
1. 同个结构体占用内存可变化
在 C/C++中结构体类型,就这?章节里,对struct的功能和使用进行了详细的说明。「内存对齐」章节作为struct的一个扩充知识。事实也证明,实际开发中,关注结构体内存布局特性的同事寥寥无几。甚至某些同事表示从未去留意过声明的结构体所占用内存空间大小,他们会感到诧异、惊讶,为何声明的是同一个结构体数据类型,但是当成员列表位置排列顺序进行了细微的调整(数据类型相同,成员数量保持不变)之后,占用的内存空间却不相同。有这些疑惑的同事,我相信你在阅读完本节内容之后,定会茅塞顿开,解开你内心的疑惑。请让我们以声明的两个结构体数据类型 struct a 和 struct b 作为拉开本节的序幕。当这两个结构体数据类型出现在你眼前时候,你是否能够第一时间里快准狠地说出你脑海中的答案,并能够确保它是正确无误的。struct a
{
char c;
int i;
short s;
};
struct b
{
int i;
char c;
short s;
};
很显然,这两个数据类型里除了成员列表的排列顺序有所不同外,并无任何其他差异。作为选择题,毫无疑问它只有3个待选答案:
[1] 数据类型「struct a」占用内存空间大于数据类型「struct b」
[2] 数据类型「struct a」占用内存空间等于数据类型「struct b」
[3] 数据类型「struct a」占用内存空间小于数据类型「struct b」
无论你的答案是[1],还是[2],又或许是[3],都暂时搁置片刻,因为此刻我并不着急你给出回应。与其匆忙中给出答案,我更希望的是答案推导的过程。数据类型「struct a」和 数据类型「struct b」之间的内存占用关系究竟如何?让我们带着这个问题继续往下走。
2. 结构体内存布局
WIKI 中强调:
The C struct directly references a contiguous block of physical memory, usually delimited (sized) by word-length boundaries. The contents of a struct are stored in contiguous memory.
即结构体(struct)数据类型中各成员列表占用连续内存空间。现在对上面的数据类型「struct a」和 数据类型「struct b」中各成员分别在内存中的位置作一个分析。
所有的代码运行结果信息都是基于以下环境:
操作系统:CentOS Linux release 7.5.1804 (Core) 64位
CPU型号:Intel® Xeon® CPU E3-1225 v3 @ 3.20GHz
CPU核数:cpu cores : 4
既然结构体中各成员所占用的内存空间是连续的,那么在不考虑其他因素的情况下,数据结构struct a和数据结构struct b内存空间的占用情况大致如下图1和图2所示。
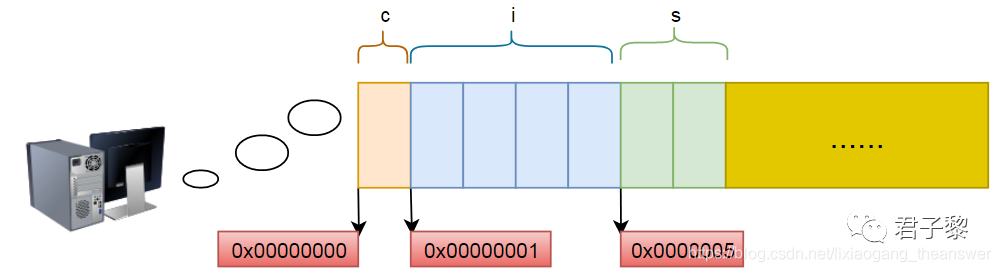
▲ 数据类似struct a 内存空间分布情况
如果数据类型struct a的内存空间分布情况真如图1所示,那么可得知其内存大小为: 7 Byte。即 c(1Byte)+ i(4Byte) + s(2Byte)。
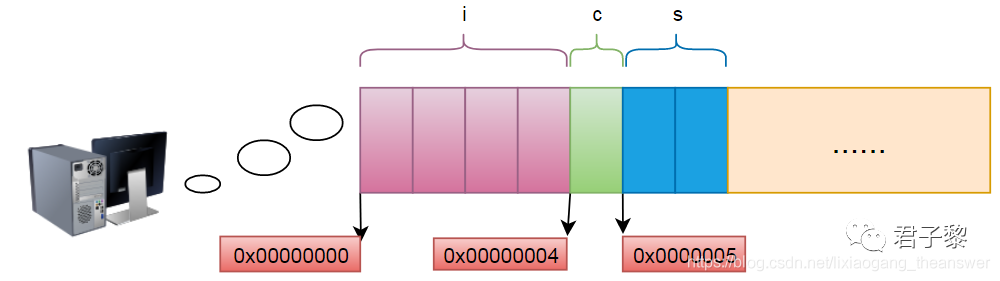
▲ 数据类型struct b 内存空间分布情况
同理数据类型 struct b的内存大小也是: 7 Btye。那么真实情况是这样吗?下面我们使用sizeof 操作符来打印下数据类型struct a和struct b的真实内存占用大小。
#include <ucontext.h>#include <stdio.h>struct a{ char c; int i; short s;};
