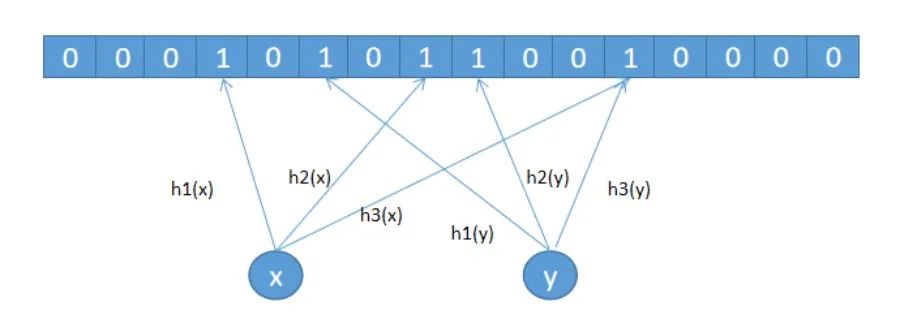
虽然用多个位来表示对象可以降低哈希冲突,但还是会存在冲突的,即布隆过滤器是存在误判率的,如下图所示,假设用户 z 并未访问过 APP,但他的设备号经过 3 次哈希计算对应的位置都已经置为 1 了,所以会产生误判,但因为我们的业务场景并不要求准确率是 100%,只是希望把访问过 APP 的用户的流量快速的放进系统,即使误判也没有影响,所以布隆过滤器的误判率的存在,符合我们的业务场景。
实现方案
业务场景和布隆过滤器介绍完了,下面看看如何实现吧,已经有很多开源框架实现了布隆过滤器,可以拿来直接使用,不需要再重复造轮子了,我采用的是 Guava 的 BloomFilter ,创建 BloomFilter 对象时,传入误判率(默认的是 0.03)和预估数据量(亿级别),使用方法如下:
// 创建 BloomFilter
BloomFilter bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), expectedNum, fpp);
// 写数据
bloomFilter.put("1");
// 读数据
boolean result = bloomFilter.mightContain("1");
Guava 的 BloomFilter 使用起来还是蛮方便的,但我想介绍下 BloomFilter 涉及到的两个比较重要的公式
// 根据预估数据量 n 和 误判率 fpp 计算bit数组
// m = -n*ln(fpp)/(log2)^2
long m = (long) (-expectedNum * Math.log(fpp) / (Math.log(2) * Math.log(2)));
// 根据预估数据量 n 和 bit 数组长度 m 计算哈希函数的个数 k = m/n * ln2
int k = Math.max(1, (int) Math.round((double)m / expectedNum * Math.log(2)));
// BloomFilter 使用 long 型数组
int longNum = Ints.checkedCast(LongMath.divide(m, 64, RoundingMode.CEILING));
根据公式对不同数据量占用的内存做了估算,因为做方案设计时要考虑内存占用情况
long expectedNum = 500_000_000;
double fpp = 0.03d;
System.out.println("预估数据量 :" + expectedNum + "\n误判率:" + fpp);
// 根据预估数据量 n 和 误判率 fpp 计算bit数组
// m = -n*ln(fpp)/(log2)^2
long m = (long) (-expectedNum * Math.log(fpp) / (Math.log(2) * Math.log(2)));
System.out.println("bit数组长度:" + m);
// 根据预估数据量 n 和 bit 数组长度 m 计算哈希函数的个数 k = m/n * ln2
System.out.println("哈希函数个数:" + Math.max(1, (int) Math.round((double)m / expectedNum * Math.log(2))));
// BloomFilter 使用 long 型数组
int longNum = Ints.checkedCast(LongMath.divide(m, 64, RoundingMode.CEILING));
System.out.println("long数组大小:" + longNum);
int size = longNum * 8 / 1024 / 1024;
