
ACCV2020国际细粒度识别比赛季军方案解读及Tricks汇总
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
一、大赛介绍及挑战
1.1 背景
本次比赛,是由南京理工大学、英国爱丁堡大学、南京大学、阿德莱德大学、日本早稻田大学等研究机构主办,极市平台提供技术支持的国际性赛事,数据集总共包含了55w训练数据(120G),10w测试数据,数据均来自于网上,包含大量的动物和植物,总计5000个类别。
大赛官网链接:https://www.cvmart.net/race。

5000个类别中某一类别图片示例
1.2 挑战
经过初步实验和对数据集的可视化,我们发现本次比赛主要存在有以下挑战:
55万的训练数据集中存在有大量的噪声数据
训练集中存在较多的图片标签错误
训练集与测试集不属于同一分布,且存在较大差异
训练集各类别图片数量呈长尾分布
细粒度挑战,类间差异小
基于这些挑战以及经过多轮实验,我们的解决方案如下。
二、解决方案
1、数据清洗
为解决数据中存在的问题,我们依次分如下四步对数据进行清洗。
1.1清洗噪声数据
噪声数据是指非动植物的图片,通过查看数据发现,训练集中包含大量如下这种噪声数据。
清洗方案:
1)从1万张非三通道图片中人工挑出1000张左右的噪声图片 和 7000张左右正常图片,训练二分类噪声数据识别模型。
2)使用1中的二分类模型预测全量50万训练数据,挑选出阈值大于0.9的噪声数据。
3)使用2中噪声数据迭代 1、2过程,完成噪声数据清洗。人工检查,清洗后的训练样本中噪声数据占比小于1%。
1.2清洗粗粒度标签错误数据
本次竞赛5000类别中,仍有较多的属于两个不同细粒度的图片具有相同标签。如下图的人物合影、荒草都和青蛙属于同一标签。

清洗方案:
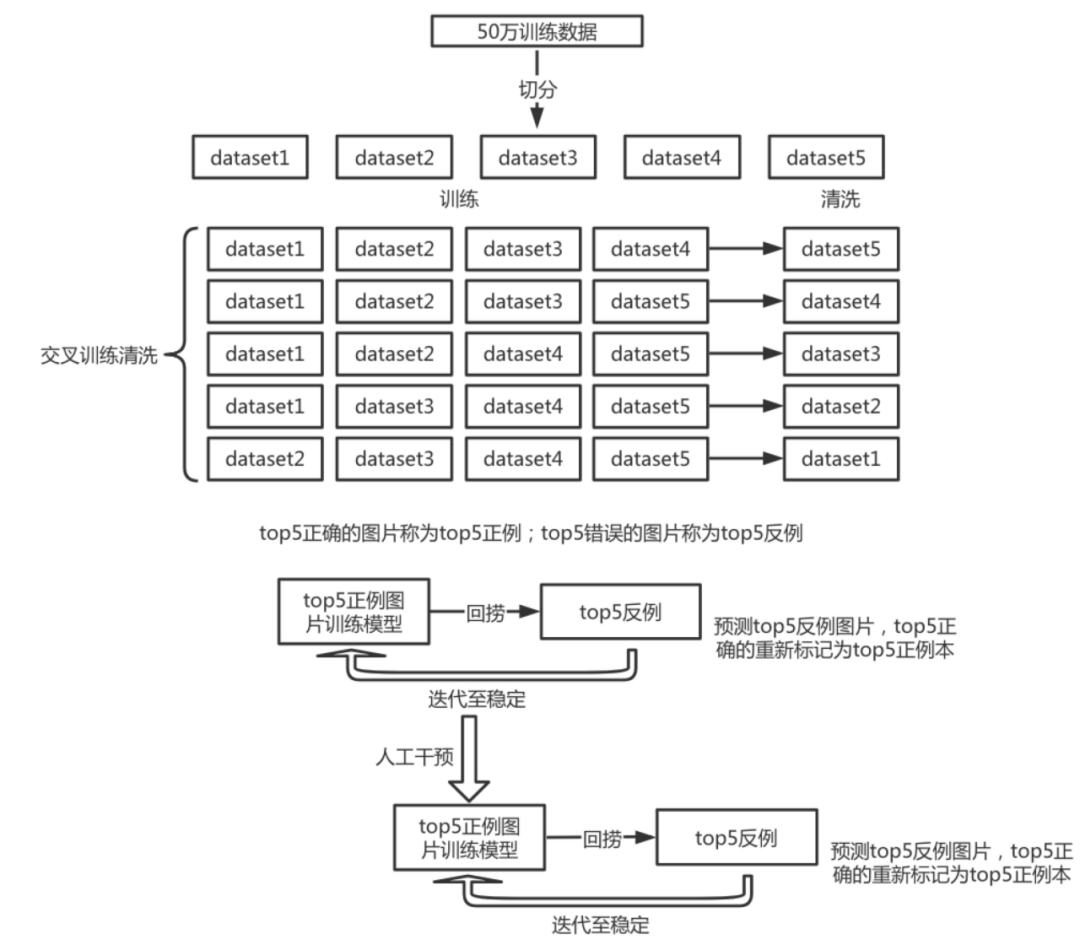
1)交叉训练,将50万训练集拆成五分,每4分当训练集,一份当测试集,训练5个模型。
2)将训练好的模型分别对各自测试集进行预测,将测试集top5正确的数据归为正例,top5错误的数据归为反例。
3)收集正例数据,重新训练模型,对反例数据进行预测,反例数据中top5正确的数据拉回放入训练集。
4)使用不同的优化方案、数据增强反复迭代步骤3直至稳定(没有新的正例数据产出)。
5)人工干预:从反例数据中拉回5%-10%左右的数据,人工check,挑选出正例数据放入训练集
6)重复3、4步骤。
1.3清洗细粒度标签错误数据
细粒度类别标签错误数据如下所示,红色箭头标识的图片与其他三张图片不属于同一类别,却具有相同标签。