struct b{ int i; char c; short s;};int main(){ printf("sizeof(struct a) = %lu\n", sizeof(struct a)); printf("sizeof(struct b) = %lu\n", sizeof(struct b)); return 0;}
打印结果:
sizeof(struct a) = 12
sizeof(struct b) = 8
最终打印的真实结果和猜想有出入,且都是大于或等于各成员列表的数据类型和。现借助offsetof 宏来分别查看每个成员在该结构体内存占用中的偏移量。
2.1 offsetof 定位某成员在结构体中的「 偏移量」
让我们先看下offsetof的定义,摘自 Linux Kernel 5.4.3 源码的scripts/kconfig目录下的list.h文件。
#undef offsetof
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
第一个参数TYPE是结构体的名字,第二个参数MEMBER是结构体成员的名字。该宏返回结构体TYPE中成员MEMBER的偏移量。偏移量是size_t类型的。
现在使用offsetof来分别打印数据类型struct a和数据类型struct b中的各成员在各自结构体中的偏移量,同时结合内存地址来进行一个全面的分析。
#include <ucontext.h>#include <stddef.h>#include <stdio.h>struct a{ char c; int i; short s;};
struct b{ int i; char c; short s;};int main(){ struct a a1 = {.c = 'L', .i = 26, .s = 27}; struct b b1 = {.i = 26, .c = 'X', .s = 27}; printf("\t-------------------------------------------------------------------\n"); printf("\ta1.c = %c, a1.i = %d, a1.s = %d\n", a1.c, a1.i, a1.s); printf("\ta1.c = %ld, a1.i = %ld, a1.s = %ld\n", offsetof(struct a, c), offsetof(struct a, i), offsetof(struct a, s)); printf("\ta1.c = %p, a1.i = %p, a1.s = %p\n", &(a1.c), &(a1.i), &(a1.s)); printf("\t-------------------------------------------------------------------\n"); printf("\tb1.i = %d, b1.c = %c, b1.s = %d\n", b1.i, b1.c, b1.s); printf("\tb1.c = %ld, b1.c = %ld, b1.s = %ld\n", offsetof(struct b, i), offsetof(struct b, c), offsetof(struct b, s)); printf("\tb1.c = %p, b1.c = %p, b1.s = %p\n", &(b1.i), &(b1.c), &(b1.s)); printf("\t-------------------------------------------------------------------\n"); return 0;}
打印的结果如下图3所示:

▲ 数据类型struct a和struct b中各成员在结构体中内存偏移量