System.out.println("内存占用大小:" + size);
结果
误判率采用默认的 0.03
按 10 亿的数据算,bit 数组长度是 7298440837,BloomFilter 使用long型数组,所以long型数组长度 114038139 ,内存占用约 870 MB
按 5 亿的数据算,bit 数组长度是 3649220418,BloomFilter 使用long型数组,所以long型数组长度 57019070 ,内存占用约 435 MB
按 3 亿的数据算,bit 数组长度是 2189532251,BloomFilter 使用long型数组,所以long型数组长度 34211442 ,内存占用约 261 MB
按 2 亿的数据算,bit 数组长度是 1459688167,BloomFilter 使用long型数组,所以long型数组长度 22807628 ,内存占用约 174 MB
我们的 RT 数据预计 3 亿,在默认误判率的情况下,占用内存在 261MB ,服务器现有配置可以满足
注意
这里发现使用了 BloomFilter 后占用的内存竟然比直接使用 BitMap 耗费内存更多,好像和常识相反。其实使用 BitMap 时假设了是连续的 ID,紧凑的 BitMap 是最省空间的,连续的 Id 对 BitMap 来说是没有任何空间浪费的,所以这种情况下 BloomFilter 占用的内存高于 BitMap
首先介绍下文中涉及到的两个项目,一个是 delivery 是我们的广告检索入口,流量非常大,对性能要求高,另一个是 dsp_jar_task,和定时任务相关
然后看下整体方案:
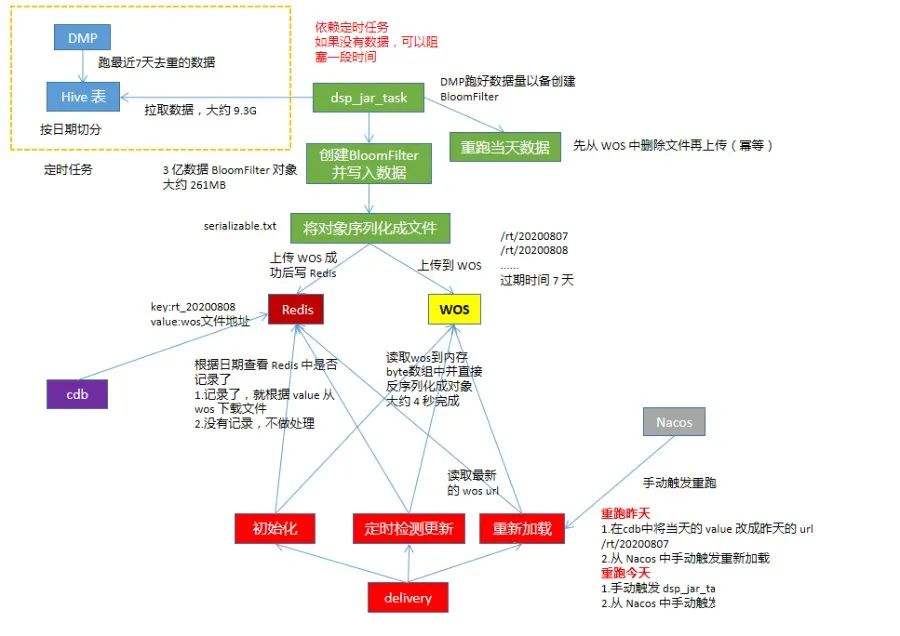
流程介绍
我们的 RT 数据每天通过定时任务跑完数后存放到 HDFS 上,考虑到从 HDFS 中读取数据,并创建对象耗时比较长,所以把这部分工作从 delivery 移到 dsp_jar_task 上,在 dsp_jar_task 读取数据并创建好 BloomFilter 后,将对象序列化到文件中,先保存在本地,然后将文件上传到 WOS (公司内部的一个对象存储组件),存储到 WOS 成功后,会返回一个 url 地址,根据该地址可以访问存储的对象,把记录写到 Redis 中,格式如:
delivery 初始化时,先根据前一天日期从 Redis 中查是否有写入 WOS,如果昨天没有则取前天的,有就取昨天的。从 WOS 读取数据到内存中,存放到 byte 数组中,然后反序列化成 BloomFilter 对象,成功后,在内存中记录本地的模型日期,供定时检查模型更新对比使用,delivery 启动后会起定时任务每隔 10 分钟去检查 Redis 中的模型和内存的模型是否相同
如果相同,不做处理
如果不同,则根据 Redis 中最新的模型 url 去 WOS 读取最新的模型
回滚操作
为了应对模型数据存在问题的 case,要支持回滚操作。回滚操作主要分为两种,一种是回滚到昨天的模型,另一种是重跑今天的模型
回滚到昨天的模型
首先,昨天的模型一定是正常的,然后通过在 cdb 平台手动更新 Redis 数据,将 key = rt_20200007 的 value 改成昨天的 WOS url
然后在 Nacos 中触发重新加载模型操作
重跑今天的模型
可能当天的任务跑的数据有问题,需要提供 RT 数据的定时任务重新跑数据,跑完后,手动触发 dsp_jar_task 执行重跑任务,需要先删除当天的数据,然后再重新拉取数据并上传,这里是个幂等的操作。上传成功后,在 Nacos 中触发重新加载模型的操作
效果和规划
该方案上线后,业务相关的效果数据很明显,但现在只有离线数据,后续可能会考虑加入实时数据
2020-08-09

2020-08-09

2020-08-07