清洗方案:
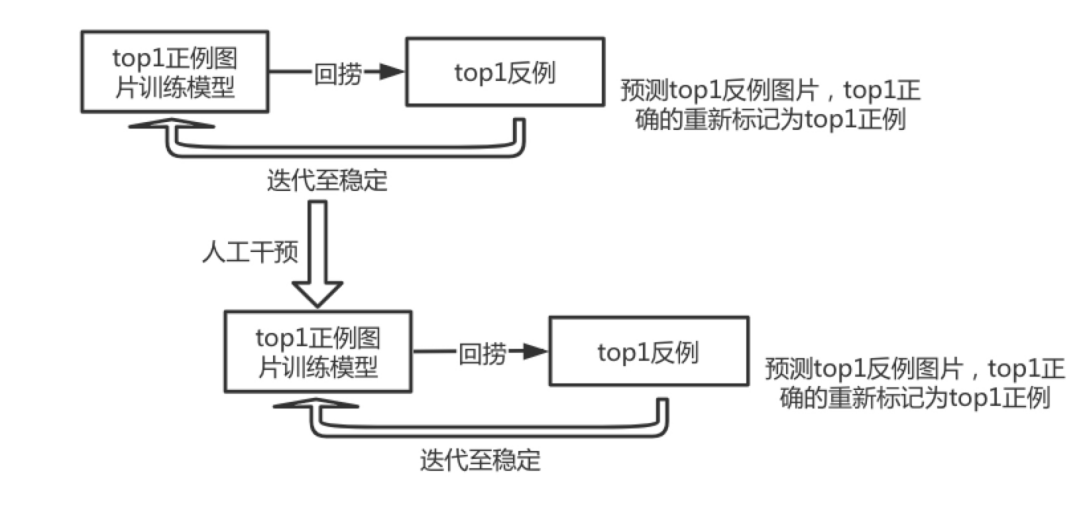
1)交叉训练,将清洗粗粒度错误标签后的训练集拆成五分,每4分当训练集,一份当测试集,训练5个模型。
2)将训练好的模型分别对各自测试集进行预测,将测试集top1正确的数据归为正例,top1错误的数据归为反例。
3)收集正例数据,重新训练模型,对反例数据进行预测,反例数据中top1正确的数据拉回放入训练集
4)使用不同的优化方案、数据增强反复迭代步骤3直至稳定(没有新的正例数据产出)。
5)人工干预:从反例数据中拉回5%-10%左右的数据,人工check,挑选出正例数据放入训练集
6)重复3、4步骤。
1.4清除低质量类别
在数据集的5000个类别中,人工看了图片数量少于50的类别,剔除其中图片混乱,无法确认此类别的具体标签。

无法确认具体标签的类别
2、数据增强
训练集与测试集属于不同分布,为使模型能更好的泛化测试集,以及捕捉局部细节特征区分细粒度类别,我们采用如下数据增强组合:
mixcut
随机颜色抖动
随机方向—镜像翻转;4方向随机旋转
随机质量—resize150~190,再放大到380;随机jpeg低质量有损压缩

