长尾识别中的Tricks汇总|AAAI2021

极市导读
本文对长尾识别中常用的“技巧”进行了收集并进行了充分而系统的实验以给出一份详尽的实验手册,同时得到了相关“技巧”的一种有效组合。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

注:该文已被AAAI2021接收。南京大学&南理工&旷视科技的研究员针对长尾识别问题中“技巧”进行了系统的探索,对相关“技巧”的组合进行了科学的实验对比,与此同时提出了一种基于CAM的re-sampling方案,最后输出了一组最佳“技巧大礼包”并在四个公开数据集上验证了其性能,相比已有方案,所提“技巧大礼包”取得10%的误差率下降,这对于该领域的未来研究提供了一份很有价值的参考手册。
Abstract
近年来,基于深度学习的方法在长尾分布(类别不平衡)数据上取得了极大进展。除了这些复杂的方法外,训练过程中的那些简单“技巧”(比如数据分布、损失函数的调整)同样起着不小的贡献。然而,不同的“技巧”之间可能存在“冲突”。如果采用了不合理的“技巧”进行长尾相关的任务,这就很可能导致较差的识别精度。不幸的是,关于这些“技巧”并无科学系统的手册供参考。
鉴于此,该文对长尾识别中常用的“技巧”进行了收集并进行了充分而系统的实验以给出一份详尽的实验手册,同时得到了相关“技巧”的一种有效组合。更进一步,作者还提出了一种基于CAM(Class Activation Maps)的数据增广方案,所提方案可以与re-sampling方法友好组合并取得更好效果。
通过科学的组合这些“技巧”,该文在四个长尾基准数据集(包含ImageNet-LT、INaturalist2018)上取得了优于SOTA方案的结果。该文的主要贡献包含以下几点:
系统地探索了现有简单、超参不敏感的长尾相关“技巧”,为后续研究提供了一份有价值的实践手册; 提出了一种基于CAM的适用于两阶段的采样方案,所提方案简单有效; 进行了充分的实验并得到了一组最优组合,所提组合方案在四个长尾公开数据集取得了SOTA结果。
Datasets and baseline settings
在这部分内容中,我们将介绍一下该文所用到的数据集、训练配置、骨干网络、数据增广等相关信息。
Datasets
Long-tailed CIFAR 长尾版的CIFAR10与CIFAR100是长尾识别的基准数据集,它们通过按照指数函数(t表示类别索引)减少每类训练样本得到;而测试集保持不变。CIFAR的不平衡因子表示为最大类别数除以最小类别数,范围为10~200,其中50和100为最为广泛采用者。
iNaturalist 2018 它是一种大尺度真实数据,存在严重类别不平衡问题。它包含437513张图像,类别数为8142;除了类别不平衡外,它同样面临着细粒度问题。
Long-tailed ImageNet 它是从原始的ImageNet12按照Pareto分布采样得到,最多的类别具有1280图像,而最少的仅有5张。
