
一文看懂AMD的Zen 3内核芯片



Ryzen 5000 Chiplet布局

Zen 2 vs Zen 3 的CCX安排

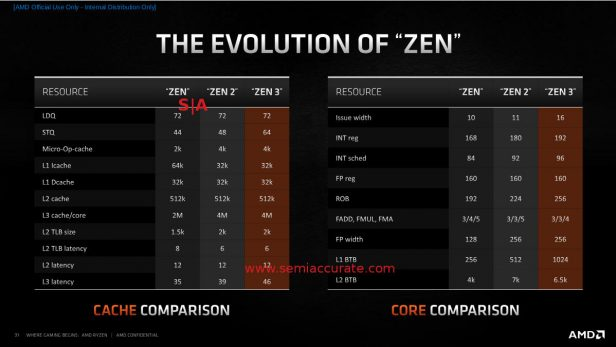
Zen 3的缓存层次结构
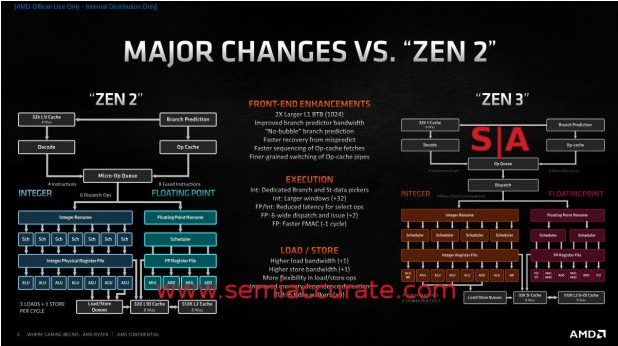
Zen 2 vs Zen 3框图
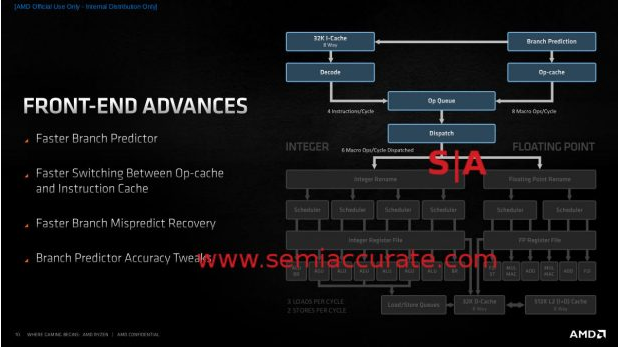
Zen 3前端概述
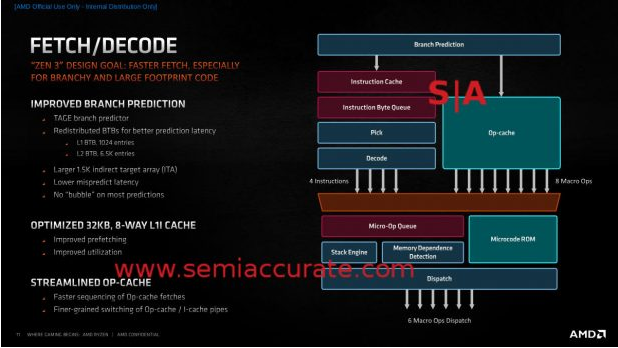
Zen 3的提取/解码单元
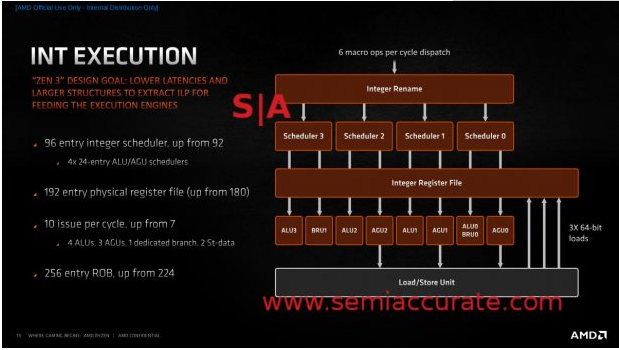
Zen 3的整数单元
FP单元版本 3.000000:

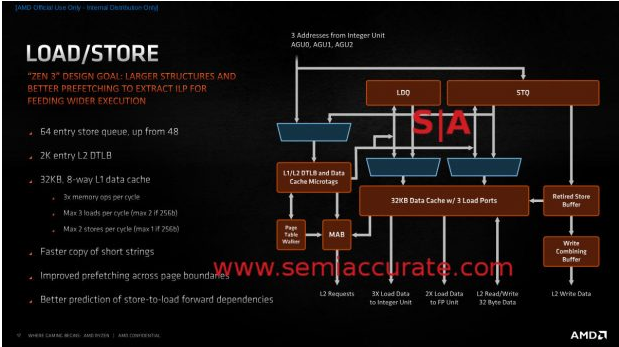
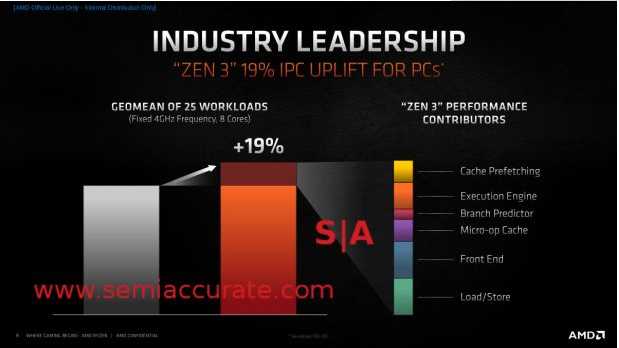

来源:半导体行业观察
原文:
https://semiaccurate.com/2020/11/07/a-long-look-at-amds-zen-3-core-and-chips/
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师技术全联盟书店”相关电子书(35本技术资料打包汇总详情可通过“阅读原文”获取)。
内容持续更新,现下单“架构师技术全店打包汇总(全)”,后续可享全店内容更新“免费”赠阅,格仅收188元(原总价270元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。

评论