上图中红色框标注的是各成员在结构体所占用内存中的偏移量。和预期中的图1、图2是有差异的。根据图3中的打印结果重新画一个数据类型struct a和struct b中各成员的内存分布图。
对于数据类型struct a, 其中成员c的偏移量是0,成员i的偏移量是4。因为成员c是char类型,所以占用1字节内存空间;那么成员c和成员i之间,有3个字节是填充字节。成员s偏移量是8, 这个没有疑问,因为int类型占用4字节空间,成员i到s之间无填充字节;数据类型struct a占用的总内存空间是12,而成员s是short int类型,占用2字节,因此,成员s之后有两个字节是填充的。内存占用分布如下图所示。
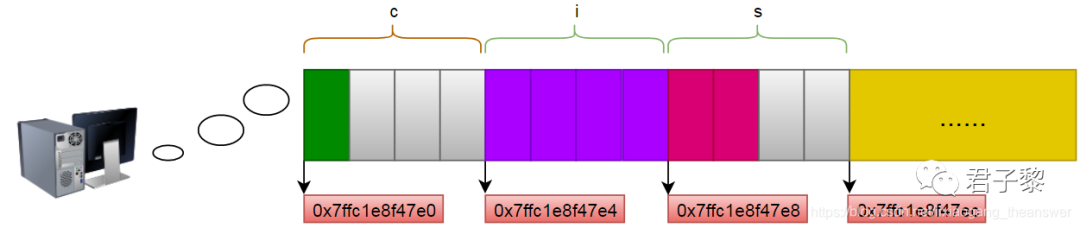
▲ 数据类型struct a真实内存分布
对于数据类型struct b,成员i为第一个结构体成员,且为int,占用4字节内存空间;成员c的偏移量为4,这个没有问题。但是成员s的偏移量是6,而成员c是char数据类型,占用1字节的内存空间,那么成员c到成员s之间有一个填充字节。又因为struct b数据类型占用的总内存空间是8,则成员s(short int类型,占用2字节)之后无填充字节。内存占用分布如下图所示。
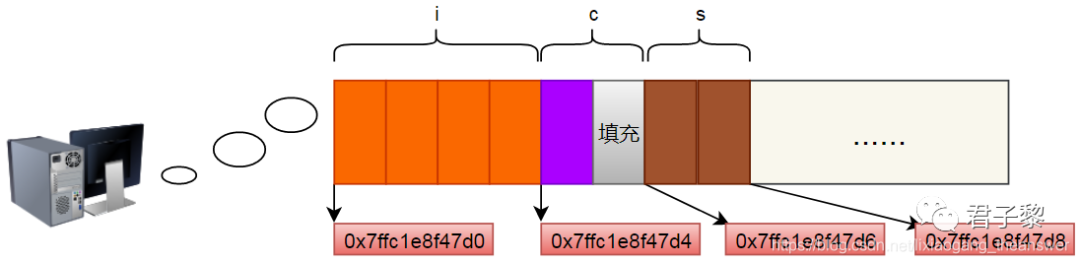
▲ 数据类型struct b真实内存分布
到这里时,难免有些疑问,为何结构体占用的内存空间会大于或等于各成员列表的数据类型之和呢?为什么会有填充字节存在?谁负责填充?什么时候填充?有何作用?想要解开这系列的疑惑,就得知道「内存对齐」原理和作用。
2.2 为保证内存对齐,填充了什么值
填充位的值是未定义的,尤其是不能保证它们会归零。老派的说法是"slop"。
3. 内存对齐
Linux开发同事应该会很清楚这样一个事实,运行的成果物是经过编译、链接之后生成的ELF格式的目标文件。当程序运行起来时候,系统会去读取ELF文件,并将文件中的数据(地址、代码段、数据段、符号表链接等等)信息加载到系统的内存中;程序会按照事先指定的条件去不断运行。在这个过程中,CPU会不断地去从内存条某地址上面不断的来回读取数据到寄存器上面参与运算。当计算机读取或写入内存地址时,它将以字(word)大小的块进行存储。数据对齐意味着将数据放在等于字长的倍数的内存偏移处,这由于CPU处理内存的方式而提高了系统的性能。大多数CPU只能访问内存对齐的地址。
Microchip 中对于内存对齐就作了如下说明:
由于PIC32MZ存储器系统为32位宽,因此可以对齐或不对齐大小为32位(4字节或WORD)或16位(2字节或半字)的数据访问:
i. WORD大小传输执行到4的倍数的地址:0x00000000、0x00000004、0x00000008, … ii. 半字大小传输执行到2的倍数的地址:0x00000000、0x00000002、0x0000000, …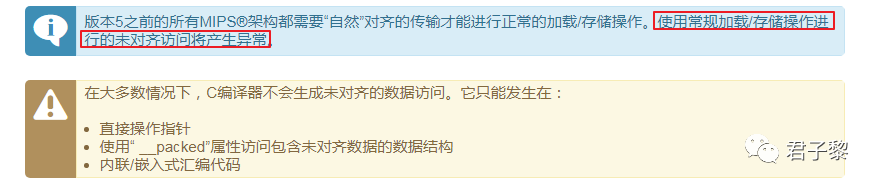
在看完Microchip中对于“内存对齐”的描述说明后,是不是豁然开朗。不急,再看下关于“内存对齐”的一段正式定义:
关于内存对齐,有这样一段正式定义:
A memory address a, is said to be n-byte aligned when n is a power of two and a is a multiple of n bytes. In this context a byte is the smallest unit of memory access, i.e. each memory address specifies a different byte. An n-byte aligned address would have log2 n least-significant zeros when expressed in binary.
