
消息系统概述
 最近开始学习Kafka。在学习前,给自己确定了下学习的范围,大致如下:
最近开始学习Kafka。在学习前,给自己确定了下学习的范围,大致如下:
理解Kafka的相关概念; 掌握Kafka的基本API使用; 了解Kafka的背后原理。
后续将在这学习范围内输出一些相关文章。那么本文作为Kafka系列的第一篇文章,将从“理解Kafka的相关概念”说起。首先Kafka是什么。
Kafka起初是由LinkedIn公司采用Scala语言开发的一个多分区、多副本且基于ZooKeeper协调的分布式消息系统,现已被捐献给Apache基金会。目前Kafka已经定位为一个分布式流式处理平台,它以高吞吐、可持久化、可水平扩展、支持流数据处理等多种特性而被广泛使用。
从上述介绍中,我们可以知道Kafka具有消息系统和流式处理平台两种角色。为了更好的理解Kafka,本文将对消息系统进行介绍。
消息系统
消息系统,又被称作消息中间件。现在听到较多的是消息队列(MQ)的叫法,算是消息中间件的一种简称,其实都是同样的意思。那么消息系统是什么。
看一个我们都熟悉的场景——电子邮件。我们发送电子邮件,实际上就是将一个邮件文件从我们的电脑转发到对方电脑上,但是我们在发送的时候,并不需要关心对方的电脑是否开着,只管发送就好,邮件会先被发送到邮件服务器上,然后当对方电脑开机时,再从邮件服务器上获取邮件。邮件服务器就是一个消息系统,可暂存应用之间通信所发送的消息。而这样能带来的好处也显而易见了,作为发送消息的生产者并不需要关心接收消息的消费者的状态,生产者只需确保将消息成功发送到消息系统即可,这是一种异步通信模式。
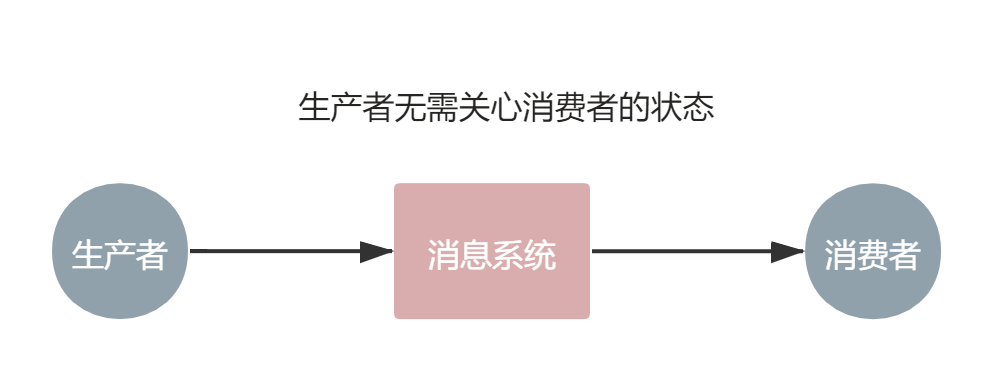
这种通信模式起到了解耦的作用,减少了生产者的职责。生产者只需关注生产消息和把消息发送到消息系统,而消费情况无需关注。
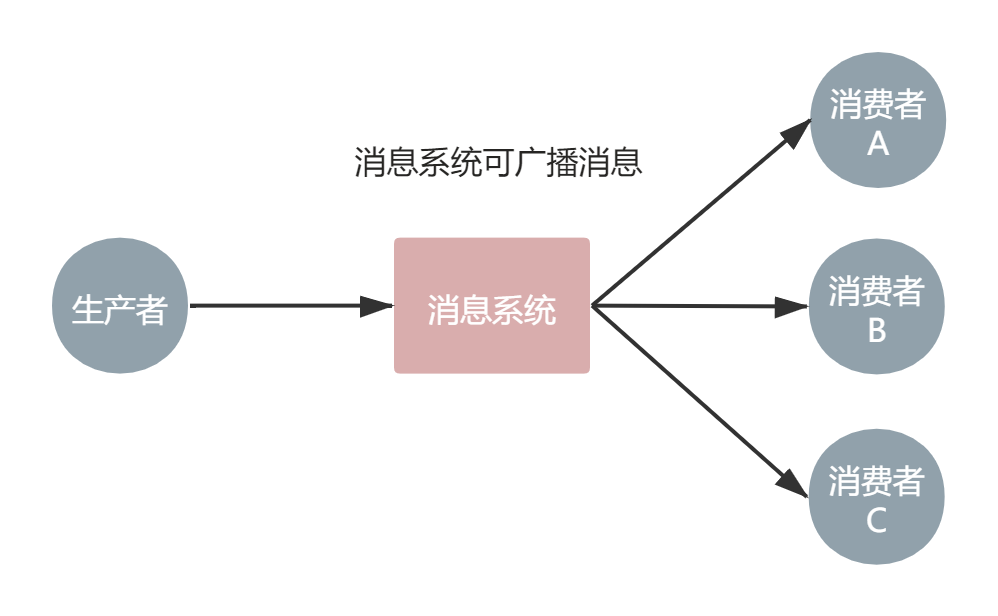
