
iOS Memory 内存详解
👇👇关注后回复 “进群” ,拉你进程序员交流群👇👇
作者丨Rickey
来源丨一瓜技术(tech_gua)

0. 前言
本文以 iOS Memory 的相关内容作为主题,主要从一般操作系统的内存管理、iOS 系统内存、app 内存管理等三个层面进行了介绍,主要内容的目录如下:
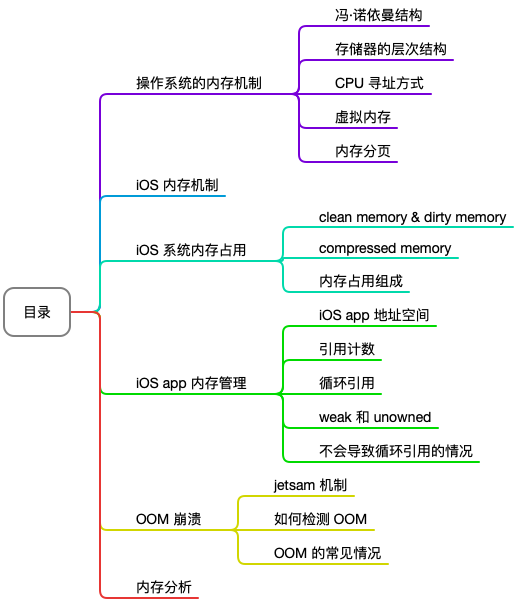
iOS 是基于 BSD 发展而来,所以先理解一般的桌面操作系统的内存机制是非常有必要的。在此基础之上,本文会进一步在 iOS 系统层面进行分析,包括 iOS 整体的内存机制,以及 iOS 系统运行时的内存占用的情况。最后会将粒度缩小到 iOS 中的单个 app,讲到单个 app 的内存管理策略。
1. 操作系统的内存机制
为了从根本上更好地理解和分析 iOS 系统上的内存特性,我们首先需要正确理解一般操作系统通用的内存机制。
冯·诺依曼结构
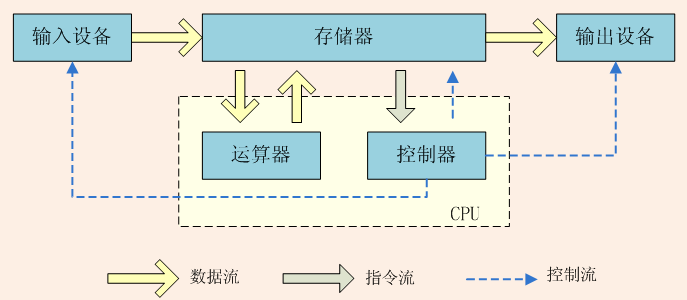
冯·诺依曼结构(Von Neumann architecture)在 1945 年就已经被提出了, 这个概念当时十分新颖,它第一次将存储器和运算器分离,导致了以存储器为核心的现代计算机的诞生。
在冯·诺依曼结构中,存储器有着重要地位,它存放着程序的指令以及数据,在程序运行时,根据需要提供给 CPU 使用。可以想象,一个理想的存储器,应该是兼顾读写速度快、容量大、价格便宜等特点的,但是鱼和熊掌不可兼得,读写速度越快的存储器也更贵、容量更小。
但冯·诺依曼结构存在一个难以克服的问题,被称为冯·诺依曼瓶颈 —— 在目前的科技水平之下,CPU 与存储器之间的读写速率远远小于 CPU 的工作效率。简单来说就是 CPU 太快了,存储器读写速度不够快,造成了 CPU 性能的浪费。
既然现在我们没办法获得完美的存储器,那我们如何尽量突破冯·诺依曼结构的瓶颈呢?现行的解决方式就是采用多级存储,来平衡存储器的读写速率、容量、价格。
存储器的层次结构
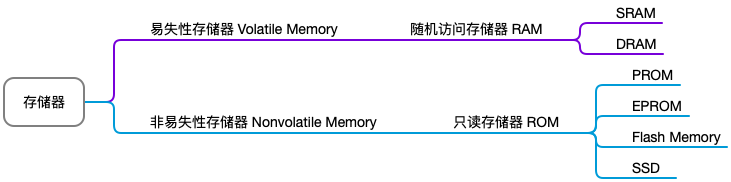
存储器主要分为两类:易失性存储器速度更快,断电之后数据会丢失;非易失性存储器容量更大、价格更低,断电也不会丢失数据。随机访问存储器 RAM 也分为两类,其中 SRAM 速度更快,所以用作高速缓存,DRAM 用作主存。只读存储器 ROM 实际上只有最开始的时候是只读的,后来随着发展也能够进行读写了,只是沿用了之前的名字。
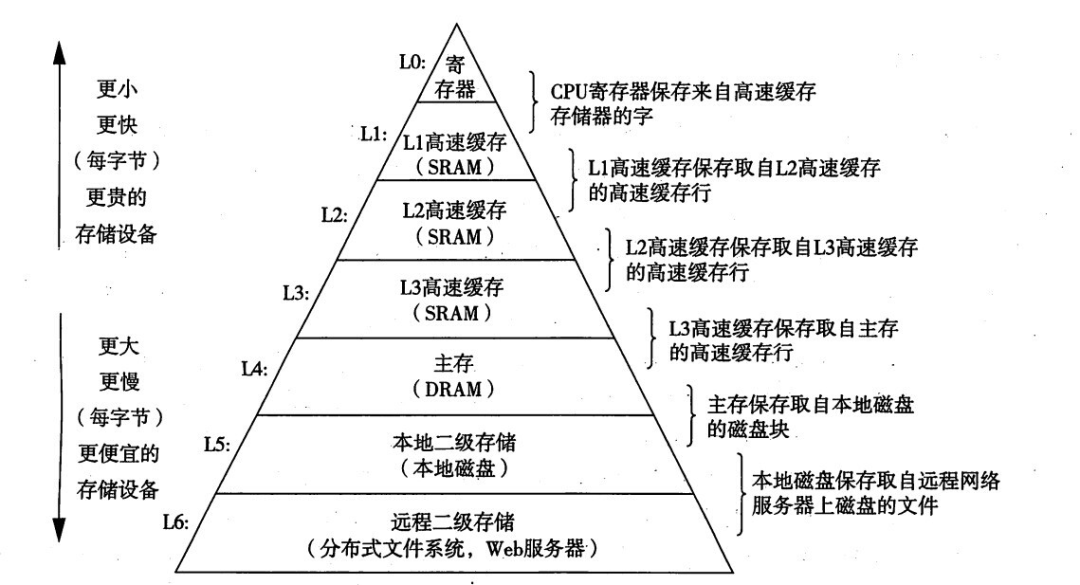
上图就是多层存储器的具体情况,我们平时常说的内存,实际上就是指的 L4 主存。而 L1-L3 高速缓存和主存相比,速度更快,并且它们都已经集成在 CPU 芯片内部了。其中 L0 寄存器本身就是 CPU 的组成部分之一,读写速度最快,操作耗费 0 个时钟周期。
简单来说,存储器的分级实际上就是一种缓存思想。金字塔底部的部分容量大,更便宜,主要是为了发挥其存储属性;而金字塔尖的高速缓存部分读写速度快,负责将高频使用的部分缓存起来,一定程度上优化整体的读写效率。
为什么采用缓存就能够提高效率呢?逻辑上理解起来其实很简单,具体来说就是因为存在局部性原理(Principle of locality) —— 被使用过的存储器内容在未来可能会被多次使用,以及它附近的内容也大概率被使用。当我们把这些内容放在高速缓存中,那么就可以在部分情况下节约访问存储器的时间。
CPU 寻址方式
那么,CPU 是如何访问内存的呢?内存可以被看作一个数组,数组元素是一个字节大小的空间,而数组索引则是所谓的物理地址(Physical Address)。最简单最直接的方式,就是 CPU 直接通过物理地址去访问对应的内存,这样也被叫做物理寻址。