A memory access is said to be aligned when the data being accessed is n bytes long and the address is n-byte aligned. When a memory access is not aligned, it is said to be misaligned or Non Aligned. Note that by definition byte memory accesses are always aligned.
当n是2的幂且a是n字节的倍数时,内存地址a被称为n字节对齐。在这种情况下,字节是存储器访问的最小单位,即每个存储器地址指定一个不同的字节。当以二进制表示时,一个n字节对齐的地址将具有log2的n次方个最低有效零。当正在访问的数据为n字节长且地址为n字节对齐时,则称内存访问已对齐。如果内存访问未对齐,则称其为未对齐或未对齐。请注意,根据定义,字节存储器访问总是对齐的。
内存对齐(Memory alignment)概念的引入,基于两个条件:
(1) 某些处理器不支持访问位于不对齐内存地址上面的数据,会产生异常事件。(2) 访问非对齐内存地址上面的数据,会降低CPU的性能。因为如果没有对齐约束,代码可能最终不得不跨越机器字边界进行两次或多次访问。Daniel Drake、Johannes Berg对于「Unaligned Memory Accesses」未对齐内存访问 就提出了以下几点说明:
执行未对齐内存访问的效果因体系结构而异。在这里,很容易就可以写出一份关
于这些差异的完整的文档;常见的情况摘要如下:
- 有些体系结构能够透明地执行未对齐的内存访问,但通常会有很大的性能开销。
- 有些体系结构在发生未对齐访问时引发处理器异常。异常处理程序能够更正未对齐的访问,但会大大降低性能。
- 有些体系结构在发生未对齐访问时引发处理器异常,但这些异常不包含足够的信息,无法更正未对齐访问。
- 有些架构无法进行未对齐的内存访问,但是会静默地对请求的内存执行另一种内存访问,从而导致难以检测的细微代码错误!
可想而知,访问未对齐的内存地址是多么的糟糕!!!
DevX.com 中强调:大多数CPU要求对象和变量位于系统内存中的特定偏移处。例如,32位处理器需要一个4字节的整数来驻留在可被4整除的内存地址上。此要求称为“内存对齐”。因此,一个4字节的int可以位于内存地址0x2000或0x2004处,而不是0x2001。在大多数Unix系统上,尝试使用未对齐的数据会导致总线错误,从而完全终止程序。在Intel处理器上,支持使用未对齐的数据,但会大大降低性能。因此,大多数编译器会根据其类型和所使用的特定处理器自动对齐数据变量。这就是为什么结构和类占用的大小通常大于其成员大小之和的原因。