Baseline settings
Backbones 该文采用ResNet作为骨干网络,其中ResNet32用于长尾CIFAR,ResNet50用于iNaturalist,ResNet10用于ImageNet-LT。
Data augmentation 对于长尾CIFAR,作者采用了ResNet中的数据增广方案,每个图像进行4个像素pad,随机crop、随机水平镜像,最后进行标准化;在验证阶段,短边resize到36,然后进行CenterCrop,最后进行标准化。对于iNaturalist2018与ImageNet-LT,在训练过程中,采用scale进行增广到256,然后随机crop得到224x224的图像,最后进行标准化;在验证结果,短边resize到256,然后进行CenterCrop,最后进行标准化。
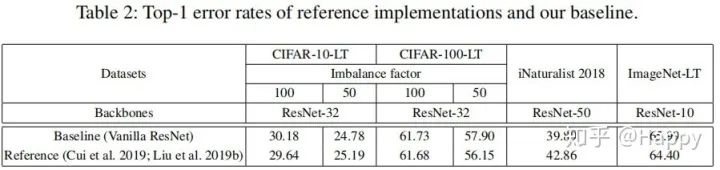
Training Detail 所有的骨干网络从头开始训练,采用kaiming初始化。对于长尾CIFAR,ResNet32的优化为为SGD(momentum=0.9, weight_decay=0.0002),合计训练200epoch,batch=128,初始学习率为0.1,在60和180epoch时衰减0.01,在前5个epoch采用了warmup。对于iNaturalist2018和ImageNet-LT,batch=512,合计训练90epoch,初始学习率为0.2,在30、60、80epoch时衰减0.1,优化器为SGD(momentum=0.9, weight_decay=0.0001). 下表给出了上述基准配置下的模型性能。
Trick gallery
作者将长尾相关的“技巧”划分为四大类:(1)re-weighting;(2)re-sampling;(3)mixup training;(4)two-stage training。这是因为作者发现:当与re-sampling相结合时,mixup training可以在长尾识别任务中得到好的识别精度,故而作者在这里把mixup training纳入到“技巧”大礼包中。
与此同时,作者还针对two-stage training提供了一种简单而有效的数据增广方案,它在CAM的基础上得到,故将其与re-sampling称之为“CAM-based sampling”。
Re-weighting methods
代价敏感重加权方法是长尾研究中常用方案之一,通过对不同的类别赋予不同的权重,这类方案将引导网络对于数目较少的类别添加更多的关注。
假设图像的类别为,其预测输出为,定义为类别c的样本数,为最少类别的样本数。Softmax交叉熵损失作为对标的基准,定义如下:
Existing re-weighting methods 接下来,我们对常用的代价敏感重加权方法进行简单的汇总。
Cost-sensitive softmax cross-entropy loss(CS-CE)定义如下:
