
组合式创新?CLIP+VQGAN

ace
新旧交替之际,不同时代的审美。这个现象真有趣~~

知识库
最近有大量使用CLIP+VQGAN的数字艺术作品出现,这两项组合技术不知大家都玩过没?
OpenAI的CLIP
用于连接文本与图像
具体的应用,比如一位开发者的项目:通过文本搜索精准匹配图片的项目。该项目大约有200 万张Unsplash的图片 ,通过 CLIP 模型处理后,可以使用自然语言进行精准搜索。
github.com/haltakov/natural-language-image-search

"Two dogs playing in the snow"

"The word love written on the wall"
VQGAN
生成式模型
关键是使用Transformer来把图像encoder后的编码进行了转化,学习到了图像特征的上下文关系
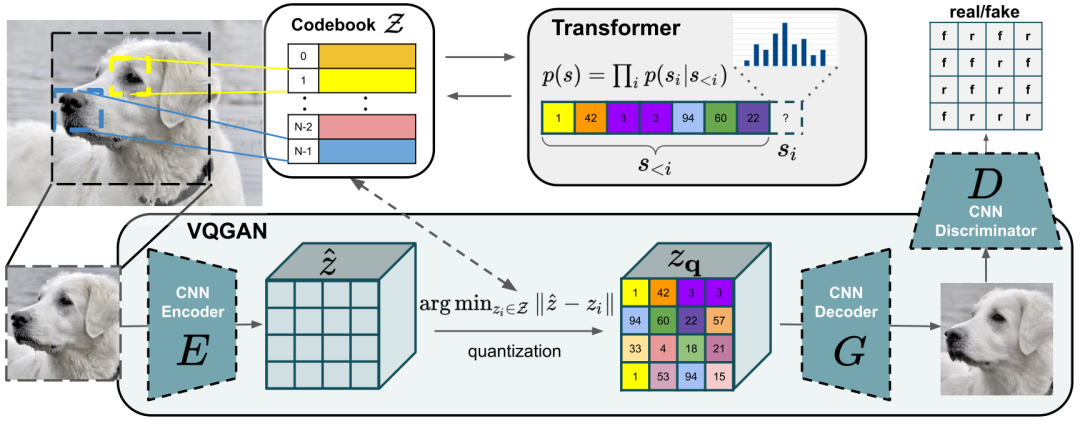
Taming Transformers for High-Resolution Image Synthesis
CVPR 2021
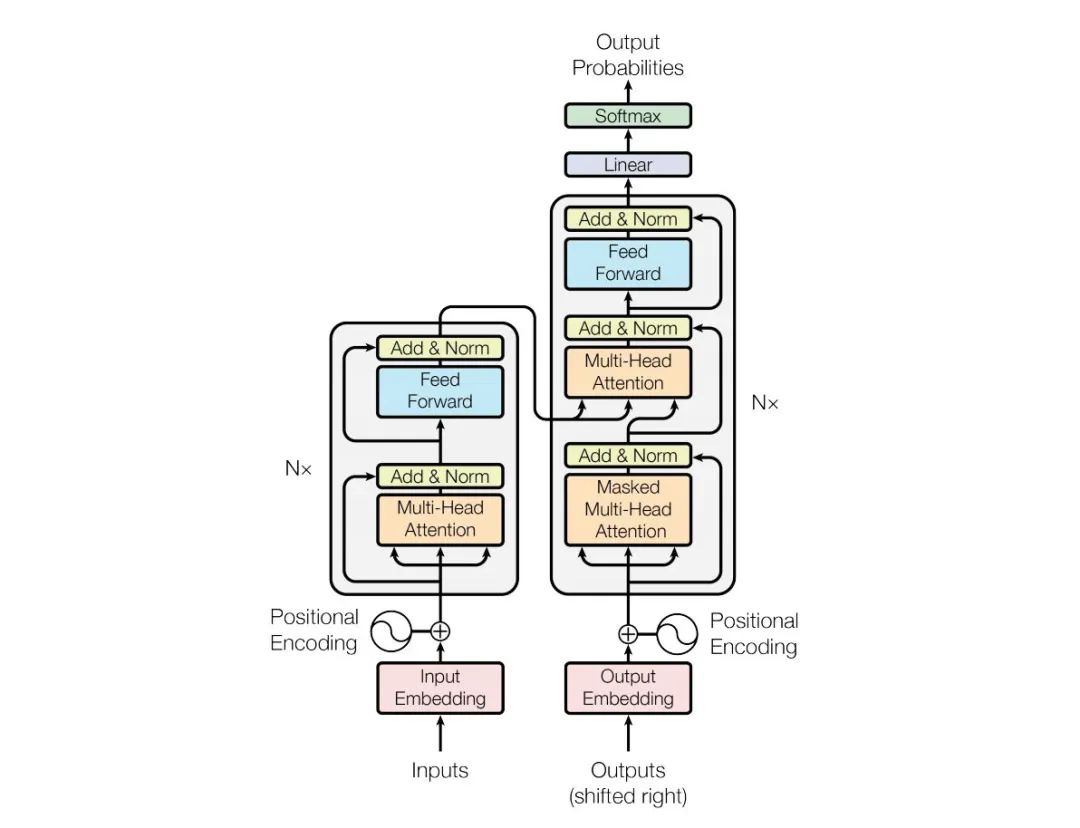
Transformer
从NLP走向CV
Transformer最初应用于NLP任务,是2017年的论文《Attention is All You Need》提出的模型架构,作者实验了机器翻译,获得了当时的SOTA。语言是有很明显的上下文关系的,基于此特点,开始了在CV领域的应用探索。

无界
 引用我超喜欢程序猿的一句diss用语:
引用我超喜欢程序猿的一句diss用语:
Talk is cheap ,
show me the code
 都是开源的……
都是开源的……
那么CLIP+VQGAN是什么?
使用CLIP来代替VQGAN的鉴别器


shadow
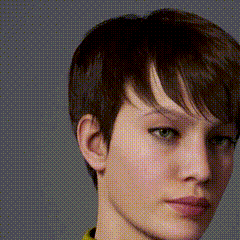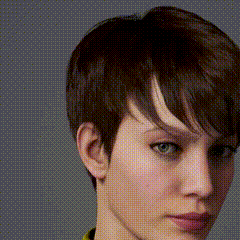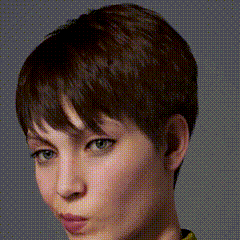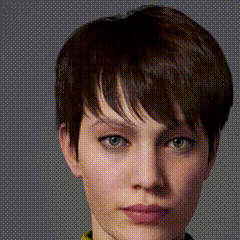
eva
 我来测试下CLIP+VQGAN ~~
我来测试下CLIP+VQGAN ~~



opus
@Bessie 看看~
有那么点味道~~

ibrand


 还用上了深度估计+fake 3D来生成GIF
还用上了深度估计+fake 3D来生成GIF
大家可以基于hack city来创作各种数字图像作品~~~哈哈
shadow

opus
在线玩耍地址:
huggingface.co/spaces/akhaliq/VQGAN_CLIP
👨🏼🎤👩🏻👨🏻💼👤🦸🏻🧑🏻🎤
如果对以上话题感兴趣,
欢迎加入社群,
关注后回复:群聊
评论