物理寻址后来也扩展支持了分段机制,通过在 CPU 中增加段寄存器,将物理地址变成了 "段地址":"段内偏移量" 的形式,增加了物理寻址的寻址范围。
不过支持了分段机制的物理寻址,仍然有一些问题,最严重的问题之一就是地址空间缺乏保护。简单来说,因为直接暴露的是物理地址,所以进程可以访问到任何物理地址,用户进程想干嘛就干嘛,这是非常危险的。
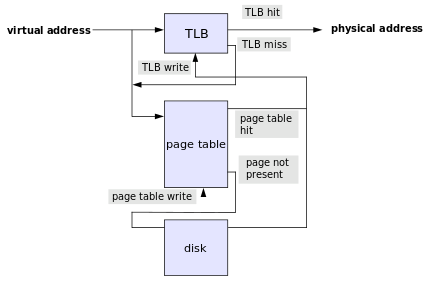
现代处理器使用的是虚拟寻址的方式,CPU 通过访问虚拟地址(Virtual Address),经过翻译获得物理地址,才能访问内存。这个翻译过程由 CPU 中的内存管理单元(Memory Management Unit,缩写为 MMU)完成。
具体流程如上图所示:首先会在 TLB(Translation Lookaside Buffer)中进行查询,它表位于 CPU 内部,查询速度最快;如果没有命中,那么接下来会在页表(Page Table)中进行查询,页表位于物理内存中,所以查询速度较慢;最后如果发现目标页并不在物理内存中,称为缺页,此时会去磁盘中找。当然,如果页表中还找不到,那就是出错了。
翻译过程实际上和前文讲到的存储器分级类似,都体现了缓存思想:TLB 的速度最快,但是容量也最小,之后是页表,最慢的是硬盘。
虚拟内存
刚才提到,直接使用物理寻址,会有地址空间缺乏保护的严重问题。那么如何解决呢?实际上在使用了虚拟寻址之后,由于每次都会进行一个翻译过程,所以可以在翻译中增加一些额外的权限判定,对地址空间进行保护。所以,对于每个进程来说,操作系统可以为其提供一个独立的、私有的、连续的地址空间,这就是所谓的虚拟内存。
虚拟内存最大的意义就是保护了进程的地址空间,使得进程之间不能够越权进行互相地干扰。对于每个进程来说,操作系统通过虚拟内存进行"欺骗",进程只能够操作被分配的虚拟内存的部分。与此同时,进程可见的虚拟内存是一个连续的地址空间,这样也方便了程序员对内存进行管理。
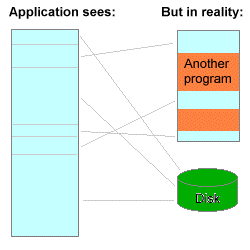
对于进程来说,它的可见部分只有分配给它的虚拟内存,而虚拟内存实际上可能映射到物理内存以及硬盘的任何区域。由于硬盘读写速度并不如内存快,所以操作系统会优先使用物理内存空间,但是当物理内存空间不够时,就会将部分内存数据交换到硬盘上去存储,这就是所谓的 Swap 内存交换机制。有了内存交换机制以后,相比起物理寻址,虚拟内存实际上利用硬盘空间拓展了内存空间。
总结起来,虚拟内存有下面几个意义:保护了每个进程的地址空间、简化了内存管理、利用硬盘空间拓展了内存空间。
内存分页
基于前文的思路,虚拟内存和物理内存建立了映射的关系。为了方便映射和管理,虚拟内存和物理内存都被分割成相同大小的单位,物理内存的最小单位被称为帧(Frame),而虚拟内存的最小单位被称为页(Page)。
注意页和帧大小相同,有着类似函数的映射关系,前文提到的借助 TLB、页表进行的翻译过程,实际上和函数的映射非常类似。
内存分页最大的意义在于,支持了物理内存的离散使用。由于存在映射过程,所以虚拟内存对应的物理内存可以任意存放,这样就方便了操作系统对物理内存的管理,也能够可以最大化利用物理内存。同时,也可以采用一些页面调度(Paging)算法,利用翻译过程中也存在的局部性原理,将大概率被使用的帧地址加入到 TLB 或者页表之中,提高翻译的效率。
2. iOS 的内存机制
根据官方文档 Memory Usage Performance Guidelines(现在已经不更新了)我们能知道 iOS 的内存机制有下面几个特点:
使用虚拟内存
iOS 和大多数桌面操作系统一样,使用了虚拟内存机制。
内存有限,但单应用可用内存大