Focal loss则是sigmoid交叉熵损失的基础上添加了调节因子以更聚焦困难样本,定义如下:
其中,表示用于控制不同样本重要性的超参数。
Class-balanced loss 考虑了不同类别的真实容量,即有效数量,而非数据集中的样本数量。通过引入有效数量,该损失函数定义如下:
其中,为超参数。
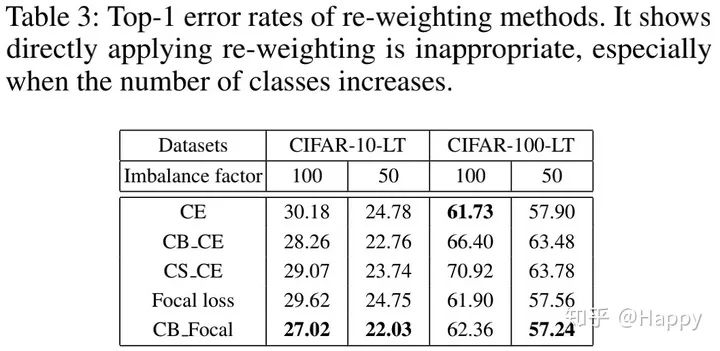
上表给出了不同re-weighting方法在长尾CIFAR数据集上的性能对比。可以看到:在CIFAR10-LT数据集上,该方法可以取得更低的误差;而在CIFAR100-LT上,该方法的结果反而变差。这就意味着:当类别数提升不平衡进一步加剧时,直接在训练阶段实施re-weighting并非合理的选择。
Re-sampling methods
re-sampling同样是长尾研究中常用的一种方法,它尝试对数据进行重采样使其达到均匀分布。在这里,我们将对现有的简单而常用的re-sampling方法进行汇总。
Random over-sampling 是一种极具代表性的re-sampling方法,它对数量较少的类别通过复制的方式进行采样。这种方案简单有效,但可能导致过拟合。 Random under-sampling 随机移除了数量较多的类别中的部分数据直到所有类别数变得均衡。已有研究表明:在某些情况下,欠采样比过采样更可取。 Class-balanced sampling 使得每个类别具有相同的概率被选择。该方法先均匀的进行类别采样,然后再进行样本的均匀采样。一般来说,每个类别的采样公式可以定义如下:
而在该方法中。当q=1时表示常规意义上的数据采样,数量多的类别采样概率更高。
Square-root sampling 则是上述采样公式的特例,旨在返回一个 lighter不平衡数据。Progressively-balanced sampling 提出渐进的改变类别采样概率,即从类别不平衡采样到类别平衡采样的渐进式过渡。此时的采样公式定义与epoch相关,定义(T表示总的训练epoch)如下:
除了上述re-sampling外,还有其他re-sampling方案,但是因为对应方案的复杂性以及噪声引入问题,作者并未将其纳入考虑。
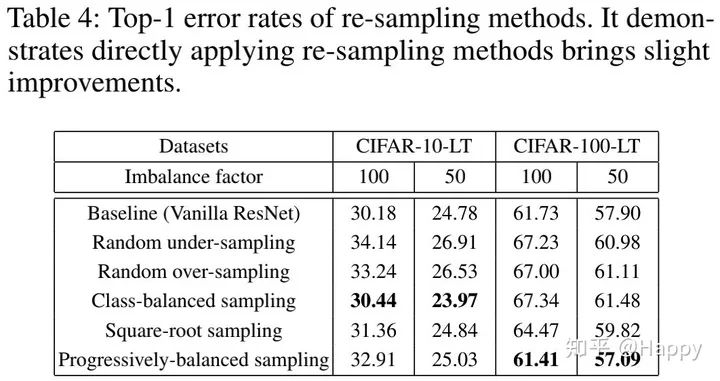
上表给出了不同re-sampling方案在CIFAR-LT数据上的性能对比,可以看到:直接在训练过程中实施re-sampling可以得到性能的轻微提升。
Mixup training
mixup training可以视作一种数据增光“技巧”,它旨在对CNN进行正则化。作者发现:当与re-sampling相结合时,mixup training在长尾识别任务中可以取得非常好的结果。接下来,我们将对现有的mixup training方案进行简单的汇总。