不仅如此,除上述我们描述的点对点(单消费者)情况,我们还可以在生产者无感知的情况下,使用发布/订阅模式。加入的新消费者去订阅主题,然后由消息系统广播给所有订阅的消费者,这为系统的扩展提供了便利。
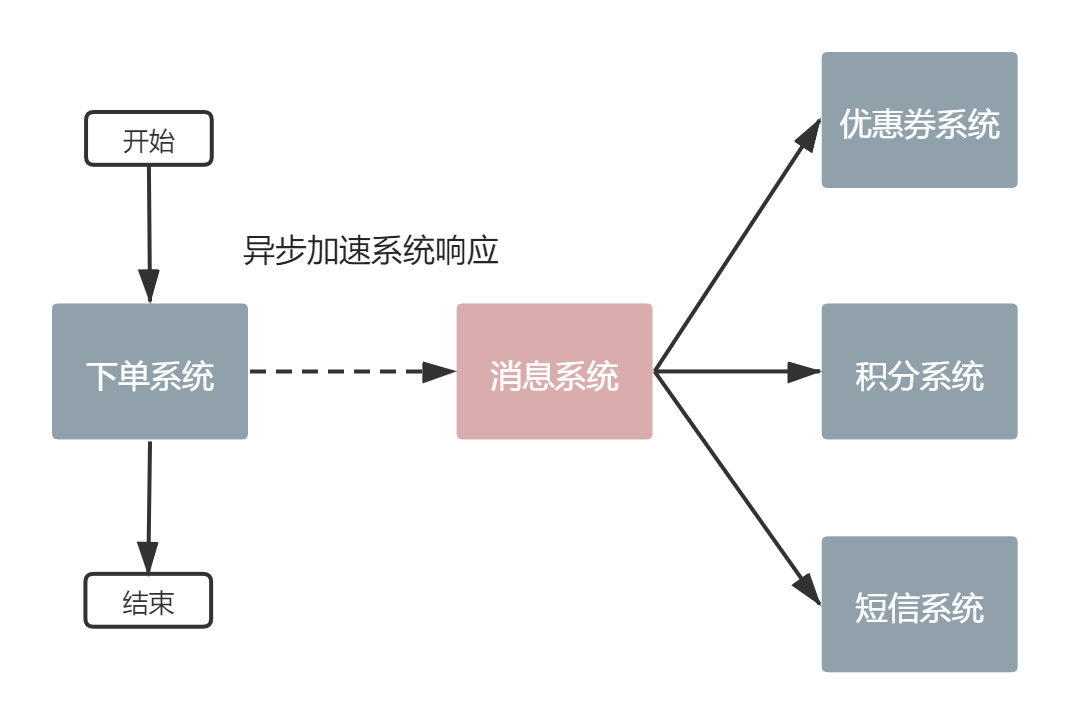
而且通过异步能加快系统的响应。例如一个下单操作,需要涉及优惠券、积分和短信等系统的处理,如果使用同步则需要等所有系统都处理完,但这样下单系统的响应时间将大大增加。通过使用消息系统,下单系统只需将下单操作的消息写入,然后完成下单操作,响应给用户。至于优惠券、积分、短信等将由相应系统从消息系统中获取下单操作消息进行处理。
我们再试想下这样的场景,当下单系统接收的请求突增的时候,消息系统也能起到削峰/限流的作用,暂存消息,让下游系统根据自身处理能力来处理消息,避免下游系统崩溃,系统也将更为稳定。
关注的问题
通过上述的介绍,对消息系统有了一定的认识。下面我们再进一步的思考下,消息系统的功能我们已经知道了,如果让我们使用一个消息系统,需要关注哪些问题,以下是我所想到的一些:
可用性。如果消息系统挂了,那消费的下游系统都将失效,所以需要保证可用性。 吞吐量。如果上游系统每秒百万级的吞吐量,需要让消息系统的写入吞吐量与其匹配。同时也需关注下游系统消费情况的吞吐量。 消息丢失。上游系统->消息系统->下游系统,这两个过程都有可能发生消息丢失。 消息顺序。这个问题其实和消息丢失是同时存在的,由于消息的丢失,将造成消息顺序的错乱。
在后续的学习中,将带着这几个问题,去看看Kafka是如何解决。
参考
《深入理解Kafka核心设计与实践原理》
消息队列的使用场景(https://www.zhihu.com/question/34243607/answer/1023686807)
什么是消息队列(https://juejin.im/post/6844903817348136968)
消息队列设计精要 (https://tech.meituan.com/2016/07/01/mq-design.html)
完

觉得不错,点个在看~