对于移动设备来说,受限于客观条件,物理内存容量本身就小,而 iPhone 的 RAM 本身也是偏小的,最新的 iPhone XS Max 也才有 4GB,横向对比小米 9 可达 8GB,华为 P30 也是 8GB。根据 List of iPhones 可以查看历代 iPhone 的内存大小。
但是与其他手机不同的是,iOS 系统给每个进程分配的虚拟内存空间非常大。据官方文档的说法,iOS 为每个 32 位的进程都会提供高达 4GB 的可寻址空间,这已经算非常大的了。
没有内存交换机制
虚拟内存远大于物理内存,那如果物理内存不够用了该怎么办呢?之前我们讲到,其他桌面操作系统(比如 OS X)有内存交换机制,在需要时能将物理内存中的一部分内容交换到硬盘上去,利用硬盘空间拓展内存空间,这也是使用虚拟内存带来的优势之一。
然而 iOS 并不支持内存交换机制,大多数移动设备都不支持内存交换机制。移动设备上的大容量存储器通常是闪存(Flash),它的读写速度远远小于电脑所使用的硬盘,这就导致了在移动设备就算使用内存交换机制,也并不能提升性能。其次,移动设备的容量本身就经常短缺、闪存的读写寿命也是有限的,所以这种情况下还拿闪存来做内存交换,就有点太过奢侈了。
需要注意的是,网上有少数文章说 iOS 没有虚拟内存机制,实际上应该指的是 iOS 没有内存交换机制,因为在 Windows 系统下,虚拟内存有时指的是硬盘提供给内存交换的大小。
内存警告
那么当内存不够用时,iOS 的处理是会发出内存警告,告知进程去清理自己的内存。iOS 上一个进程就对应一个 app。代码中的 didReceiveMemoryWarning() 方法就是在内存警告发生时被触发,app 应该去清理一些不必要的内存,来释放一定的空间。
OOM 崩溃
如果 app 在发生了内存警告,并进行了清理之后,物理内存还是不够用了,那么就会发生 OOM 崩溃,也就是 Out of Memory Crash。
在 stack overflow 上,有人对单个 app 能够使用的最大内存做了统计:iOS app max memory budget。以 iPhone XS Max 为例,总共的可用内存是 3735 MB(比硬件大小小一些,因为系统本身也会消耗一部分内存),而单个 app 可用内存达到 2039 MB,达到了 55%。当 app 使用的内存超过这个临界值,就会发生 OOM 崩溃。可以看出,单个 app 的可用物理内存实际上还是很大的,要发生 OOM 崩溃,绝大多数情况下都是程序本身出了问题。
3. iOS 系统内存占用
分析了 iOS 内存机制的特点之后,我们能够意识到合理控制 app 使用的内存是非常重要的一件事。那么具体来说,我们需要减少的是哪些部分呢?实际上这就是所谓的 iOS 内存占用(Memory Footprint)的部分。
上文讲到内存分页,实际上内存页也有分类,一般来说分为 clean memory 和 dirty memory 两种,iOS 中也有 compressed memory 的概念。
Clean memory & dirty memory
对于一般的桌面操作系统,clean memory 可以认为是能够进行 Page Out 的部分。Page Out 指的是将优先级低的内存数据交换到磁盘上的操作,但 iOS 并没有内存交换机制,所以对 iOS 这样的定义是不严谨的。那么对于 iOS 来说,clean memory 指的是能被重新创建的内存,它主要包含下面几类:
app 的二进制可执行文件
framework 中的 _DATA_CONST 段
文件映射的内存
未写入数据的内存
内存映射的文件指的是当 app 访问一个文件时,系统会将文件映射加载到内存中,如果文件只读,那么这部分内存就属于 clean memory。另外需要注意的是,链接的 framework 中 _DATA_CONST 并不绝对属于 clean memory,当 app 使用到 framework 时,就会变成 dirty memory。