Input mixup 已被证实是一种有效缓解对抗扰动的方法。可以描述如下:
其中负责beta分布,在训练过程中用于训练。
Manifold mixup 通过利用语义插值作为额外的训练监督信息,可以促使神经网络在 hidden representation插值方面输出更低置信度。混合样本定义如下:
其中分别表示在第k层的中间结果输出,表示服从beta分布的混合系数。
Fine-tuning after mixup training 已有研究表明:如果移除最优几个epoch的mixup,通过mixup训练的模型可以取得性能的进一步提升。在该文中,作者先采用mixup进行训练,然后在进行几个epoch的微调以取得性能的进一步提升。
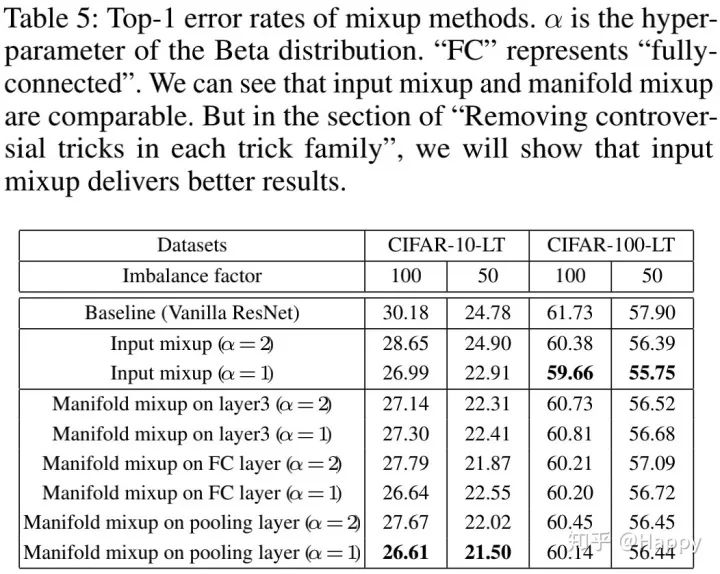
上表给出了mixup方案在CIFAR-LT数据上的性能对比,可以看到:
相比baseling,mixup与manifold mixup均可取得更好的性能; 当,mixup位于池化层之后时,input mixup与manifold mixup取得了同等的性能。
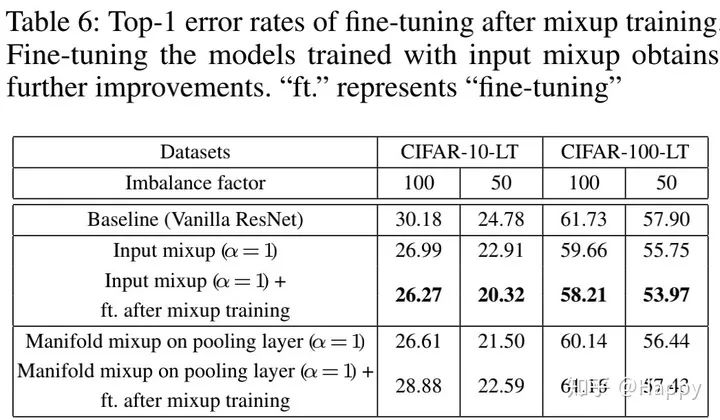
上表给出了mixuptraining后微调的结果,可以看到:input mixup后接微调可以更好的性能提升;而manifold mixup方案后接微调性能反而变差。
Two-stage training procedures
该方案包含类别不平衡训练与类别平衡微调两个阶段,作者主要针对类别平衡微调进行了探索。
Balanced fine-tuning after imbalanced training 在不添加任何re-weighting和re-sampling数据上训练的CNN可以学习更好的特征表达,但在尾部类别上存在识别精度差的问题。已有不少方法提出了类别平衡微调的优化方案,包含基于re-sampling(DRS)与基于re-weighting(DRW)的re-balancing。
DRS 采用常规方式进行训练,然后采用re-sampling方式进行类别平衡微调。 DRW 采用常规方式进行训练,然后采用re-weighting方式进行类别平衡微调。
现有的DRS方案中的re-sampling方法仅仅通过复制/移除的方式进行样本选择以期达到类别平衡的目的(这种方式的性能提升有限),为生成根据判别性的信息,作者提出了一种基于CAM的采样方案用于DRS,所提方法可以取得显著的性能提升。
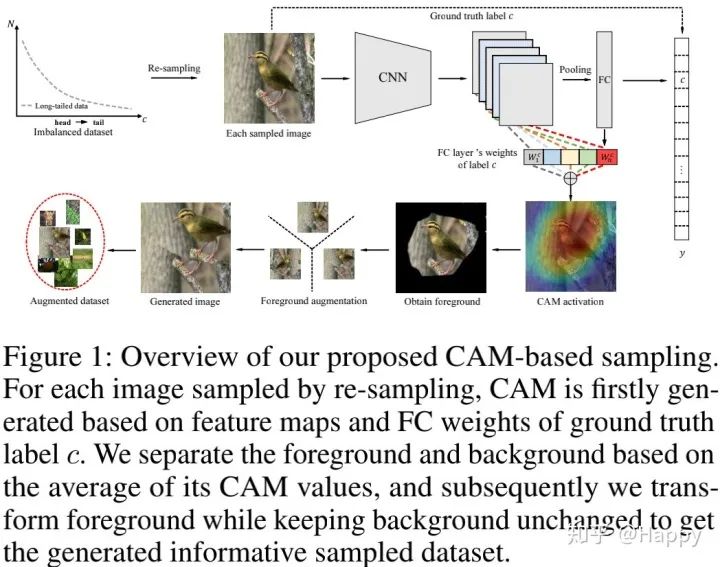
如上图所示,我们首先采用re-sampling方式得到类别平衡图像;然后对于每个采样图像,采用前一阶段训练的模型基于其标签生成CAM,基于CAM的均值进行前景与背景分离;最后对前景进行变换(包含随机水平镜像、平移、旋转、缩放等)而保持背景不变。注:所提方案可以与常见的采样方案相结合使用。