3.1 结构体成员默认内存对齐
如下表1为结构体成员在不同编译器环境下的默认内存对齐方式。编译器将根据需要在成员之间插入未使用的字节,以获得此对齐方式。编译器还将在结构的末尾插入未使用的字节,以使结构的总大小是需要最高对齐的元素的对齐的倍数。许多编译器都有更改默认对齐方式的选项。结构成员对齐方式的不同将导致访问相同数据的不同程序或模块之间的不兼容性,以及数据何时存储在二进制文件中。我们可以通过对结构成员进行排序来避免此类兼容性问题,从而无需插入未使用的字节。同样,可以通过插入所需大小的虚拟成员来明确指定结构末尾的填充。虚拟表指针的大小(如果有)必须考虑在内。
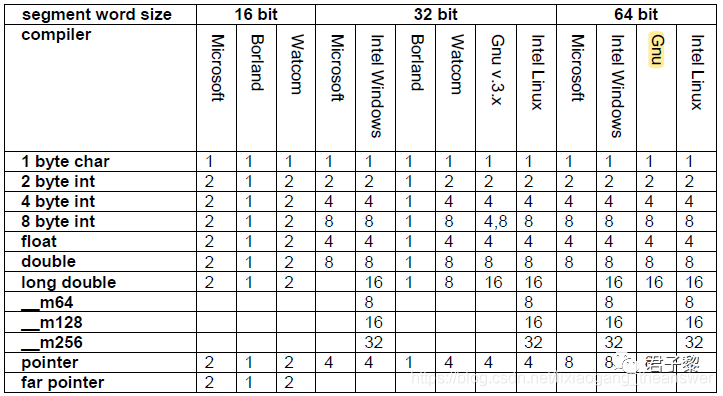
▲ 表1 结构和类数据成员字节对齐方式
3.2 不同架构内存对齐方式
表2描述了一些内存地址在不同架构平台上面的内存对齐方式,可供参考。
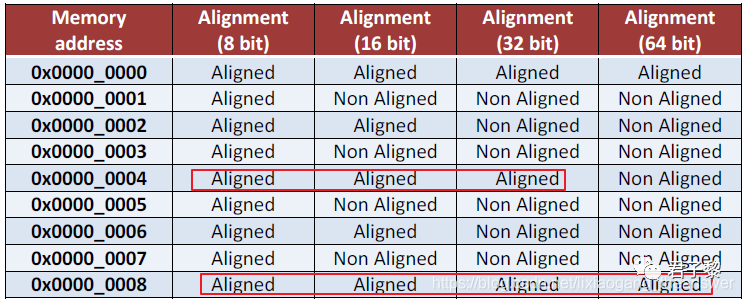
▲ 表2 不同架构上的内存对齐
要找出运行现代UNIX的处理器的自然字长,可以使用以下命令:
getconf WORD_BIT
getconf LONG_BIT
对于现代的x86_64计算机,WORD_BIT将返回32,LONG_BIT将返回64。对于没有64位扩展的x86计算机,这两种情况下都是32位。

3.3 编译器了解「对齐约束 」
尽管某些处理架构对访问未对齐的内存地址数据会产生异常现象,但是平时开发中却几乎碰不到。这是因为编译器了解对齐约束规则,在背后会对声明的结构体数据类型作检测,若成员列表不满足对齐规则,则会默认填充字节满足规则。即当访问N个字节的内存时,基本内存地址必须被N整除,即addr%N ==0。正如前面声明的数据类型:struct a。
3.3.1 单个字节永不会导致未对齐内存访问
访问单个字节(unsigned char或char)将永远不会导致未对齐的访问,因为所有内存地址都可以被一个整数整除。如:
typedef struct SingleChar
{
char a;
}SingleCh;
则数据类型SingleCh大小将永远是为1。
4. 小试牛刀
通常,结构实例将具有其最宽标量成员的对齐方式,编译器这样做是确保所有成员都能自对齐以快速访问的最简单方法。如下定义:

结构总是与最大类型的对齐需求保持一致。
换言之,它等同于下面的定义。

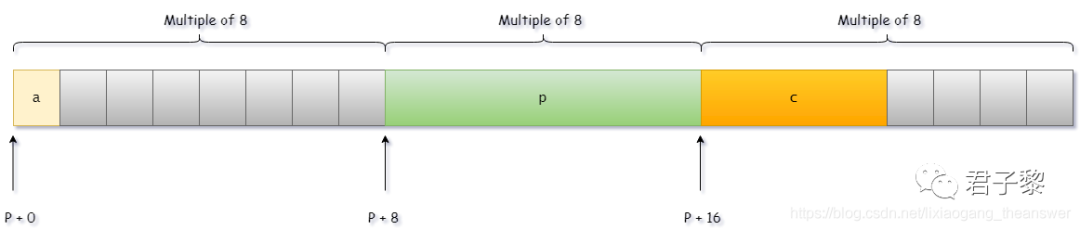
因此,对于下面的结构数据类型声明 struct Test 。 则 Kmax = 4,取决于int类型,因为在该数据类型的成员列表中,int数据类型最大。 则 Kmax = 8,取决于char*类型,因为在该数据类型的成员列表中,char*指针数据类型最大。
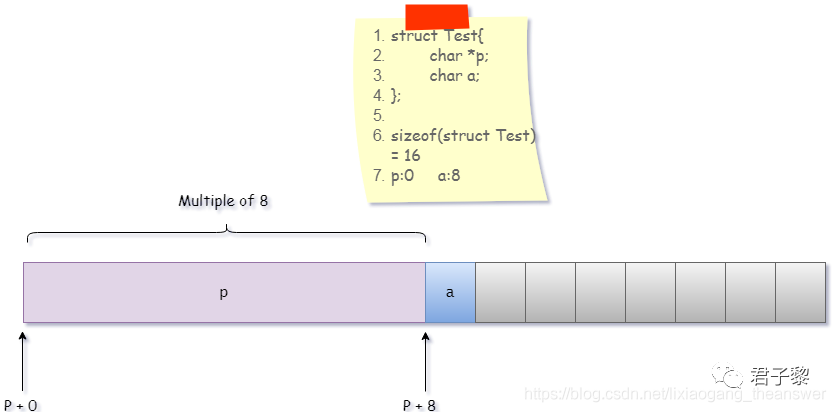