未写入数据的内存也属于 clean memory,比如下面这段代码,只有写入了的部分才属于 dirty memory。
int *array = malloc(20000 * sizeof(int));
array[0] = 32
array[19999] = 64

所有不属于 clean memory 的内存都是 dirty memory。这部分内存并不能被系统重新创建,所以 dirty memory 会始终占据物理内存,直到物理内存不够用之后,系统便会开始清理。
Compressed memory
当物理内存不够用时,iOS 会将部分物理内存压缩,在需要读写时再解压,以达到节约内存的目的。而压缩之后的内存,就是所谓的 compressed memory。苹果最开始只是在 OS X 上使用这项技术,后来也在 iOS 系统上使用。
实际上,随着虚拟内存技术的发展,很多桌面操作系统早已经应用了内存压缩技术,比如 Windows 中的 memory combining 技术。这本质上来说和内存交换机制类似,都是是一种用 CPU 时间换内存空间的方式,只不过内存压缩技术消耗的时间更少,但占用 CPU 更高。不过在文章最开始,我们就已经谈到由于 CPU 算力过剩,在大多数场景下,物理内存的空间相比起 CPU 算力来说显然更为重要,所以内存压缩技术非常有用。
根据 OS X Mavericks Core Technology Overview 官方文档来看,使用 compressed memory 能在内存紧张时,将目标内存压缩至原有的一半以下,同时压缩和解压消耗的时间都非常小。对于 OS X,compressed memory 也能和内存交换技术共用,提高内存交换的效率,毕竟压缩后再进行交换效率明显更高,只是 iOS 没有内存交换,也就不存在这方面的好处了。
本质上来讲,compressed memory 也属于 dirty memory。
内存占用组成
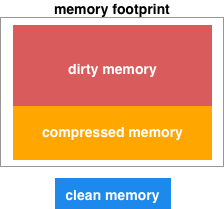
对于 app 来说,我们主要关心的内存是 dirty memory,当然其中也包含 compressed memory。而对于 clean memory,作为开发者通常可以不必关心。
当内存占用的部分过大,就会发生前文所说的内存警告以及 OOM 崩溃等情况,所以我们应该尽可能的减少内存占用,并对内存警告以及 OOM 崩溃做好防范。减少内存占用也能侧面提升启动速度,要加载的内存少了,自然启动速度会变快。
按照正常的思路,app 监听到内存警告时应该主动清理释放掉一些优先级低的内存,这本质上是没错的。不过由于 compressed memory 的特殊性,所以导致内存占用的实际大小考虑起来会有些复杂。
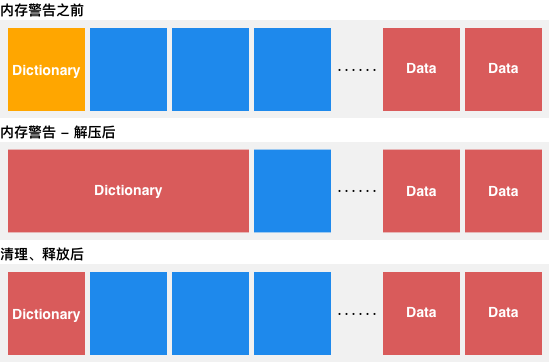
比如上面这种情况,当我们收到内存警告时,我们尝试将 Dictionary 中的部分内容释放掉,但由于之前的 Dictionary 由于未使用,所以正处于被压缩状态;而解压、释放部分内容之后,Dictionary 处于未压缩状态,可能并没有减少物理内存,甚至可能反而让物理内存更大了。
所以,进行缓存更推荐使用 NSCache 而不是 NSDictionary,就是因为 NSCache 不仅线程安全,而且对存在 compressed memory 情况下的内存警告也做了优化,可以由系统自动释放内存。
4. iOS app 内存管理
前文讲了 iOS 系统层面上的内存机制,在系统层面上的内存管理大多数情况下都已经由操作系统自动完成了。iOS 中一个 app 就是一个进程,所以开发者平时经常讨论的内存管理,比如 MRC、ARC 等等,实际上属于进程内部的内存管理,或者说是语言层面上的内存管理。这部分内存管理语言本身、操作系统均会有一些管理策略,但是作为开发者来说,很多时候还是需要从语言层面直接进行操作的。