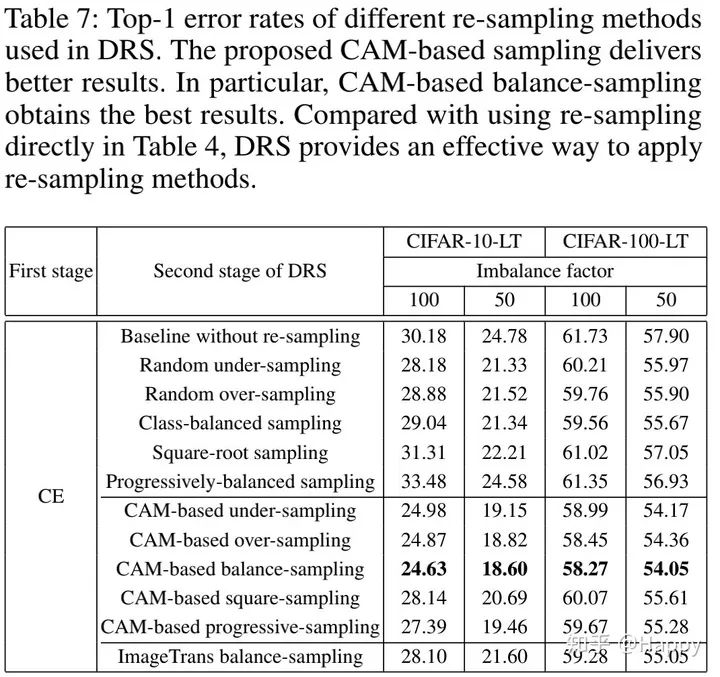
上表给出了DRS方案性能对比,从上表可以看到:
相比直接使用re-sampling,在DRS中re-sampling可以取得更好的性能; 所提CAM-based sampling 可以取得一致性的性能提升; 在所有CAM-based方案中,CAM-based balance-sampling取得最佳结果; Image-Trans balance-sampling方案证实了CAM-based balance sampling的有效性。
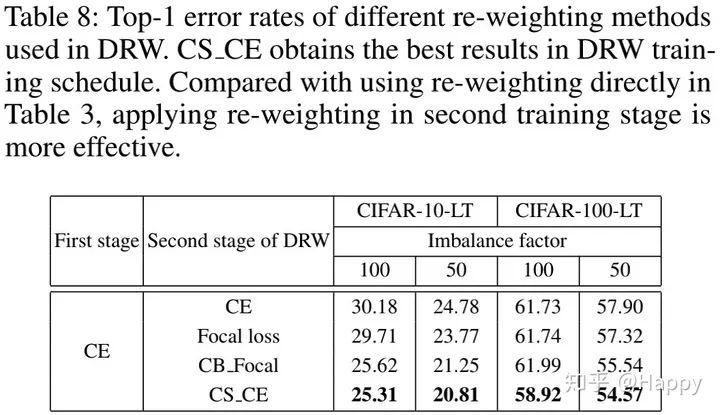
上表给出了DRW方案的性能对比,从中可以看到:
相比直接实施re-weighting,re-weighting与DRW的组合可以取得更好的结果; DRW与CS_CE的组合取得了最佳的结果。
Trick combinations
接下来,我们对每个“技巧”类中的“冲突技巧”(具有相当结果)进行总结,并将其与其他“技巧”类中的方案相组合以找到最佳的技巧组合。
Removing conflictual tricks in each trick family
在Two-stage training部分内容可以看到:最佳的训练机制为DRS+CAM-based over-resampling和DRW+CS_CE。然而DRS与DRW均为two-stage training技巧。因此,我们需要进行更多的实验以探索最佳的组合。
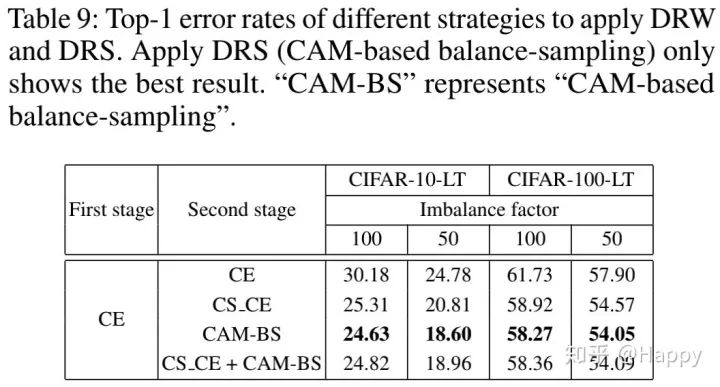
上表表明:DRS+CAM-based balance-sampling是最佳two-stage training组合。同时也可以看到:CS_CE与CAM-BS的组合并不会得到性能的提升,反而造成了性能下降。
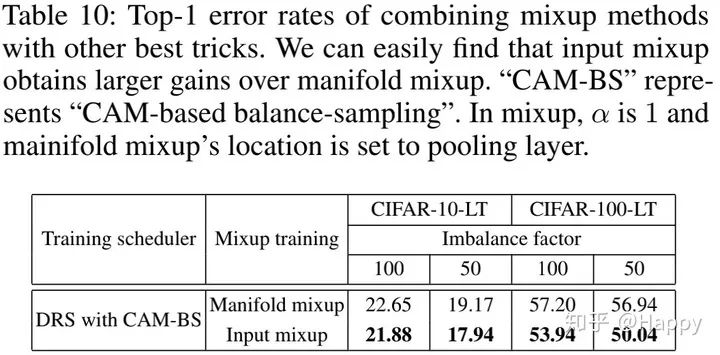
从上表可以看到:当与其他最佳技巧组合时,相比manifold mixup,input mixup可以取得更好的性能提升。
从实验结果来看,最佳的“技巧大礼包”为:input mixup + DRS+CAM-BS + fine-tuning,作者将其称之为“bag of tricks”。
Applying the best tricks incrementally
为证实前述“bag of tricks”的性能,作者将其在iNaturalist2018与ImageNet-LT数据上进行了实验对比。

从上表可以看到:
Input mixup + DRS+CAM-BS + fine-tuning的组合取得了稳定的性能提升; iNaturalist2018与ImageNet-LT数据上的实验证实了所提“bag-of-tricks”的有效性; 基于所提“bag of tricks”,在所有长尾数据上可以取得10%的误差率下降,在相比SOTA方案取得了显著的性能提升。
推荐阅读