示例一
#include <stdio.h>#include <stdlib.h>#include <string.h>
struct Test{ char a; char *p; int c;};
int main(){ struct Test t; printf("sizeof(t) = %ld\n", sizeof(t)); return 0;}
数据类型struct Test占用的内存空间大小是:24字节。
struct Test{
char a;
//char pad[7] 填充7字节
char *p;
int c;
//char pad[4] 填充4字节
};
示例二
#include <stdio.h>#include <string.h>#include <stdlib.h>
struct a{ int a; char b; short c;};int main(){ printf("sizeof(struct a) = %ld\n", sizeof(struct a)); return 0;}
struct a
{
int a;
char b;
//char pad[1] 填充1字节
short c;
};
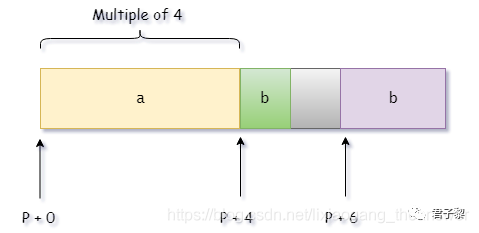
当结构体内部嵌套其他结构体时候,同样会有内存对齐规则。#include <stdio.h>#include <string.h>#include <stdlib.h>
struct a{ char c; struct b{ char *p; short d; }b1;};int main(){ printf("sizeof(struct a) = %ld\n", sizeof(struct a)); return 0;}
struct a
{
char c;
//char pad[7] 填充7字节
struct b{
char *p;
short d;
//char pad[6] 填充6字节
}b1;
};
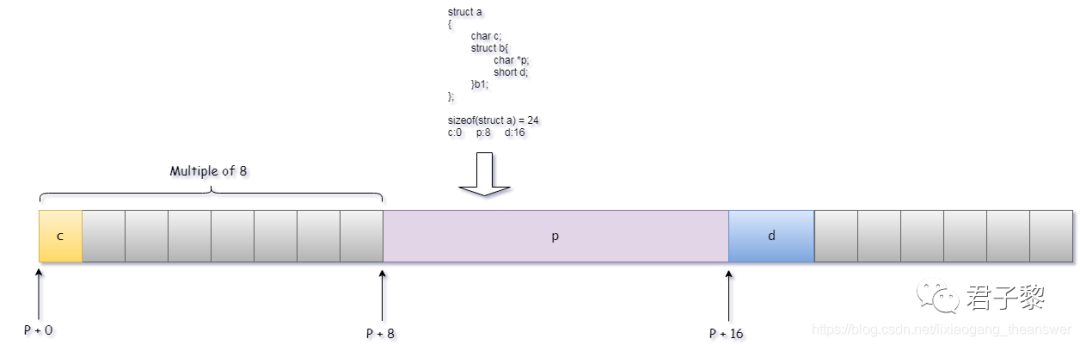
示例三
#include <stdio.h>#include <stdlib.h>#include <string.h>
struct Test{ char *p; char a;};int main(){ struct Test t; struct Test t1[4]; printf("sizeof(t) = %ld\n", sizeof(t)); printf("sizeof(t1) = %ld\n", sizeof(t1));
return 0;}
在64位系统上面,指针数据类型占8字节。因此,该数据类型占用的内存空间大小是:16字节。
struct Test{
char *p; //8Btye