随机缩放贴图

图片随机网格打乱重组

随机crop
3、数据均衡
5000个类别的训练数据呈长尾分布,直接训练会使得图片数量少的类别识别精度不高,在比赛中,我们采取的两种解决方案如下:
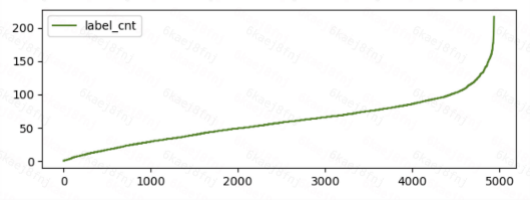
上采样数据均衡,每类数据采样至不少于最大类别图片数量的三分之一。
统计训练数据各类别概率分布,求log后初始化fc层偏置,并在训练过程中不更新fc层偏置。参考论文:Long-tail learning via logit adjustment
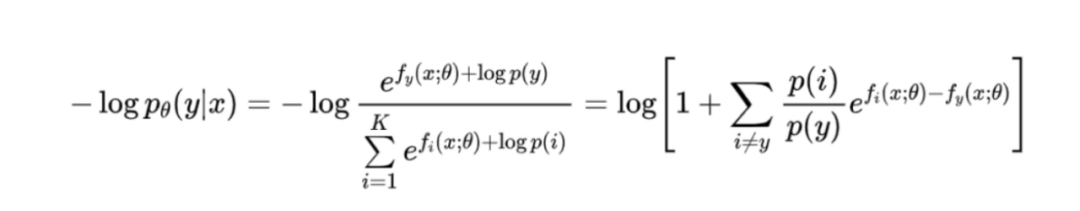
4、Backbones
在模型选型上,我们没有做较多的尝试,只使用了如下backbones:
EfficientNet-b4
EfficientNet-b5
5、优化
在模型优化方面,我们使用radam+sgd优化器,以及大的batch size训练(我们在实验中发现,使用大batch size比小batch size收敛更快,测试集精度更高) ,具体参数如下:
label smooth 0.2
base_lr=0.03
radam+sgd
cosine scheduler
分布式超大batch size(25*80=2000)训练
6、知识蒸馏—Knowledge Distillation
加上知识蒸馏,可以使我们的模型精度提升约1%:
50+w训练集加20w测试集 ,纯模型蒸馏,采用KLDivLoss 损失函数
50+w训练集,模型蒸馏(KLDivLoss)*0.5 +标签(CrossEntropyLoss)* 0.5
7、Ensemble
通过选取不同版本的数据集,以及以上不同的数据增强、数据均衡、蒸馏方法和模型结构,训练多个模型
取多个(8个)模型fc前一层特征,concat在一起训练一个fc层,训练过程中加随机数据增强
取多个(4个)模型fc前一层特征,concat在一起训练一个fc层,训练过程的数据处理与预测保持一致
取多个(15、9、8、6)模型的softmax,求平均
用以上多个ensemble模型结果投票作为最终结果
8、Tricks
在预测测试集标签时,相比训练,中心crop出更小的尺寸。
训练:resize(img_size*1.15)+randomcrop(img_size);
测试:resize(img_size*1.35)+centercrop(img_size)
根据10万验证集,5000类,每类只有20张图片的先验,提交结果时,根据预测分值排序,每个类别最多只选取top25的预测,平衡后的提交可以提高0.5~1%精度。
三、总结
a、能work的模块贡献
数据清洗 | ~47% → ~58% |
数据增强 | +3%-4% |
数据均衡 | +0.5%-1% |
蒸馏 | +~1% |
优化(大 batch size) | +~1% |
Tricks | +~1.5% |
b、不能work的尝试
自监督训练backbone | 降点 |
focal loss | 无提升 |
先分大类,再分小类 | 无提升 |
c、最终提交结果
15个单模型 A榜精度 | 15个单模型ensemble A榜精度 |
~62%-65% | 67.818% |
d、未完成验证但有初步效果尝试
在ensemble实验中,多模型之间特征高度冗余,可以利用1维卷积合并相关冗余特征,突出差异特征的特征占比,再加一个bn增强泛化性。该方案初步实验有效,但由于比赛截止,未进行进一步实验。
ensemble特征方式 | 5模型融合精度 |
多模型fc前一层concat后直接5000类别fc预测 | 62% |
多模型fc前一层concat后接1维卷积(kernel=5,channel缩小一半)+1维bn+5000类别fc预测 | 62.88% |
团队介绍:

团队成员均来自滴滴出行-安全产品技术部算法团队(DiDi-SSTG),团队成员分别为:王智恒、薛韬略、井海鹏、张明文、张天明
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:leetcode 开源书
在「AI算法与图像处理」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!
下载3 CVPR2020
在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称

觉得不错就点亮在看吧