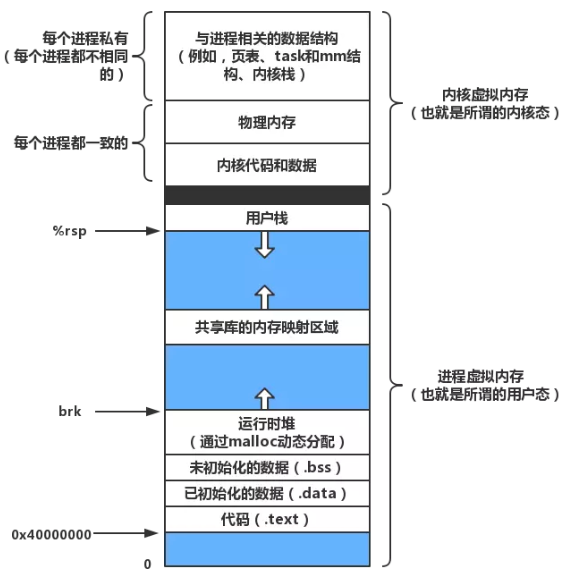
iOS app 地址空间
前文我们说过,每个进程都有独立的虚拟内存地址空间,也就是所谓的进程地址空间。现在我们稍微简化一下,一个 iOS app 对应的进程地址空间大概如下图所示:
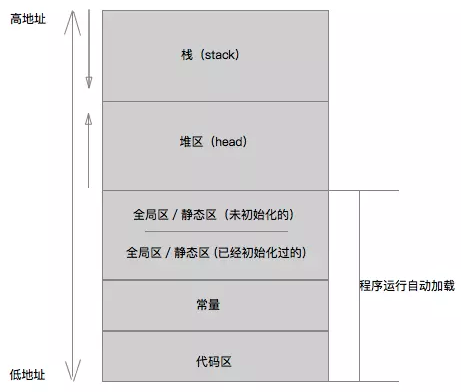
每个区域实际上都存储相应的内容,其中代码区、常量区、静态区这三个区域都是自动加载,并且在进程结束之后被系统释放,开发者并不需要进行关注。
栈区一般存放局部变量、临时变量,由编译器自动分配和释放,每个线程运行时都对应一个栈。而堆区用于动态内存的申请,由程序员分配和释放。一般来说,栈区由于被系统自动管理,速度更快,但是使用起来并不如堆区灵活。
对于 Swift 来说,值类型存于栈区,引用类型存于堆区。值类型典型的有 struct、enum 以及 tuple 都是值类型。而比如 Int、Double、Array,Dictionary 等其实都是用结构体实现的,也是值类型。而 class、closure 都是引用类型,也就是说 Swift 中我们如果遇到类和闭包,就要留个心眼,考虑一下他们的引用情况。
引用计数
堆区需要程序员进行管理,如何管理、记录、回收就是一个很值得思考的问题。iOS 采用的是引用计数(Reference Counting)的方式,将资源被引用的次数保存起来,当被引用次数变为零时就将其空间释放回收。
对于早期 iOS 来说,使用的是 MRC(Mannul Reference Counting)手动管理引用计数,通过插入 retain、release 等方法来管理对象的生命周期。但由于 MRC 维护起来实在是太麻烦了,2011 年的 WWDC 大会上提出了 ARC(Automatic Reference Counting)自动管理引用计数,通过编译器的静态分析,自动插入引入计数的管理逻辑,从而避免繁杂的手动管理。
引用计数只是垃圾回收中的一种,除此之外还有标记-清除算法(Mark Sweep GC)、可达性算法(Tracing GC)等。相比之下,引用计数由于只记录了对象的被引用次数,实际上只是一个局部的信息,而缺乏全局信息,因此可能产生循环引用的问题,于是在代码层面就需要格外注意。
那么为什么 iOS 还要采用引用计数呢?首先使用引用计数,对象生命周期结束时,可以立刻被回收,而不需要等到全局遍历之后再回首。其次,在内存不充裕的情况下,tracing GC 算法的延迟更大,效率反而更低,由于 iPhone 整体内存偏小,所以引用计数算是一种更为合理的选择。
循环引用
内存泄漏指的是没能释放不能使用的内存,会浪费大量内存,很可能导致应用崩溃。ARC 可能导致的循环引用就是其中一种,并且也是 iOS 上最常发生的。什么情况下会发生循环引用,大家可能都比较熟悉了,swift 中比较典型的是在使用闭包的时候:
class viewController: UIViewController {
var a = 10
var b = 20
var someClosure: (() -> Int)?
func anotherFunction(closure: @escaping () -> Int) {
DispatchQueue.main.asyncAfter(deadline: .now() + .seconds(5)) {
print(closure)
}
}
override func viewDidLoad() {
super.viewDidLoad()
someClosure = {
return self.a + self.b
}
anotherFunction(closure: someClosure!)
}
}
上面这段代码中,viewController 会持有 someClosure,而 someClosure 也因为需要使用 self.a + self.b 而持有了 viewController,这就导致了循环引用。注意,闭包和类相似,都是引用类型,当把闭包赋值给类的属性时,实际上是把闭包的引用赋值给了这个属性。

解决方法也很简单,利用 Swift 提供的闭包捕获列表,将循环引用中的一个强引用关系改为弱引用就好了。实际上,Swift 要求在闭包中使用到了 self 的成员都必须不能省略 self. 的关键词,就是为了提醒这种情况下可能发生循环引用问题。
someClosure = { [weak self] in
guard let self = self else { return 0 }
return self.a + self.b
}
weak 和 unowned
weak 关键字能将循环引用中的一个强引用替换为弱引用,以此来破解循环引用。而还有另一个关键字 unowned,通过将强引用替换为无主引用,也能破解循环引用,不过二者有什么区别呢?弱引用对象可以为 nil,而无主引用对象不能,会发生运行时错误。
比如上面的例子我们使用了 weak,那么就需要额外使用 guard let 进行一步解包。而如果使用 unowned,就可以省略解包的一步:
someClosure = { [unowned self] in
return self.a + self.b
}
weak 在底层添加了附加层,间接地把 unowned 引用包裹到了一个可选容器里面,虽然这样做会更加清晰,但是在性能方面带来了一些影响,所以 unowned 会更快一些。
但是无主引用有可能导致 crash,就是无主引用的对象为 nil 时,比如上面这个例子中,anotherFunction 我们会延迟 5s 调用 someClosure,但是如果 5s 内我们已经 pop 了这个 viewController,那么 unowned self 在调用时就会发现 self 已经被释放了,此时就会发生崩溃。
Fatal error: Attempted to read an unowned reference but the object was already deallocated
如果简单类比,使用 weak 的引用对象就类似于一个可选类型,使用时需要考虑解包;而使用 unowned 的引用对象就类似于已经进行强制解包了,不需要再解包,但是如果对象是 nil,那么就会直接 crash。
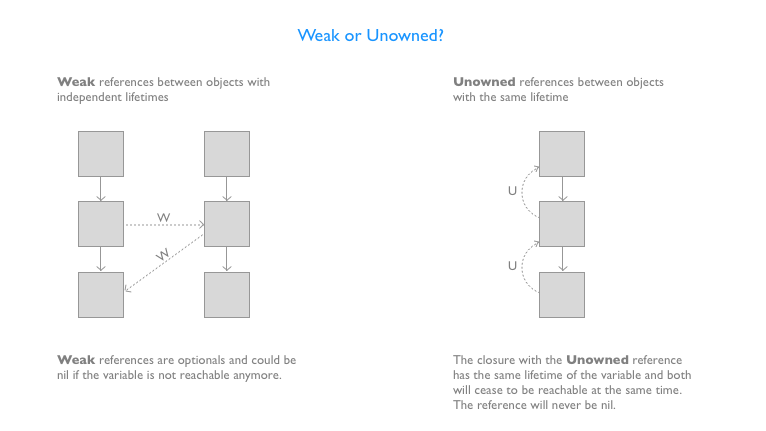
到底什么情况下可以使用 unowned 呢?根据官方文档 Automatic Reference Counting 所说,无主引用在其他实例有相同或者更长的生命周期时使用。
Unlike a weak reference, however, an unowned reference is used when the other instance has the same lifetime or a longer lifetime.
一种情况,如果两个互相持有的对象,一个可能为 nil 而另一个不会为 nil,那么就可以使用 unowned。比如官方文档中的这个例子,每张信用卡必然有它的主人,CreditCard 必然对应一个 Customer,所以这里使用了 unowned:
class Customer {
let name: String
var card: CreditCard?
init(name: String) {
self.name = name
}
deinit { print("\(name) is being deinitialized") }
}
class CreditCard {
let number: UInt64
unowned let customer: Customer
init(number: UInt64, customer: Customer) {
self.number = number
self.customer = customer
}
deinit { print("Card #\(number) is being deinitialized") }
}
而另一种情况,对于闭包,在闭包和捕获的实例总是相互引用并且同时销毁时,可以将闭包的捕获定义为 unowned。如果被捕获的引用绝对不会变为 nil,应该使用 unowned,而不是 weak。
If the captured reference will never become
nil, it should always be captured as an unowned reference, rather than a weak reference.
比如下面这个例子中的闭包,首先 asHTML 被声明为 lazy,那么一定是 self 先被初始化;同时内部也没有使用 asHTML 属性,所以 self 一旦被销毁,闭包也不存在了。这种情况下就应该使用 unowned:
class HTMLElement {
let name: String
let text: String?
lazy var asHTML: () -> String = {
[unowned self] in
if let text = self.text {
return "<\(self.name)>\(text)</\(self.name)>"
} else {
return "<\(self.name) />"
}
}
init(name: String, text: String? = nil) {
self.name = name
self.text = text
}
}
总的来说,最关键的点在于 weak 比 unowned 更加安全,能够避免意外的 crash,这对于工程来说是非常有益的。所以大多数时候,就像我们通过 if let 以及 guard let 来避免使用 ! 强制解析一样,我们也通常直接使用 weak。
不会导致循环引用的情形
由于闭包经常产生循环引用的问题,而且加上 weak 以及 guard let 之后也不会出现错误,所以很多时候我们遇到闭包就直接无脑使用 weak,这实际上就太过粗糙了。
比如,如果在 viewController 中使用了类似下面的闭包,就不会发生循环引用,因为 DispatchQueue 并不会被持有:
DispatchQueue.main.asyncAfter(deadline: .now() + 2) {
self.execute()
}
更典型的比如使用 static functions 的时候:
class APIClass {
// static 函数
static func getData(params: String, completion:@escaping (String) -> Void) {
request(method: .get, parameters: params) { (response) in
completion(response)
}
}
}
class viewController {
var params = "something"
var value = ""
override func viewDidLoad() {
super.viewDidLoad()
getData(params: self.params) { (value) in
self.value = value
}
}
}
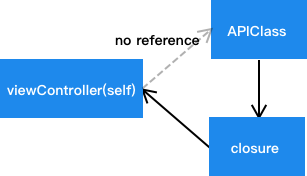
此时并不会产生循环引用,因为 self 并不会持有 static class,因此也不会产生内存泄漏:
5. OOM 崩溃
Jetsam 机制
iOS 是一个从 BSD 衍生而来的系统,其内核是 Mach。其中内存警告,以及 OOM 崩溃的处理机制就是 Jetsam 机制,也被称为 Memorystatus。Jetsam 会始终监控内存整体使用情况,当内存不足时会根据优先级、内存占用大小杀掉一些进程,并记录成 JetsamEvent。
根据 apple 开源的内核代码 apple/darwin-xnu,我们可以看到,Jetsam 维护了一个优先级队列,具体的优先级内容可以在 bsd/kern/kern_memorystatus.c 文件中找到:
static const char *
memorystatus_priority_band_name(int32_t priority)
{
switch (priority) {
case JETSAM_PRIORITY_FOREGROUND:
return "FOREGROUND";
case JETSAM_PRIORITY_AUDIO_AND_ACCESSORY:
return "AUDIO_AND_ACCESSORY";
case JETSAM_PRIORITY_CONDUCTOR:
return "CONDUCTOR";
case JETSAM_PRIORITY_HOME:
return "HOME";
case JETSAM_PRIORITY_EXECUTIVE:
return "EXECUTIVE";
case JETSAM_PRIORITY_IMPORTANT:
return "IMPORTANT";
case JETSAM_PRIORITY_CRITICAL:
return "CRITICAL";
}
return ("?");
}
而如何监控内存警告,以及处理 Jetsam 事件呢?首先,内核会调起一个内核优先级最高(95 /* MAXPRI_KERNEL */ 已经是内核能给线程分配的最高优先级了)的线程:
// 同样在 bsd/kern/kern_memorystatus.c 文件中
result = kernel_thread_start_priority(memorystatus_thread, NULL, 95 /* MAXPRI_KERNEL */, &jetsam_threads[i].thread);
这个线程会维护两个列表,一个是基于优先级的进程列表,另一个是每个进程消耗的内存页的列表。与此同时,它会监听内核 pageout 线程对整体内存使用情况的通知,在内存告急时向每个进程转发内存警告,也就是触发 didReceiveMemoryWarning 方法。
而杀掉应用,触发 OOM,主要是通过 memorystatus_kill_on_VM_page_shortage,有同步和异步两种方式。同步方式会立刻杀掉进程,先根据优先级,杀掉优先级低的进程;同一优先级再根据内存大小,杀掉内存占用大的进程。而异步方式只会标记当前进程,通过专门的内存管理线程去杀死。
如何检测 OOM
OOM 分为两大类,Foreground OOM / Background OOM,简写为 FOOM 以及 BOOM。而其中 FOOM 是指 app 在前台时由于消耗内存过大,而被系统杀死,直接表现为 crash。
而 Facebook 开源的 FBAllocationTracker,原理是 hook 了 malloc/free 等方法,以此在运行时记录所有实例的分配信息,从而发现一些实例的内存异常情况,有点类似于在 app 内运行、性能更好的 Allocation。但是这个库只能监控 Objective-C 对象,所以局限性非常大,同时因为没办法拿到对象的堆栈信息,所以更难定位 OOM 的具体原因。
而腾讯开源的 OOMDetector,通过 malloc/free 的更底层接口 malloc_logger_t 记录当前存活对象的内存分配信息,同时也根据系统的 backtrace_symbols 回溯了堆栈信息。之后再根据伸展树(Splay Tree)等做数据存储分析,具体方式参看这篇文章:iOS微信内存监控。
OOM 常见原因
内存泄漏
最常见的原因之一就是内存泄漏。
UIWebview 缺陷
无论是打开网页,还是执行一段简单的 js 代码,UIWebView 都会占用大量内存,同时旧版本的 css 动画也会导致大量问题,所以最好使用 WKWebView。
大图片、大视图
缩放、绘制分辨率高的大图片,播放 gif 图,以及渲染本身 size 过大的视图(例如超长的 TextView)等,都会占用大量内存,轻则造成卡顿,重则可能在解析、渲染的过程中发生 OOM。
6. 内存分析
关于内存占用情况、内存泄漏,我们都有一系列方法进行分析检测。
Xcode memory gauge:在 Xcode 的 Debug navigator 中,可以粗略查看内存占用的情况。
Instrument - Allocations:可以查看虚拟内存占用、堆信息、对象信息、调用栈信息,VM Regions 信息等。可以利用这个工具分析内存,并针对地进行优化。
Instrument - Leaks:用于检测内存泄漏。
MLeaksFinder:通过判断UIViewController被销毁后其子view是否也都被销毁,可以在不入侵代码的情况下检测内存泄漏。
Instrument - VM Tracker:可以查看内存占用信息,查看各类型内存的占用情况,比如 dirty memory 的大小等等,可以辅助分析内存过大、内存泄漏等原因。
Instrument - Virtual Memory Trace:有内存分页的具体信息,具体可以参考 WWDC 2016 - Syetem Trace in Depth。
Memory Resource Exceptions:从 Xcode 10 开始,内存占用过大时,调试器能捕获到EXC_RESOURCE RESOURCE_TYPE_MEMORY异常,并断点在触发异常抛出的地方。
Xcode Memory Debugger:Xcode 中可以直接查看所有对象间的相互依赖关系,可以非常方便的查找循环引用的问题。同时,还可以将这些信息导出为 memgraph 文件。
memgraph + 命令行指令:结合上一步输出的 memgraph 文件,可以通过一些指令来分析内存情况。vmmap可以打印出进程信息,以及 VMRegions 的信息等,结合grep可以查看指定 VMRegion 的信息。leaks可追踪堆中的对象,从而查看内存泄漏、堆栈信息等。heap会打印出堆中所有信息,方便追踪内存占用较大的对象。malloc_history可以查看heap指令得到的对象的堆栈信息,从而方便地发现问题。总结:malloc_history===> Creation;leaks===> Reference;heap&vmmap===> Size。
7. 自测题目
一般来说做点题才能加深理解和巩固,所以这里从文章里简单提炼了一些,希望能帮到大家:
什么是冯·诺依曼结构?
什么是冯·诺依曼结构的瓶颈,以及如何突破瓶颈?
存储器分哪两类,分别有什么特点?
为什么使用缓存能提高效率?
什么是物理寻址?什么是虚拟寻址?
虚拟地址翻译过程由谁负责?具体流程是怎样的?
虚拟内存有哪些意义?
什么是内存交换机制?
内存分页有什么意义?
iOS 的内存机制有什么特点?
clean memory、dirty memory、compressed memory 分别是什么?
引起循环引用的本质原因是什么?
weak 和 unowned 的区别是什么?
列举一些不会导致循环引用的闭包场景。
什么是 OOM 崩溃?
检测 OOM 崩溃有哪些常见方法?
OOM 崩溃有哪些常见原因?
参考资料
什么是内存 - eleven_yw
机器之心 - 冯诺依曼结构
虚拟内存那点事 - SylvanasSun
stack overflow - Why don't most Android devices have swap area as typical OS does?
stack overflow - What is resident and dirty memory of iOS?
OS X Mavericks 中的内存压缩技术到底有多强大?- rlei的回答 - 知乎
WWDC 2018:iOS 内存深入研究
WWDC 2018 - 深入解析 iOS 内存 iOS Memory Deep Dive
垃圾回收机制中,引用计数法是如何维护所有对象引用的?- RednaxelaFX的回答 - 知乎
垃圾回收算法:引用计数法 - good speed
All About Memory Leaks in iOS
Unowned or Weak? Lifetime and Performance
How Swift Implements Unowned and Weak References
《The Swift Programming Language》in Chinese - Swift GG
iOS内存abort(Jetsam) 原理探究
OOM探究:XNU 内存状态管理
iOS微信内存监控
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击👆卡片,关注后回复【
面试题】即可获取