char a; //1Byte
//char pad[7] //填充7Byte
};
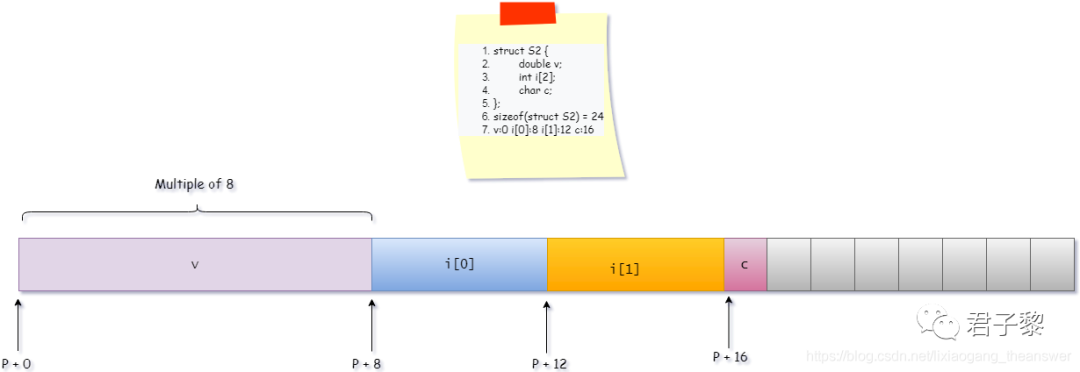
struct S2 {
double v;
int i[2];
char c;
};
数据类型 struct S2中,Kmax = 4,因此成员列表中各成员按照4字节内存对齐。
5. 禁止编译器因内存对齐而进行内存填充
在前面有反复提及过,尽管声明的结构体数据类型本身各成员列表不具备内存对齐条件,但是编译器会进行合适字节填充,以为了达到内存对齐的条件。有了默认填充规则,当然也有显示禁止填充的条件;如果你十分确认你的处理架构能够访问、读写不对齐的内存地址,且不会带来效率降低的潜在风险。你可以在项目中显示的告知编译器不要进行内存对齐而填充其他字段。很显然,这样带来了内存空间的节约;但是可移植差,具有隐藏BUG。
If desired, it’s actually possible to prevent the compiler from padding a struct using either __attribute__((packed)) after a struct definition, #pragma pack (1) in front of a struct definition or -fpack-struct as a compiler parameter. It’s important to note that using either of these will generate an incompatible ABI. We can use the sizeof operator to check the effective size of a struct and output it
during runtime using printf.大致上就是说:“如果需要,实际上可以防止编译器在结构定义后使用_attribute__((packed))填充结构,或者在结构定义前使用#pragma pack(1),或者使用-fpack-struct作为编译器参数。需要注意的是,使用这两种方法都会生成不兼容的ABI。我们可以使用sizeof操作符来检查结构的有效大小,并在运行时使用printf输出它。”
示例一struct{ char a;#if 0 int b __attribute__((packed));#else int b;#endif}a;
若在成员b后面添加__attribute__((packed)) ,则结构体大小是5;反之则是8.
示例二
使用该GNU编译参数能够达到和示例一同样的效果。
《深入Linux内核架构》一书中的附录 -“附录a.3 对齐” , 也对内存对齐进行了描述。如下图:

